대규모 그래프 처리 엔진 연구
연구 배경
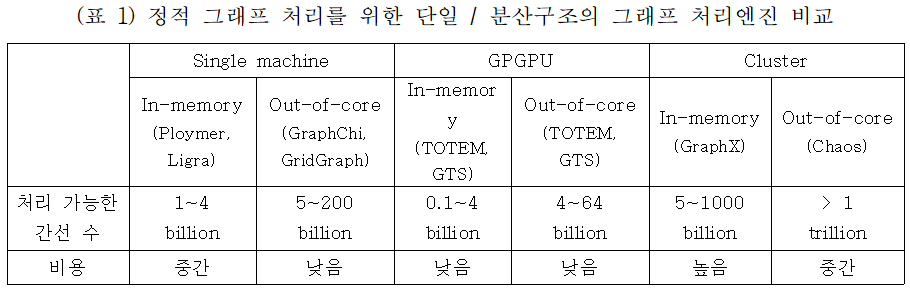
그래프 데이터는 컴퓨터 자료구조 중 하나로 정점(vertex)와 간선(edge)로 구성된 데이터이다. 정점은 현실 세계 엔티티(entity)를 나타내며 간선은 두 정점 사이의 관계성(relationship)을 표현한다. 대표적인 그래프 데이터는 웹 그래프와 소셜 네트워크 서비스(SNS)이며, 이를 분석하여 소셜미디어 분석, 유통, 진단, 사기방지, 인공지능(AI) 추천 엔진에까지 다양한 분야에 활용하여 효율적인 결과를 도출할 수 있다. 빅데이터의 발전과 함께 그래프 데이터는 기하급수적으로 증가하고 있다. 예를 들면, 최대 규모의 소셜 그래프를 가진 페이스북의 경우 14억개의 정점과 1조개의 간선으로 구성된 그래프(8TB 이상)를 보유한다. 그래프 데이터를 처리하기 단순한 연산에 특화된 GPU 서버를 많이 사용하지만, GPU 머신은 기가바이트급의 그래프 데이터 처리가 가능하기 때문에 대규모 데이터를 처리할 수 없다. 이를 해결하기 위해 GPU 서버를 빠른 네트워크로 수십~수백대 연결한 분산 시스템이 필요하지만, 분산시스템을 구성하는데에는 엄청난 비용이 소비될 뿐만 아니라 워크로드의 불균형 배치로 인해 성능에 문제가 발생한다. (표 1)은 단일 시스템이나 분산 시스템을 활용하여 성능을 높이고 비용을 줄이기 위해 그래프 알고리즘과 처리 엔진들의 성능과 비용 차이를 나타낸다.
본 연구에서는 1조개 이상의 대규모 간선으로 구성된 정적 그래프와 동적 그래프를 단일 시스템에서 처리할 수 있는 그래프 처리 엔진을 연구하는 것이다. 단일 시스템으로 분산 시스템 이상의 성능을 보장하여 비용적인 측면에서도 큰 장점을 가질 수 있다. 또한, 동적 그래프 지원으로 동적 그래프 구조에 대한 업데이트 성능과 지연시간을 보장할 수 있다. 뿐만 아니라, 하나의 처리 엔진에 여러 개의 애플리케이션을 실행하여 CPU 사용율을 높일 수 있다.
