매니코어 플랫폼 기반 머신러닝 응용 성능 최적화
매니코어 플랫폼 기반 머신러닝 응용 성능 최적화
배경
최근 머신러닝 알고리즘 중 주목받고 있는 similarity search 알고리즘은 추천 시스템, 연관 검색어 추천, 유사한 단어/이미지/문서 추출 등에 널리 쓰이고 있는 알고리즘이다. 그만큼 활발히 다양한 연구가 이루어지고 있고 다양한 similarity search 알고리즘들이 존재한다. 기존의 similarity search 알고리즘들의 한계점을 분석하고 그것을 극복하는 새로운 알고리즘(StarChart)를 제시하여 latency를 줄이로 throughput과 energy efficiency를 높였다.
실험 환경
-
CPU 기반 매니코어 플랫폼
Intel Xeon Scalable Processor 9290M (56-core, 코어 당 2 HyperThreading)를 대상으로 하였다.
-
State-of-the-art similarity search
새롭게 제시한 StarChart와 비교하기 위하여 graph-based의 state-of-the-art 알고리즘 2가지를 선정하였다.
-
데이터셋
데이터셋은 2014년도 stanford에서 제작된 Glove라는 오픈 데이터셋을 이용하였다. Glove dataset은 각 단어 사이의 관계를 고려하여 각각을 Vector space에서 나타낸 것입이다. 