Lock-free 기법 연구
MV-RLU
연구배경
매니코어 머신에서 멀티쓰레드는 공유된 자원(자료구조)을 동시에 접근하는 일이 자주 발생하며 동시에 실행되는 쓰레드 갯수가 증가할수록 시스템의 성능은 공유자원 접근 방법 (동기화 매커니즘)에 따라 크게 좌우된다. 운영체제, 데이터베이스 시스템, 네트워크 스택, 저장장치 시스템 등 대부분의 소프트웨어 설계에서 동기화 매커니즘은 필수적인 요소이며 성능에 큰 영향을 미친다. 최근 프로세서 코어 개수의 증가와 하드웨어 병렬성은 빠르게 발전하고 있지만 소프트웨어의 성능 확장성은 하드웨어 발전에 미치지 못한다. 동기화 방식에 따라 다음과 같은 다양한 알고리즘(Lock, Lock-free, Delegation-style, STM, RCU-style 등)이 존재하지만 최신 매니코어 머신의 하드웨어 성능에 비례하여 성능 확장성을 제공하는 알고리즘은 없다. 따라서 본 연구진은 최신 매니코어 머신에서 성능확장성을 제공할 수 있는 새로운 동기화 매커니즘인 MV-RLU (Multi version-Read Log Update)를 제안한다. 본 연구에서는 멀티쓰레드간 공유 자원 접근에 대하여 확장 가능한 동기화 기법을 개발하여 최신 매니코어를 효율적으로 활용하고 다양한 소프트웨어 구성 요소의 성능 향상을 꽤한다. 이를 위해 직관적인 사용자 프로그래밍 인터페이스를 제공하고 동기화 구조를 제공하는 확장성 있는 동시 자료구조 프레임워크(Scalable concurrent data structure framework)을 개발한다.
연구 내용
MV-RLU는 이름에서 알 수 있듯이 RLU (Read Log Update)라는 기존 기법의 장점을 계승하고 성능을 크게 향상시켰다. MV-RLU의 구성요소는 멀티버전 로깅과 로그 버퍼의 재활용 정책이다. 멀티버전 로깅은 멀티쓰레드가 공유자원을 동시에 접근하도록 하는 메커니즘이다. 하나의 노드 또는 오브젝트를 버전 체인으로 연결하여 멀티버전화 하고 각 버전에 타임스탬프를 부여하여 각 쓰레드가 각자 적합한 버전을 접근할 수 있도록 하는 구조이다. 이 매커니즘은 전통적인 데이터베이스 시스템에서 지원하는 기법이지만 버전 체인 트레버스 비용과 로그 버퍼의 재활용 시 발생하는 성능 하락이 가장 큰 문제점으로 지적되었다.
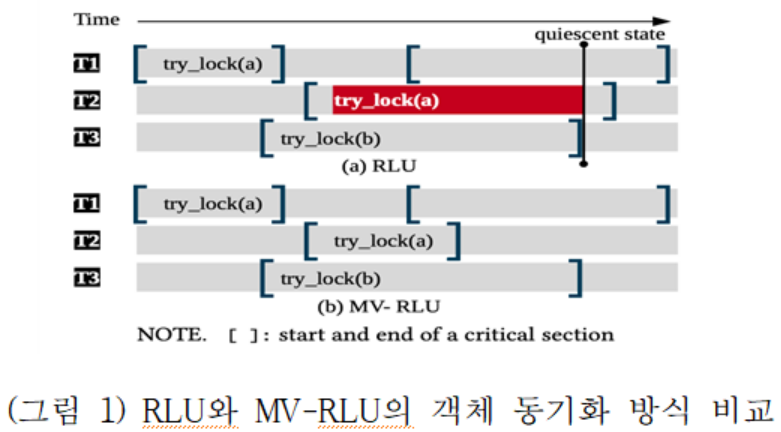
이와 같은 전통적인 멀티버전의 문제점을 해결하기 위하여 각 쓰레드별로 로그 버퍼 재활용을 병렬적으로 (concurrent GC) 수행하고 버전 체인 트레버스 비용을 줄이기 위해 로그 버퍼 재활용을 자동화 (autonomous GC) 시키고 타임스탬프 발행 비용을 최소화하기 위해 하드웨어 클럭 기반 (ORDO 기법 - "A Scalable Ordering Primitive for Multicore Machines" 논문) 타임스탬프를 차용하였다. (그림 1)은 RLU 동기화 기법의 성능 병목현상 원인과 MV-RLU가 이를 극복하는 방안을 도시하였다. 그림에서 Tn은 쓰레드번호를 의미하며 try_lock(a)는 a객체에 대해 새로운 버전 생성을 시도하는 것을 의미한다. RLU의 경우 객체당 최대 2개의 버전을 유지한다. 따라서, 쓰레드 2(T2)가 a객체에 대하여 3번째 객체 생성을 시도하는 경우 quiescent state 검출과 객체의 이전 버전을 정리(빨간색 표시 구간)할 때 까지 대기하므로 요청 처리 지연이 발생한다 (그림 1 (a)). 반면, MV-RLU는 다수의 버전을 동시에 생성할 수 있으므로 지연 없이 쓰레드 2(T2)가 새로운 버전을 생성한다(그림 1 (b)). 본 연구는 448 코어에서 실험을 통해 관찰한 바에 따르면, RLU의 경우 이와 같은 지연시간이 CPU 실행시간의 99.6%를 차지한다.