Xeon Phi 기반 그래프 처리 엔진 (Mosaic)
연구 내용
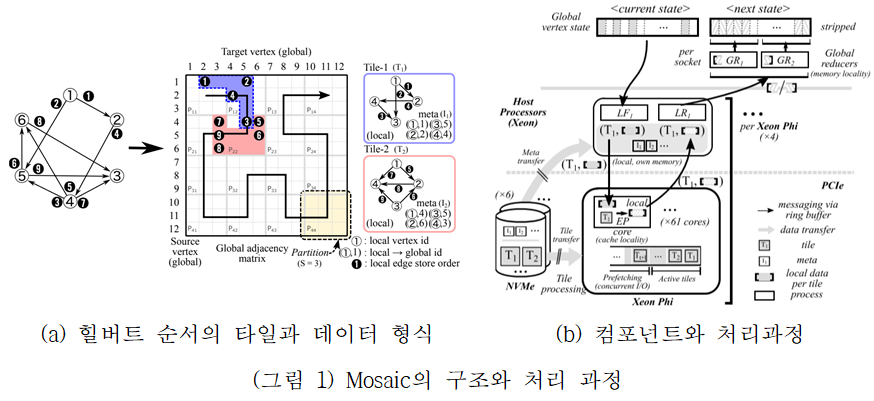
Mosaic은 인텔 코프로세서인 Xeon Phi와 빠른 스토리지인 NVMe로 저가 단일 시스템을 구성하고 멀티커널 운영체제를 통해 대규모 그래프를 처리한다. 특히 스케일업(Scale-up)과 스케일아웃(Scale-out)에서 모두 성능을 향상시키기 위해, 메모리-집약적인 작업은 빠른 호스트 CPU(Xeon)를 사용하고(scale-up), 연산과 I/O 집약적인 부분은 코프로세서(Xeon Phi)에서 동작(scale-out)하는 구조를 제시하였다. 대규모 그래프를 처리하기 위해, 그래프를 적절한 파티션 크기로 분할(타일)하고, 이 파티션을 캐시 지역성을 높이기 위해서 힐버트 순서(Hibert-ordered)로 탐색하여 서로 가까이 있는 정점들로 타일을 구성한다. 이 타일은 서브 그래프가 되며, 타일 크기는 LLC(Last Level Cache) 크기에 종속된다. (그림 1(a))은 Mosaic에서 정의한 힐버트 순서의 타일과 데이터 형식이다. 그림에서는 2개의 타일(파란색과 붉은색)과 힐버트 순서로 그래프를 탐색하는 과정을 나타낸다. (그림 1(b))는 구성한 타일들을 처리하기 위한 컴포넌트와 처리과정이다. 컴포넌트는 LF (local fetcher), EP (edge processor), LR (local reducer), GR (global reducer)로 구성된다. 스케일아웃을 담당하는 LF, LR, EP는 Xeon Phi에서, 스케일업을 담당하는 GR은 Xeon에서 동작한다. 또한 스트라이프 파티셔닝(Striped partitioning) 구조를 정의하여 NUMA 구조에 맞게 타일을 분산 처리하여, 지역성(locality)를 높이고 병목에 따른 성능 저하을 줄인다. 처리과정은 다음과 같다. 힐버트 순서에 의해 구성된 타일들은 전역 정점 상태(Global vertex state) 배열에 저장된다. 그래프 데이터의 처리를 위해 먼저 LF는 전역 정점 상태 배열로부터 정점 정보를 호스트 CPU로부터 읽어와 코프로세서에서 동작하는 EP에게 전달해준다. EP는 전달받은 데이터에 대해 힐버트 순서에 의해 알고리즘을 처리하고, 업데이트된 정점 정보를 LR에게 전달해준다. LR은 코프로세서들로부터 받은 정점 정보를 모두 취합하여 GR에게 전달해준다. GR은 전달받은 데이터를 기반으로 전역 정점 상태 배열에 반영한다. Mosaic은 Gather-Apply-Scatter 모델과 유사한 Pull-Reduce-Apply 프로그래밍 모델을 제공한다. Pull은 타일로 나누어진 서브 그래프를 처리하고, Reduce는 같은 정점에 대해 두 개의 값으로 하나로 결합하는 글로벌 그래프 정점 상태 업데이트를 지원하며, Apply는 각 정점에 대해 그래프 알고리즘을 수행한다.