따라서 이 Word vector들은 다양한 similarity metrics, Cosine similarity나 Inner product, euclidean distance 등에 대해서 해당 단어의 언어적 또는 의미적 유사성을 측정하는 효과적인 방법을 제공한다. 예를 들어 이 glove dataset에서 개구리에 해당하는 vector를 기준으로 similarity metric을 사용해 비슷한 벡터들을 찾으면 이와 같이 개구리에 유사한 단어들을 쉽게 찾아볼 수 있고, 평소에 잘 사용하지 않는 단어들이라도 연관된 단어들을 모두 찾아낼 수 있다. 이 데이터 셋의 크기는 2M이고 각 vector는 300 dimension을 갖고 있다.
분석 내용
- 기존 알고리즘들의 높은 차원의 데이터셋에 대한 한계점 분석
- 높은 차원의 데이터셋에 효율적인 새로운 알고리즘(StarChart)제시
- 대규모 쿼리의 효율적인 처리를 위한 StarChart 병렬화
성능 측정 결과
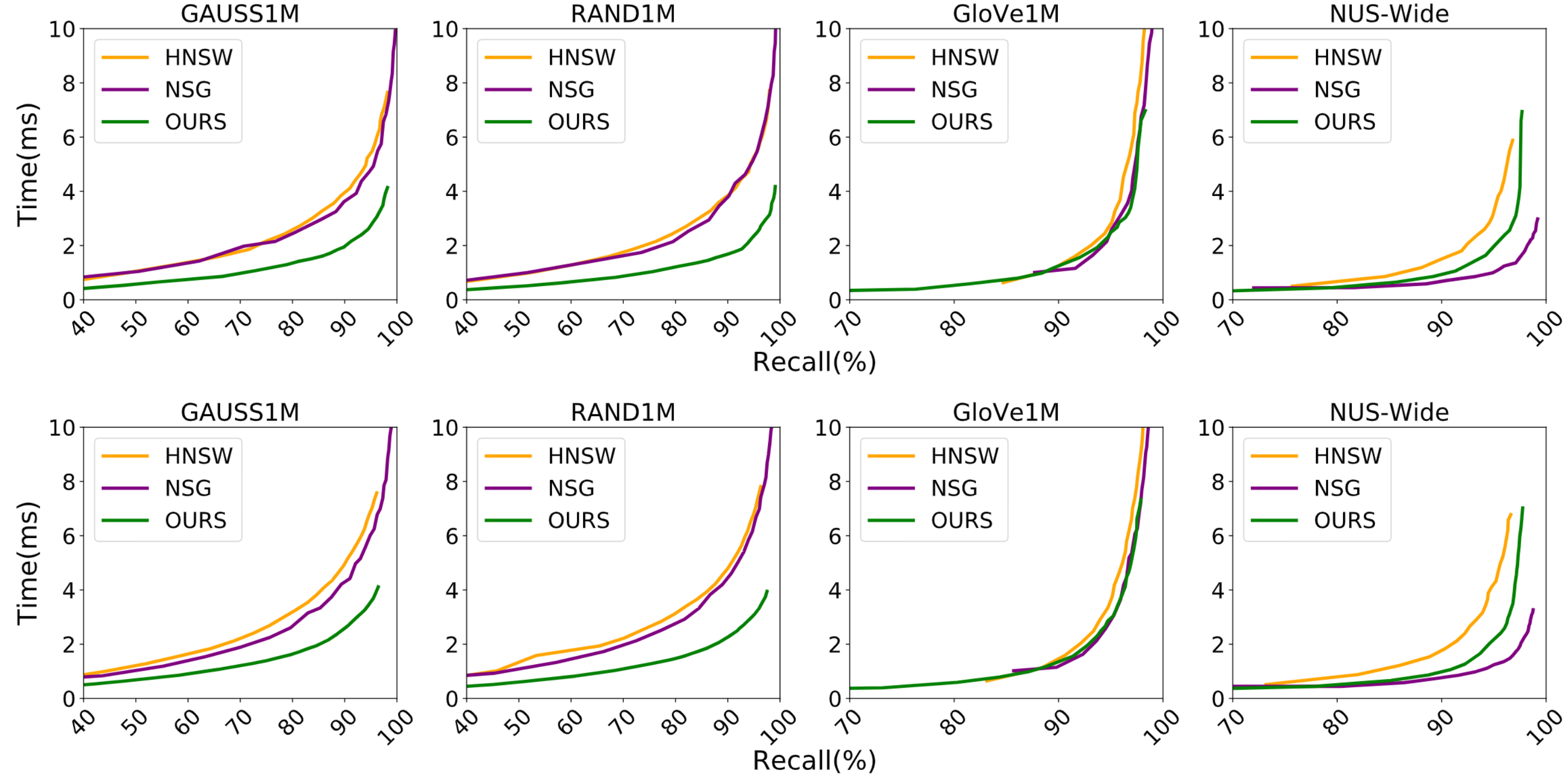
위의 그래프는 StarChart와 기존의 state-of-the-art 그래프 기반 알고리즘과의 비교 결과이다. StarChart가 기존 알고리즘들에 비해 동일한 recall을 달성하는데 더 적은 시간이 걸리는 것을 확인하였고 이를 통해 StarChart의 효율성을 입증하였다.
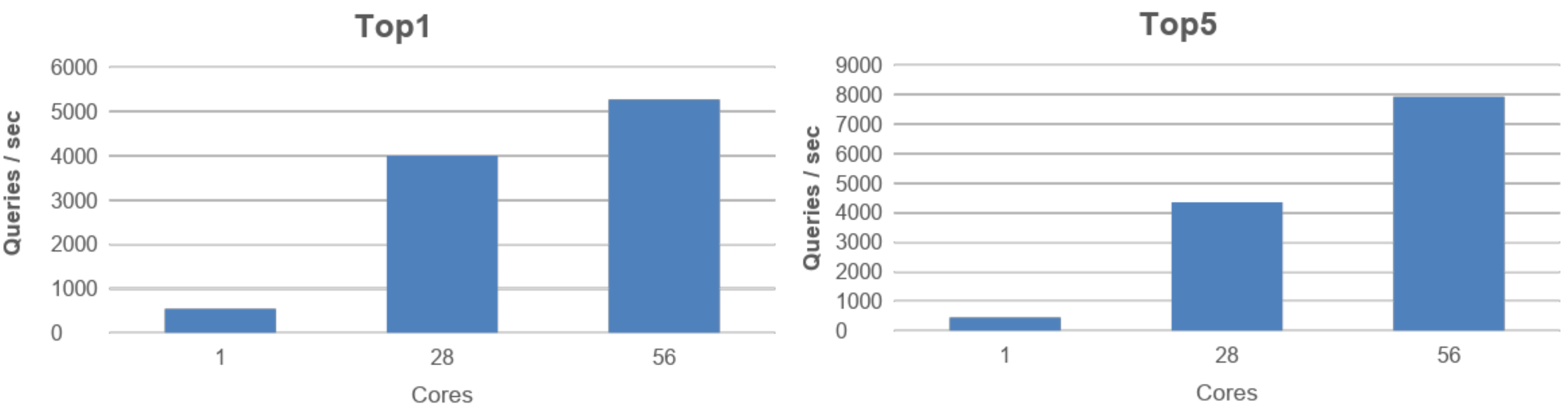
StarChart의 inter-query 병렬화 방법에 대한 결과이다. 코어 개수가 늘어남에 따라 초당 처리가능한 쿼리의 개수가 증가하는 것을 통해 병렬화의 효과를 확인하였다.