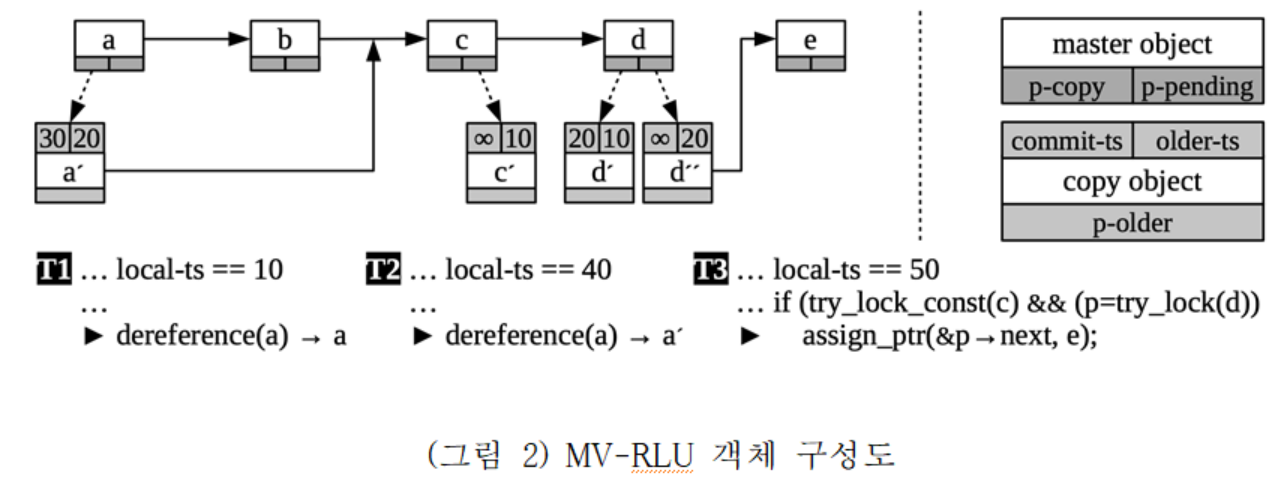
(그림 2)는 여러 쓰레드가 연결 리스트를 동시 접근하는 경우 MV-RLU가 동기화 하는 방식과 객체 구성에 대하여 도시하였다. 연결 리스트의 각 노드는 master object와 copy object로 구성된다. master object는 일반적인 메모리 할당 연산에 의하여 생성되며 copy object는 쓰레드가 try_lock을 성공하는 경우 해당 쓰레드의 circular log에 저장된다. copy object는 생성되는 시점에 p-pending 포인터에 의해 연결되며 생성한 쓰레드가 연산을 완료(commit)하는 시점에 p-copy 포인터로 옮겨진다. copy object는 커밋 타임스탬프(commit-ts)와 이전 버전 타임스탬프(older-ts) 정보를 유지하고 이전 버전 체인(p-older)으로 다수의 버전들이 연결된다. 타임스탬프 값이 무한대인 경우 아직 커밋이 완료되지 않았다는 의미이다. MV-RLU는 이와 같은 타임스탬프 순서를 통해 각 쓰레드에게 일관된 객체 정보를 제공한다. 각 쓰레드는 임계영역에 진입하는 시점에 개별 타임스탬프(local-ts)를 부여받으며 이를 통해 적절한 버전의 객체를 접근한다. (그림 2)는 b노드가 시간 30 시점에 삭제된 것을 예로 도시하였다. copy object인 a'은 타임스탬프 30에 생성되어서 다음 노드를 c로 포인팅하여 노드 b를 삭제하였다. 쓰레드 1(T1)의 local-ts는 10이므로 T1은 b노드 삭제 이전에 시작된 쓰레드이므로 a노드를 통해 b노드를 순회하지만 T2의 경우 local-ts가 40이므로 타임스탬프 40이후에 생성된 a'을 접근하고 다음 노드로 c를 순회한다. 이와 같은 방식으로 각 쓰레드는 여러 버전이 있는 객체에 대하여 일관된 뷰를 가질 수 있다.
다음은 MV-RLU의 프로그래밍 인터페이스들이다. 이들을 활용하여 매니코어 환경에서 스케일러블한 소프트웨어를 구현할 수 있다.