성능 실험
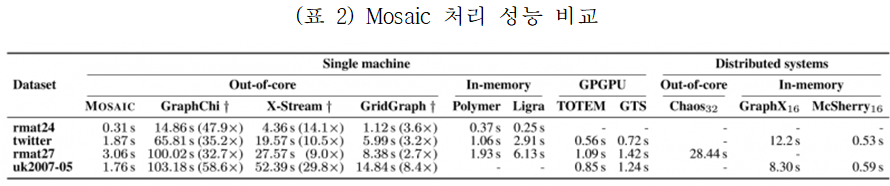
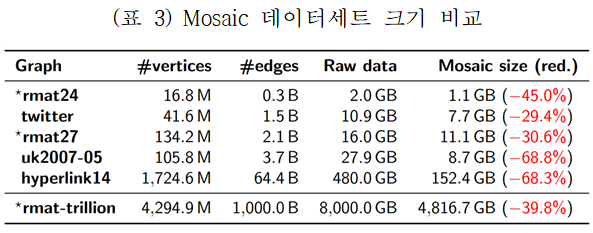
(표 2)은 Mosaic 처리 성능을 기존 연구들과 비교한 것이다. 페이지랭크(PageRank)를 처리 시간을 비교했을 경우, 0.3~3.7억개 간선으로 구성된 연구들보다 단일 시스템에서는 2.7배~58.5배 성능이 향상하였고, 분산 시스템에서는 4.7배~6.5배 성능이 향상되었다. GPGPU와는 유사한 성능을 보였지만 GPGPU보다 대규모의 그래프의 처리가 가능하다. 1조개의 간선으로 분산 시스템에서 실험한 연구들보다 9.2배 성능이 향상되었다. 기존의 단일시스템과 분산시스템 기반의 엔진보다는 우월한 성능을 나타낸다. (표 3)는 대규모 데이터를 저장했을 때 크기를 비교하였다. 힐버트 순서의 타일들은 로컬 그래프에 대한 효율적인 인코딩을 제공하기 때문에 최대 68%까지의 크기가 작아짐을 확인할 수 있다.
연구 결과물
x86 기반 그래프 처리 엔진 (cytom)
연구 내용
Cytom은 x86 기반으로 그래프를 처리하는 엔진으로, Mosaic를 근간으로 연구개발되었다. (그림 2(a))는 Cytom의 구성요소를 나타낸다. 에지를 관리하는 셀관리자(cell manager), 알고리즘을 실행하기 위한 로드밸런싱(load balancing), 셀 배포자가 할당 한 셀을 실행하는 알고리즘 실행기(algorithm executor), 모든 그래프 업데이트를 통지받고 디스크에 대한 그래프 변경을 비동기적으로 유지하는 지속성 관리자(Persistence Manager)로 구성된다.
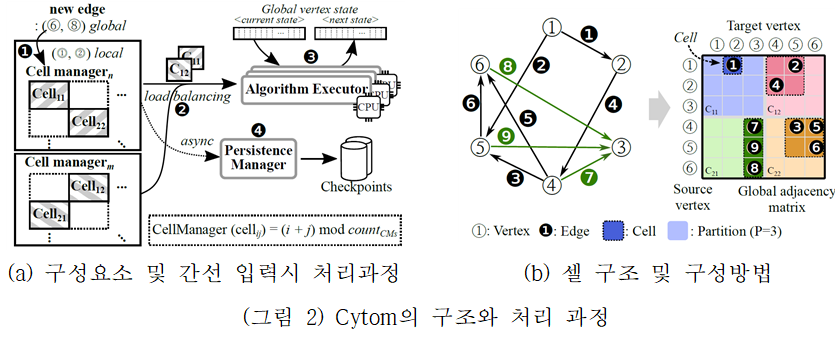
Cytom은 최신 시스템의 스토리지 오버헤드를 줄이고 그래프 구조를 업데이트할 때 효과적이다. 또한, 서브 그래프 중심의 셀 기반 그래프 표현을 새로운 실행 모델과 결합하여 글로벌 계산 단계를 시작하는 대신 서브 그래프 내에서 그래프 업데이트를 로컬에서 처리하여 성능을 향상시킨다. 또한, 많은 CPU로 구성된 매니코어 환경에서 모든 CPU의 사용율을 높이기 위해, 기존 하나의 엔진에 하나의 애플리케이션이 동작하는 구조에서 여러 개의 애플리케이션이 병렬적으로 처리할 수 있도록 다음의 기능을 추가하였다. 첫째로, 사용자가 직접 커스텀 알고리즘을 입력하여 처리할 수 있다. 이를 위해 그래프에 실행되는 알고리즘과 실행 엔진을 구조적으로 분리하고, 클라이언트가 알고리즘을 입력할 수 있는 인터페이스를 제공한다. 두 번째로, 각 정점을 업데이트할 때마다 디스크 읽기를 한 번만 수행하여 여러 알고리즘에 의한 같은 데이터 중복 읽기를 방지한다. 세 번째로, 사용하고 있지 않는 CPU에 다른 애플리케이션이 동작할 수 있도록 하여 CPU의 사용율을 증가시킨다. 마지막으로, 알고리즘 프로파일러를 제공하여 CPU 사용량, 실행시간과 같은 런타임 정보를 수집할 수 있다. 이러한 기능을 통해, 여러 개의 애플리케이션이 병렬적으로 수행될 수 있도록 스케줄링하여 CPU를 보다 효과적으로 활용할 수 있다.