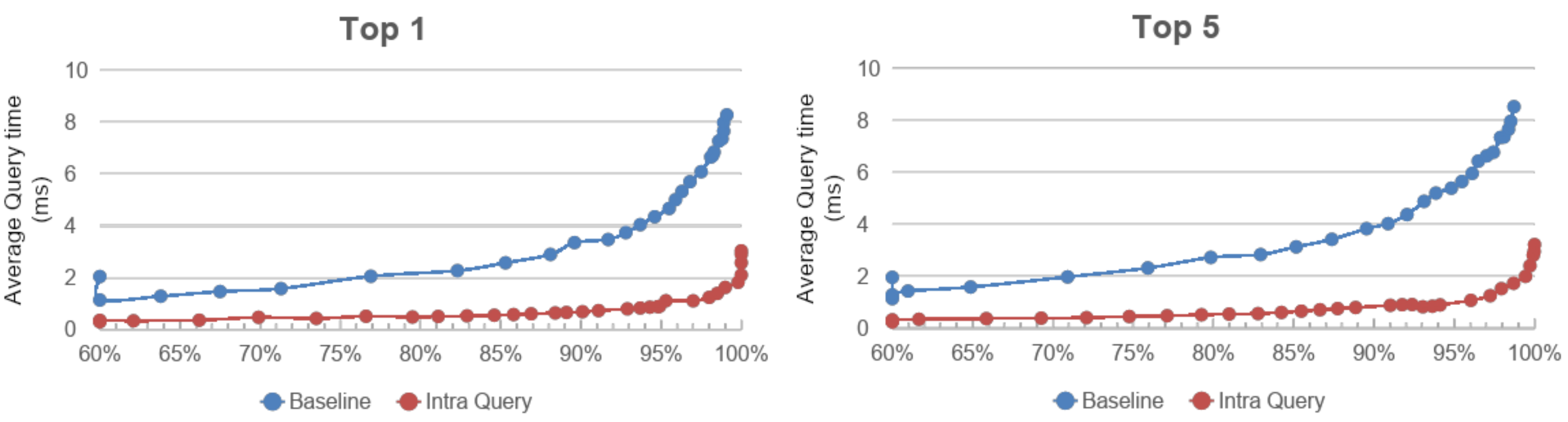
StarChart의 intra-query 병렬화 방법에 대한 결과이다. 여러 코어를 하나의 쿼리를 처리하는데 사용하였을 때 하나의 코어가 하나의 쿼리를 처리할 때 보다 query latency가 훨씬 줄어든 것을 확인할 수 있었다.