- Locking model: similar to POSIX read-writer lock
- RLU_READER_LOCK(self)
- RLU_TRY_LOCK(self, p)
- RLU_READER_UNLOCK(self)
- RLU_ABORT(self)
- Pointer operations
- RLU_ALLOC(size)
- RLU_FREE(self, p)
- RLU_ASSIGN_PTR(self, &p, q)
- RLU_IS_SAME_PTRS(p, q)
- RLU_DEREF(self, p)
- Initializing/deinitializing MV-RLU framework
- RLU_INIT()
- RLU_FINISH()
- Initializing/deinitializing a thread (first create a POSIX thread)
- self = RLU_THREAD_ALLOC()
- RLU_THREAD_INIT(self)
- RLU_THREAD_FINISH(self)
- RLU_THREAD_FREE()
보다 자세한 설명은 맨 아래에 있는 MV-RLU 소개 영상을 참조하면 된다.
그리고 MV-RLU를 활용하여 기존의 B-tree 등 자료구조를 스케일러블 자료구조로 구현을 하였고, 소스코드도 공개하였다.
-
MV-RLU optimized B-tree
-
MV-RLU optimized ART
-
Kyoto-Cabinet 적용
MV-RLU 기술을 오픈소스 키벨류 스토어 Kyoto-Cabinet에 적용한 소프트웨어도 상기 깃허브에 공개하였다.
실험
MV-RLU 성능 평가를 위해 8소켓 448 코어(물리적으로는 224 코어)의 Intel Xeon Platinum 8180 CPU(2.5GHz)와 337GB DRAM이 장착된 서버를 사용하였다. 실험에서는 다양한 자료구조(Linked list, Hash table, Binary search tree)를 접근하는 마이크로 벤치마크와 실제 응용 워크로드를 통해 성능평가를 실시하였다. 비교대상 동기화 기법으로는 RCU, RLU, RLU-ORDO(ORDO timestamp를 사용한 RLU), Versioned-programming, SwissTM, Harris-Michael linked list, predicate-RCU(PRCU)를 선택하였다.
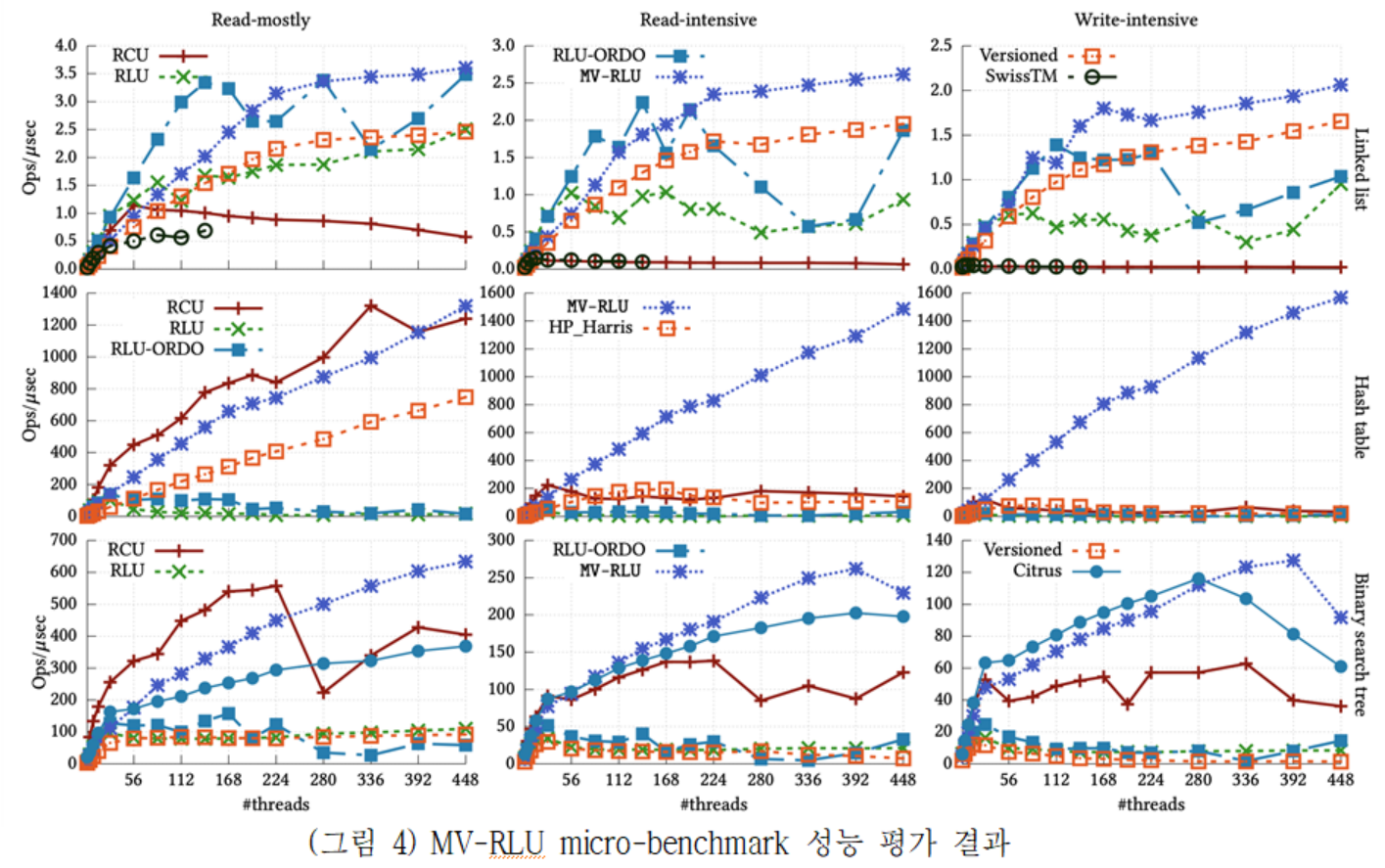
(그림 4)는 세 가지 자료구조에 대하여 Read-mostly, Read-intensive, Write-intensive로 구분한 마이크로 벤치마크의 성능결과를 보여준다. MV-RLU는 대부분의 경우에서 가장 우수한 성능과 확장성을 보여준다. RCU의 경우 Read-mostly 워크로드에서 MV-RLU와 유사하거나 좋은 성능을 보이는 구간이 있지만 일부이며 쓰기 연산이 많아지는 Read-intensive와 Write-intensive에서는 MV-RLU와 큰 차이로 뒤처지는 것을 볼 수 있다. Citrus나 Versioned 기법이 특정 자료구조에 대해 MV-RLU와 유사한 성능을 보이는 경우도 있지만 다른 자료구조에서는 성능이 떨어지는 현상이 발생한다. 그리고 Hash table의 경우, Write intensive 워크로드이며 448-thread 실행에서 MV-RLU가 다른 기법에 비해 최대 600배 이상의 성능 향상을 보여준다.