성능 실험
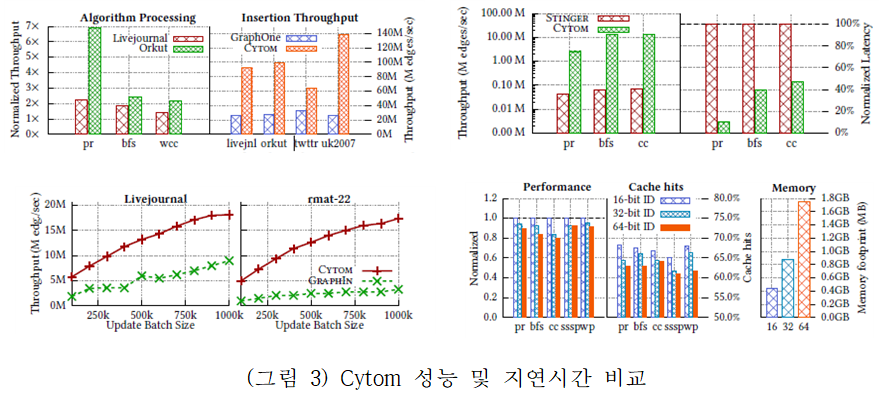
(그림 3)은 각각 대표적인 동적 그래프 처리 엔진인 GraphOne, GraphIn, Stinger와 성능 및 지연시간을 비교한 결과이다. 그래프 구조를 업데이트할 때 2배~192배 성능 향상을 보이고, 알고리즘을 처리할 때 1.5배~200배 높은 성능 향상을 보인다. 알고리즘 결과의 지연 시간은 89.9 % 감소되었음을 확인할 수 있다.
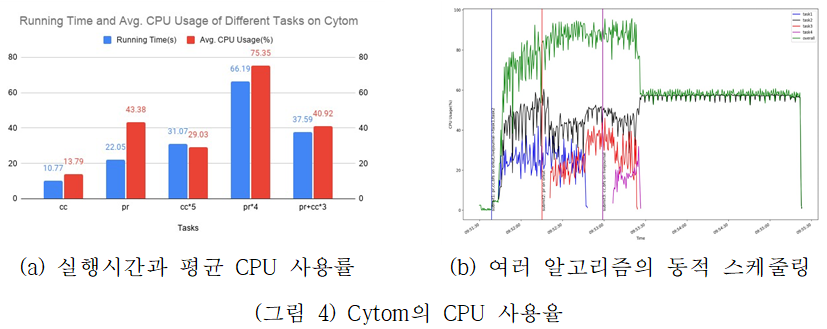
(그림 4)는 여러개의 애플리케이션을 병렬적으로 실행할 경우 CPU 사용율에 대한 성능 결과이다. (그림 4(a))는 Cytom의 워크로드 별 실행시간과 평균 CPU 사용률을 나타낸다. 다수의 애플리케이션이 병렬적으로 실행한 결과, 5개의 워크로드를 동시에 실행할 경우, 단일 워크로드를 연속해서 5번 실행하는 것보다 42.3% 짧은 평균 실행시간을 보인다. (그림 4(b)는 여러 개의 애플리케이션이 병렬적으로 수행될 수 있도록 동적으로 스케줄링 결과를 보여준다. X축은 시간을, Y축은 CPU 사용률을 나타내며, 3개의 세로줄은 애플리케이션 수를 의미한다. Cytom은 다수의 애플리케이션을 병렬적으로 실행하여 CPU를 보다 효율적으로 사용할 뿐 아니라, 다른 애플리케이션이 실행하는 동안에도 새 애플리케이션이 동시에 실행됨을 확인할 수 있다.
연구 결과물
- 공개 소프트웨어
- Github: Cytom
- 시연 동영상
- Youtube: Large-scale Evolving Graph Analysis