쿼리 지연 및 처리량 개선을 위한 매니코어 플랫폼 기반 병렬화 연구
배경
Similarity search는 실제 검색 엔진이나 추천시스템에 사용되는 경우가 많다. 그런데 최근 컨텐츠가 계속 증가하면서 점점 데이터셋의 크기도 커지고 많은 정보를 담기 위해 벡터의 차원도 늘어나고 있다. 이와 더불어 최근 온라인 사용자도 증가하고 있는 추세이기 때문에 실제 환경에서는 다수의 사용자가 동시에 수십 또는 수백 만개의 쿼리를 동시에 입력하게 된다. 따라서 이러한 real-world 시스템에서 대량의 쿼리를 빠르게 처리하기 위하여 similarity search 알고리즘의 병렬화가 필요하다. 따라서 매니코어 플랫폼에서 StarChart의 병렬화 방법 두가지를 (inter-query, intra-query 병렬화) 제시하였다. OpenMP를 이용하여 간단히 구현하여 성능 분석을 진행하였고, 병렬화 방법의 2가지 최적화 포인트를 분석하여 최적화를 진행하여 성능 향상할 수 있는 방법을 소개한다.
연구 내용
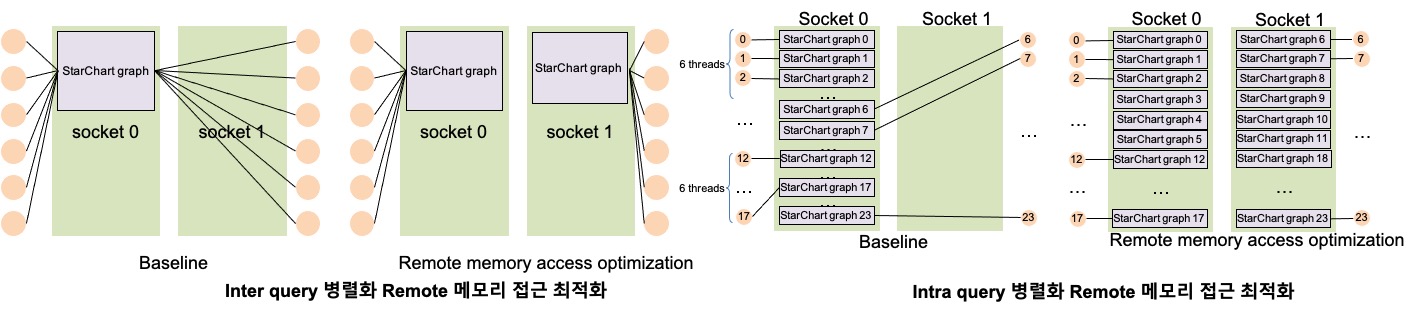
두 병렬화 기법에 공통적으로 의심이 되었던 두가지 문제점이 존재한다. 1) OpenMP를 이용하여 병렬화를 구현할 때, 병렬화 수행 시작 전에 쓰레드를 생성하는 시간이 포함되게 된다. 따라서 이러한 쓰레드 생성 시간을 제거하여 성능 향상이 가능하다. 2) 2소켓 이상을 쓰는 쓰레드 개수에서는 다른 소켓 쪽 메모리에 접근하는 remote메모리 접근이 발생하게 된다. 이러한 remote 메모리 접근은 local 메모리 접근보다 latency가 길기 때문에 remote 메모리 접근을 제거하여 성능을 향상시킬 수 있다.
1) 쓰레드 생성 시간 최적화: 쓰레드 생성 시간 최적화를 위해서 C++ thread를 이용해서 미리 쓰레드를 생성해놓고 미리 생성된 쓰레드를 사용하여 병렬화를 처리하게 하였다. 따라서 병렬화 수행 시간에 쓰레드 생성 시간이 제외되어 최적화를 진행할 수 있다.