연구 결과물
본 연구결과는 멀티스레드가 공유자원을 효율적으로 접근할 수 있는 구조를 응용 소프트웨어에 제공하여 성능 향상을 도모하는 범용 프레임워크이며 직관적인 응용 프로그래밍 인터페이스 (Simple application program interface), 범용적인 프레임워크 (General framework), 다양한 자료구조 결합성 (Composability)와 같은 장점을 가진다. 따라서 멀티스레드 환경의 대부분의 응용 (예: 운영체제 커널, 파일시스템, 데이터베이스 시스템, 사용자 응용 프로그램)에서 활용 할 수 있다.
- 논문
- 공개 소프트웨어
- Github: MV-RLU
- Github: MV-RLU optimized B-tree
- Github: MV-RLU optimized ART
- Github: ORDO
- Github: jet-KyotoCabinet
- 시연 동영상
- 기술 소개 영상
KHRONOS
연구 배경
매니코어 머신에서의 운영체제 성능 확장성을 높이기 위한 방안으로 lock-free 동기화 기법은 좋은 방안으로 주목받는다. RCU (Read Copy Update)는 대표적인 lock-free 동기화 기법으로 최근 사용량이 급증하고 있다. 2002년에 리눅스 커널에 적용된 이후로 API의 사용횟수가 2010년에 3,000에서 2022년에는 16,000으로 5배 이상 증가하였다. RCU는 동시 읽기에서는 좋은 성능을 보이지만 동시 쓰기가 요청되면 성능하락이 크게 발생하고 API 사용의 복잡성으로 인해 적용 범위의 제한이 있다. 이를 개선하기 위해 2015년에 RLU (Read Log Update)가 제안되었고 이후 2019년에 RLU의 성능 개선을 위해 MVCC (Multi-Version Concurrency Control) 기반의 MV-RLU (Multi-Version RLU)가 제안되었다. MV-RLU는 동일한 객체에 대한 쓰기 연산 충돌 시 새로운 버전을 생성하여 객체 재활용(Object Reclamation)을 위한 동기화 대기를 방지하여 성능 확장성을 크게 개선하였다. 진보된 lock-free 동기화 기법인 RLU와 MV-RLU를 운영체제 커널에 적용 할 경우 매니코어 성능 확장성을 기대할 수 있다. 본 연구에서는 연구용 운영체제 커널의 주요 자료구조에 RCU, RLU, MV-RLU를 적용하여 운영체제의 성능 확장성을 분석하고 MVCC (Multi-Version Concurrency Control) 기반 동기화 기법이 적용된 운영체제의 프로토타입과 설계 기반을 마련한다.
연구 내용
본 연구에서는 MVCC 동기화 기법이 적용된 연구용 운영체제인 KhronOS를 제시한다. KhronOS는 연구용 운영체제로 알려진 sv6 기반 ScaleFS 파일시스템의 주요 자료구조 동기화를 위해 RLU와 MV-RLU를 도입한다. RLU와 MV-RLU를 sv6 기반 운영체제에 도입하기 위해 추가적인 라이브러리와 메모리 할당자 등에 대한 수정 및 구현이 요구된다. ScaleFS 파일시스템의 주요 자료구조인 Linked-list와 Hash table에 RLU와 MV-RLU를 적용하고 micro-benchmark를 이용하여 성능 확장성을 평가 및 분석한다. ScaleFS의 주요 자료구조에 대한 동기화 기법 적용 및 성능 평가는 모두 kernel-level에서 이루어지지만 성능 비교를 위해 동일 자료구조에 대한 user-level에서의 동기화 기법 적용 및 평가도 이루어진다. ScaleFS 주요 자료구조에 대한 새로운 동기화 기법 적용을 토대로 파일시스템 전체 동작에 대한 동기화 기법 적용이 진행 중이며 오픈소스 프로젝트로 공개된다. 주요 연구내용은 다음과 같다.
- ScaleFS 파일시스템의 주요 자료구조에 대한 동기화 기법 적용 ScaleFS 파일시스템의 주요자료구조인 Linked-list와 Chained hash table에 RCU-style (RCU, RLU, MV-RLU) 동기화기법을 적용한다. 그리고 적용된 자료구조의 성능을 측정하기 위해 sv6 기반 운영체제에 micro-benchmark를 구현하였다. 성능비교를 위해 sv6 기반 운영체제의 kernel-level과 user-level에서 각각 매니코어 성능 확장성을 평가 및 분석하였다. 다음과 같은 작업을 수행하였다.
- RCU-style (RCU, RLU, 및 MV-RLU) 동기화 기법이 적용된 Linked-list와 Chained hash table을 구현
- RCU-style 동기화 기법을 sv6 기반 운영체제에 에 적용하기 위해 필요한 라이브러리 및 함수 구현 (락 프리미티브, MV-RLU 스레드별 로그 할당을 위한 메모리 할당자 등)
- Kernel-level과 성능 비교를 위하여 User-level에 동일한 RCU-style 동기화 기법 적용
- RCU: Kernel-level은 sv6기반 ScaleFS 파일시스템에 구현된 RCU 사용, User-level은 공개된 RCU 구현 라이브러리(https://bitbucket.org/mayaarl/citrus/src/master/) 사용 및 포팅
- RLU: 오픈소스 라이브러리(https://github.com/rlu-sync/rlu) 사용 및 포팅
- MV-RLU: 오픈소스 라이브러리 (https://github.com/cosmoss-vt/mv-rlu) 사용 및 포팅
- sv6 기반 ScaleFS 파일시스템에 MV-RLU 동기화 기법 적용 sv6 기반 ScaleFS 파일시스템은 RCU 동기화 기법을 도입하여 기존 락 방식에 비해 높은 성능 확장성을 제공한다. 본 연구는 ScaleFS 파일시스템의 RCU 동기화 기법을 MV-RLU로 대체하여 재설계하고 적용하였다. MV-RLU를 ScaleFS 파일시스템에 적용하기 위해서는 다음과 같은 작업을 수행하였다.
- C 기반의 MV-RLU를 C++ 기반으로 변경
- ScaleFS에서 RCU 동기화와 관련된 설계부분을 MV-RLU에 맞게 재설계
- 기존 RCU로 동기화된 Chained hash table을 MV-RLU로 변경
- sv6 기반 운영체제 부팅과정에 MV-RLU를 초기화
- PCB (Process Control Block)에 MV-RLU 관리를 위한 스레드관련 metadata 추가
- RCU API가 적용된 Kernel-level의 Chained hash table을 MV-RLU API로 적용
- MV-RLU 동기화 적용 성능 벤치마크는 sv6 운영체제에 포함된 dbench, lfs-smallfile, mailbench등을 이용
- ScaleFS 코드 수준에서 MV-RLU 적용을 위해 고려해야할 주요 내용은 아래와 같음
- ScaleFS의 kernel은 C++로 작성되어 있어서 파일시스템에 적용하기 전에 chainhash.h (Chained hash table 구현) 파일에 대해 MV-RLU 동기화 기법 적용
- inode를 탐색하기 전에 RCU section에 진입하여 읽어온 inode에 대한 참조를 안전하게 보존
- RCU section 내부에서도 자료구조를 재탐색하면 최신 데이터를 읽을 수 있음
- MV-RLU의 경우 section을 재진입하지 않으면 최신 데이터를 읽을 수 없음
- 현재 진행 및 오픈소스 프로젝트 진행 사항 ScaleFS에 MVCC기반 동기화 기법(MV-RLU)으로 동기화 하기위해 다음과 같은 최적화, 구현 및 실험의 보완이 필요하다.