2) Remote 메모리 접근 최적화: Remote 메모리 접근은 socket이 2개 이상인 환경에서 현재 쓰레드가 위치하고 있는 socket쪽의 메모리가 아닌 다른 socket쪽의 메모리를 접근하는 것을 의미한다. Remote 메모리 접근은 local 메모리 접근에 비해 latency가 길기 때문에 병렬 프로그래밍에서 쓰레드 수가 늘어날수록 이 remote 메모리 접근에 의한 속도 저하가 흔히 일어나게 된다. 따라서 이러한 부분을 최적화 하기 위해서 쓰레드 별로 접근하는 그래프를 local 메모리에 배치하여 다른 소켓쪽의 메모리를 접근하지 않도록 하였다.
실험 환경
-
CPU 기반 매니코어 플랫폼
Intel Xeon Scalable Processor 9290M (56-core, 코어 당 2 HyperThreading)를 대상으로 하였다.
-
데이터셋
데이터셋은 2014년도 stanford에서 제작된 Glove라는 오픈 데이터셋을 이용하였다. Glove dataset은 각 단어 사이의 관계를 고려하여 각각을 Vector space에서 나타낸 것입이다. 따라서 이 Word vector들은 다양한 similarity metrics, Cosine similarity나 Inner product, euclidean distance 등에 대해서 해당 단어의 언어적 또는 의미적 유사성을 측정하는 효과적인 방법을 제공한다. 예를 들어 이 glove dataset에서 개구리에 해당하는 vector를 기준으로 similarity metric을 사용해 비슷한 벡터들을 찾으면 이와 같이 개구리에 유사한 단어들을 쉽게 찾아볼 수 있고, 평소에 잘 사용하지 않는 단어들이라도 연관된 단어들을 모두 찾아낼 수 있다. 이 데이터 셋의 크기는 2M이고 각 vector는 300 dimension을 갖고 있다.
분석 내용
기존 OpenMP 라이브러리를 이용하여 구현한 병렬화 방법의 scalability 문제 분석 각 최적화 방법의 효과성 분석
성능 측정 결과

Inter-query 병렬화 방법의 경우 single thread 대비 두가지 최적화를 모두 적용한 56 thread에서 26.76배의 수행 시간 향상이 있었다.

Intra-query 병렬화 방법의 경우 single thread 대비 두가지 최적화를 모두 적용한 56 thread에서 21.23배의 수행 시간 향상이 있었다.
매니코어 플랫폼 기반 병렬 프로세싱 프레임워크의 최적화 및 고도화 연구
배경
최근 큰 데이터센터는 다량의 매니코어 CPU 서버들로 구성되어 있다. 쿼리량이 상당히 많은 낮시간대에는 이러한 CPU들을 많이 사용하여 utilization이 높지만, 쿼리량이 많지 않은 밤시간대에는 데이터센터에 있는 일부 CPU들만 쿼리 처리에 사용되고 나머지 CPU들은 idle인 상태로 있어서 utilization이 낮은 문제점이 있다. 따라서 이렇게 쿼리량이 많지 않은 시나리오에서 cpu utilization을 높일 수 있는 방법을 소개한다.
연구 내용
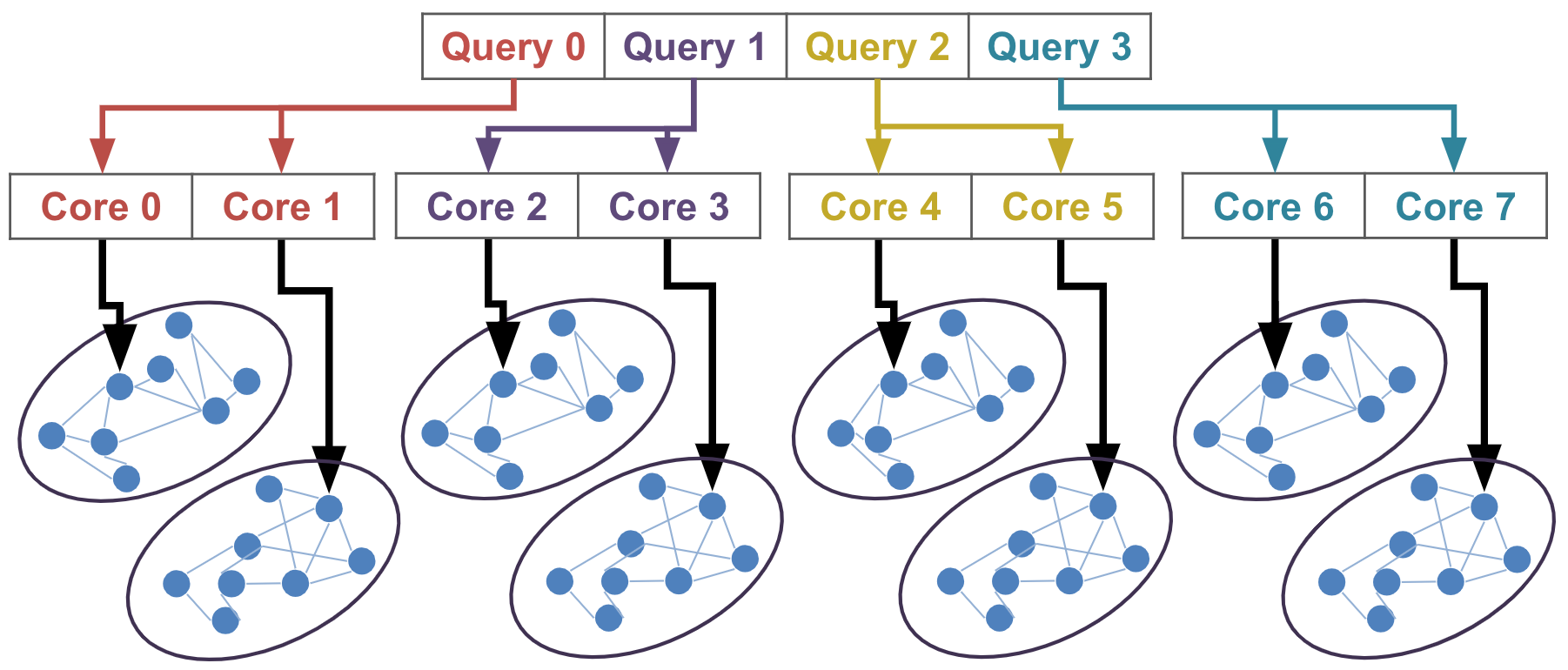
CPU utilization 향상을 위해 intra-query 병렬화 방법과 inter-query 병렬화 방법을 통합하는 것을 제안한다. 예를들어 core가 8개, 쿼리가 4개 들어온 상황에서 inter-query 병렬화 방법을 적용하였다면 쿼리 하나당 core 한개가 매핑되어 병렬적으로 처리된다. 이때 나머지 core 4개는 idle한 상태가 되어 utilization이 50%가 된다. 반면, 위의 그림처럼 하나의 쿼리에 idle한 core 하나를 추가로 매핑하여 쿼리 한개에 코어 2개가 매핑되어 처리할 경우 8개의 core가 모두 active한 상태가 되어 utilization이 100%가 된다. 이때 쿼리 4개가 동시에 처리되므로 inter-query 병렬화가 적용된 것으로 볼 수 있고, 쿼리 1개가 여러 core에 의해서 병렬적으로 처리되므로 intra-query 병렬화도 적용된 것으로 볼 수 있기 때문에 두가지 병렬화 방법이 통합된 것으로 볼 수 있다.
실험 환경
-
CPU 기반 매니코어 플랫폼
Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz, 12 core (24 thread)를 대상으로 하였다. 한번에 쿼리가 6개씩 들어오는 경우에 대하여 실험하였다.