- 파일시스템에 적용된 MV-RLU 동작을 검증하는 방법 보완 (현재 최신 데이터를 읽을 수 없음)
- sv6 운영체제에 포함된 dbench, lfs-smallfile, mailbench 등을 통한 파일시스템의 성능 평가 및 최적화
- 개발환경
- 지원 하드웨어: QEMU, 4코어 인텔 코어2, 16코어 AMD 옵테론 8350, 48코어 AMD 옵테론 431, 80코어 인텔 제온 E7-8870 (xAPIC 및 x2APIC기반 아키텍처 모두 지원)
- 컴파일러: gcc-4.7, g++-4.7, python2
- 필수 패키지: libz-dev, gawk, qemu-system
- perf 결과 분석
- 응용프로그램 실행 시, kernel 내부에서 사용한 함수와 그 함수 실행에 소모된 cpu cycle을 추적함 (다른 옵션도 있으나 불필요)
- kernel bench의 MV-RLU는 log_reclaim_force라는 함수에서 많은 시간을 소모하는 것으로 분석됨.
- log_reclaim_force는 garbage collector에게 log reclaim을 요청하고 기다리는 함수임. 이 함수는 thread의 log가 75% 이상 사용 중일 때만 호출되어야 하므로 매우 낮은 빈도로 호출되는 것이 정상임.
- monkstats
- 응용프로그램 실행 시, kernel 내부에서 발생하는 이벤트들에 소모된 cpu cycle을 추적함 (page fault cycle 등등)
- kernel bench의 MV-RLU는 page fault cycle에서 소모하는 cpu cycle이 높은 것을 발견함
- 원인은 thread per log를 할당하는데 사용한 vmalloc으로 발생함
- kmalloc을 이용한 log allocator 작성하였고 결과적으로 page fault cycle을 감소 시켰음.
KhronOS를 Intel Xeon CPU 2소켓 36-core(hyperthreaded 72-core) 머신에서 부팅하는 화면은 다음과 같다.
실험
ScaleFS 파일시스템의 주요자료구조에 대한 여러 동기화 연산이 매니코어 시스템에서 어떠한 성능을 보이는지 알아본다. 아래 질문에 대한 답을 통해 RCU-style 동기화 기법을 평가한다.
- RCU-style (RCU, RLU, MV-RLU) 동기화 기법들이 확장성 있다고 알려진 운영체제의 kernel-level과 user-level에서 어떠한 성능을 보이는가?
- 널리 사용되는 자료구조인 Linked-list와 Hash table을 동시에 접근하는 경우 각 동기화 기법들의 성능 특성은 어떠한가?
- 워크로드의 읽기와 쓰기 비율에 따라서 각 동기화 기법의 성능은 어떻게 달라지는가?
- 실험환경 성능 평가를 위해 2소켓 36-core (hyperthreaded 72-core)의 Intel Xeon Processor E5-2697 CPU (v4 2.4GHz)와 256GB DRAM이 장착된 서버를 사용하였다. 성능평가의 비교 대상은 RCU-style의 동기화 기법인 RCU, RLU, MV-RLU이다. RCU의 User-level은 Citrus RCU 구현을 사용했으며, Kernel-level은 SV6에 있는 EBR 방식의 RCU를 사용하였다. RLU와 MV-RLU는 User-level과 Kernel-level 모두 공개 라이브러리를 사용하였다. 각 RCU-style 동기화의 옵션은 기본을 적용하였으나, MV-RLU의 스레드별 로그 사이즈는 128KByte이다.
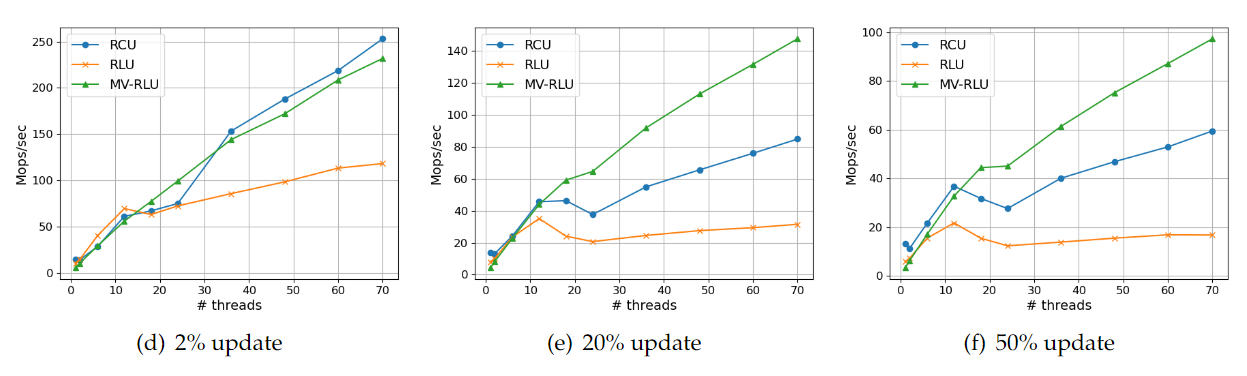
- User-level 실험결과 User-level의 Linked-list 실험 결과의 경우 RLU가 세 가지 모든 경우에 대해 가장 좋은 성능을 보인다. RCU의 경우 2%에서는 확장성 있는 성능을 나타내지만, 20%와 50% 업데이트 워크로드에서는 성능이 매우 감소한다. RCU의 특성상 50% 업데이트에서 성능 하락이 더욱 크게 나타남을 알 수 있다. MV-RLU의 경우 2% 업데이트에서 가장 낮은 성능 향상을 보이지만 업데이트 비율이 높아지더라도 확장성 있는 성능을 보여준다.