성능 측정 결과
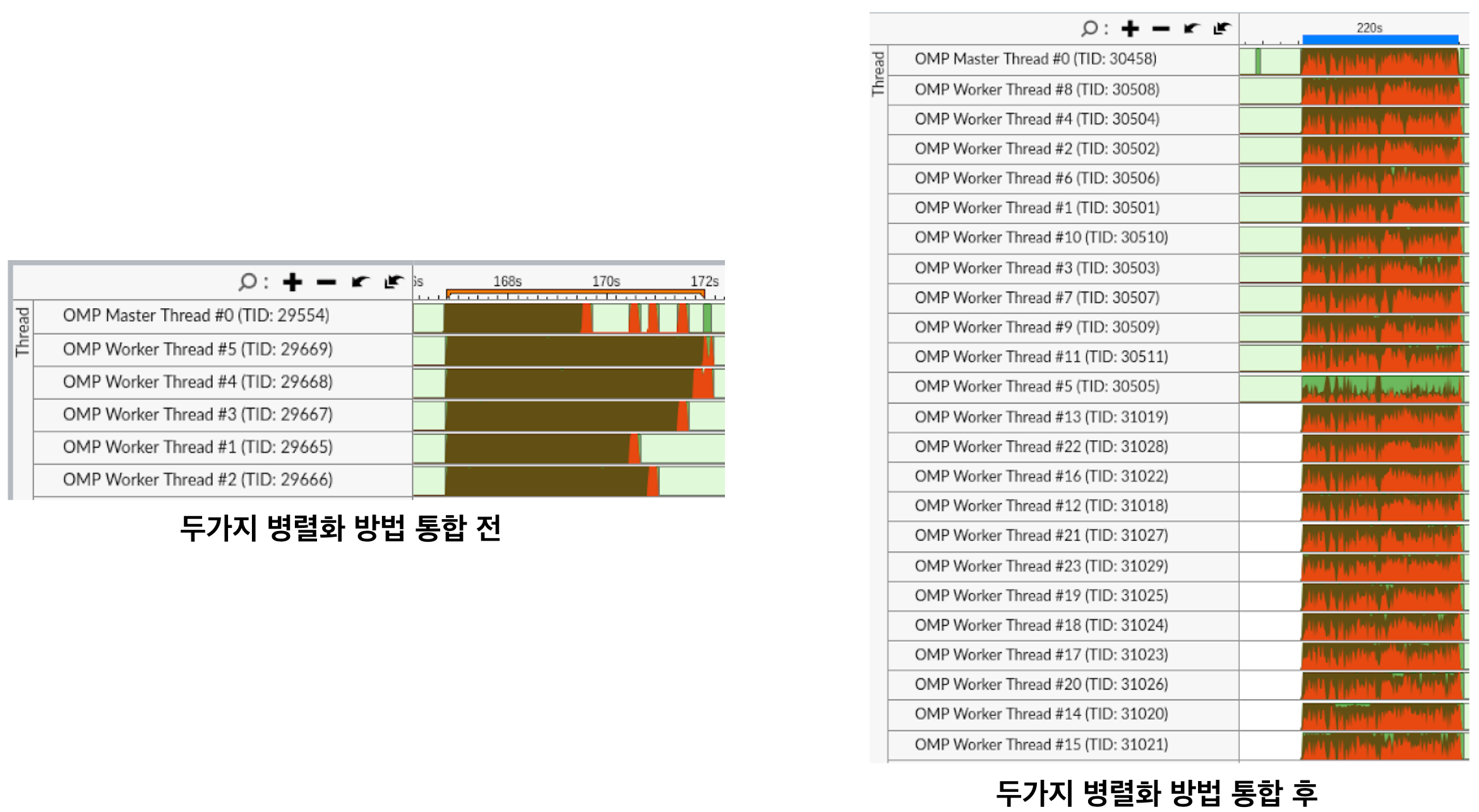
두가지 병렬화 방법 통합 전에는 24 thread중에 active한 thread가 6 thread 뿐이었다면, 두가지 병렬화 방법 통합 후에는 24 thread 모두 active하게 working하고 있는 것으로 확인되었다.
결과물
- 소프트웨어
- Github: StarChart
- 시연 영상