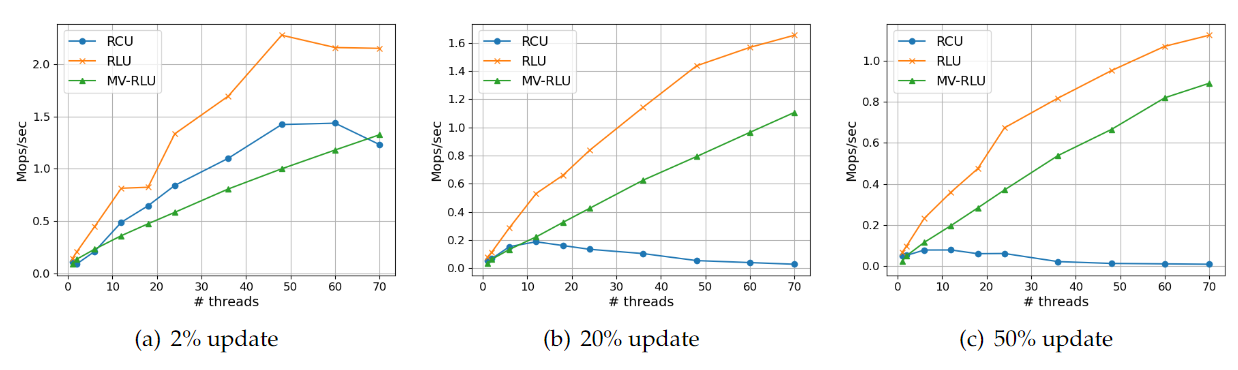
[linked list on user-level]
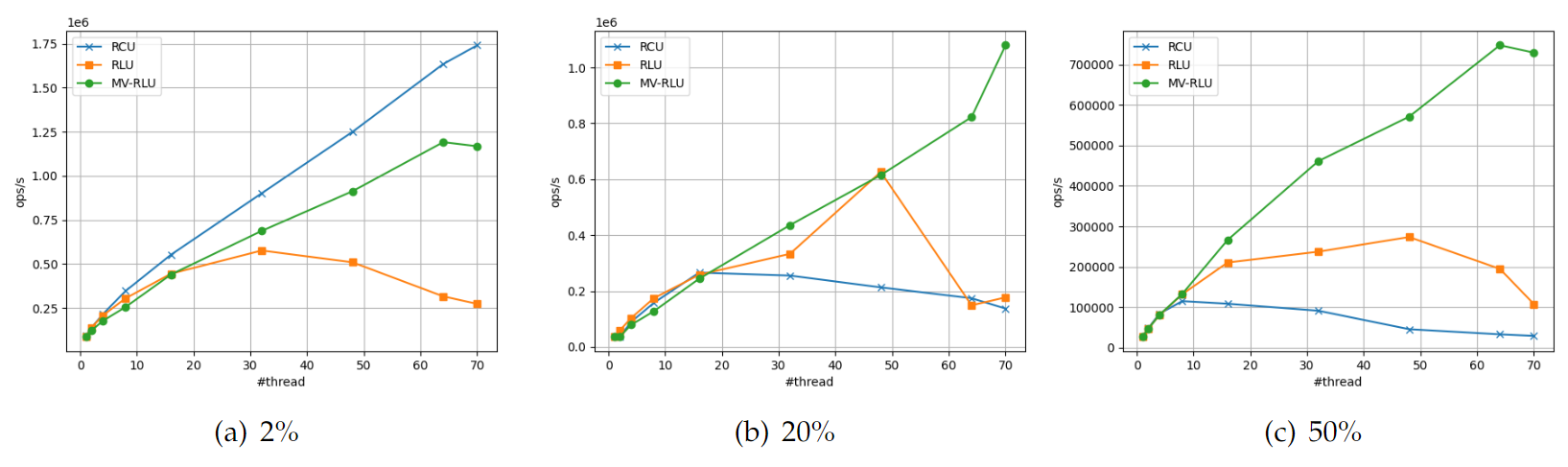
User-level의 Hash table 실험 결과의 경우 RLU는 10코어 이후에 갑자기 성능이 떨어지는 현상은 실행 스레드 개수가 NUMA CPU의 원격 소켓에서 실행을 하는 것 같다, zipf가 생성하는 값들은 그 빈도가 조화급수에 비례한다. zipf 분포에 따라 생성되는 수의 범위를 10,000으로 하면 가장 높은 빈도로 발생하는 값은 10.2%가 된다. 이렇게 같은 값이 반복적으로 삽입, 삭제되면 정렬된 Linked-list로 이루어진 Hash table의 경우 Linked-list의 동일한 부분에 반복적인 수정이 발생한다. 결과적으로 MV-RLU 객체의 버전 체인이 길어지게 되어 MV-RLU 스레드가 Hash table을 탐색하는 비용이 상승하게 된다.
[hash table on user-level]
- Kernel-level 실험결과 Kernel-level의 Linked-list 실험 결과의 경우 RCU와 MV-RLU의 성능 결과는 User-level과 비슷한 양상을 보였다. 읽기가 대부분(2% 업데이트)을 차지하는 워크로드에서는 RCU가MV-RLU에 비해 더 좋은 성능을 보이지만 업데이트 비율이 증가하게 되면 성능이 매우 감소한다. 20% 업데이트의 경우 16개 스레드 실행 이후 성능이 서서히 감소한다. 50% 업데이트의 경우 8개 스레드 실행 이후 성능이 서서히 감소하다가 48개 스레드 실행 이후에는 급감하는 양상을 보인다. 70개 스레드 실행의 경우 스레드 1-2개의 실행과 유사한 정도의 비효율적인 성능 특성을 보인다.
[linked list on kernel-level]
Kernel-level의 Hash table의 경우 User-level과 크게 다르지 않은 결과를 보이지만 약간 상이 한 부분이 있다. 2%와 20% 업데이트의 경우 MV-RLU는 스레드 개수가 증가함에 따라 선형적인 성능 증가를 보이지만 RCU의 경우 일정 스레드 개수 이후 성능이 감소함을 보인다. 2% 업데이트의 경우 64개 스레드 이후 그리고 20% 업데이트의 경우 48개 스레드 이후 성능이 감소함을 보인다. 성능 평가 플랫폼의 한계로 인해 더 많은 수의 CPU 코어에서 실험을 못했지만 RCU의 동시성 한계와 더 많은 코어 수의 리눅스 플랫폼 성능결과로 봤을 때 더 많은 수의 스레드 실행에서는 더욱 큰 성능 감소가 있을 것으로 예상된다. 50% 업데이트의 경우 RCU와 MV-RLU 모두 특정 스레드 개수 이후 성능 감소가 나타난다.
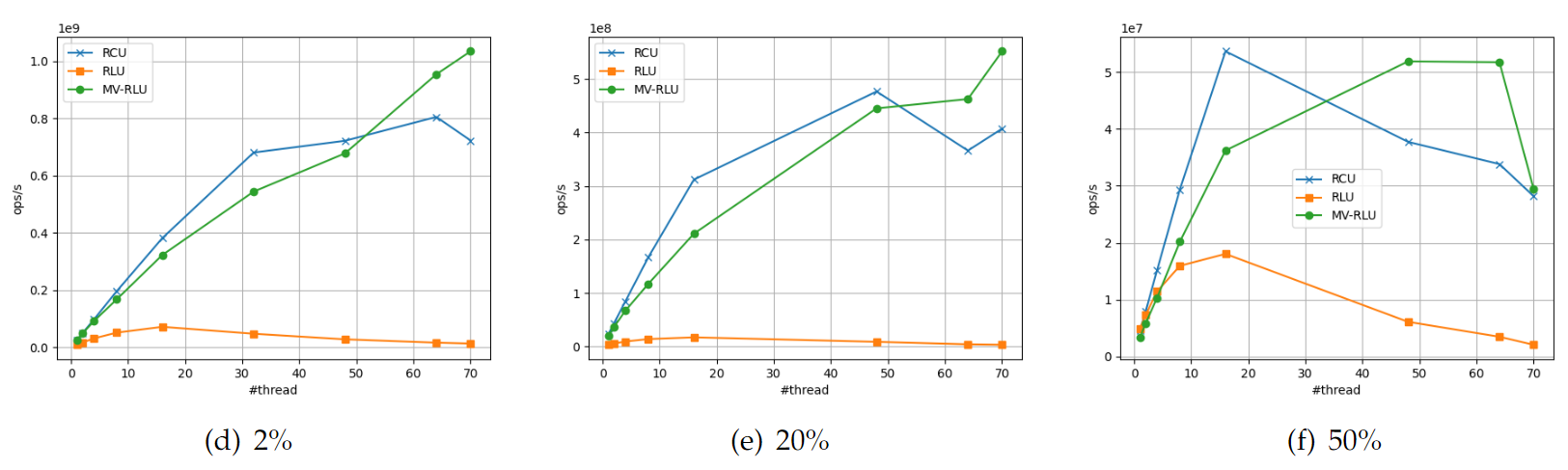
[hash table on kernel-level]
기대 효과
- 매니코어 머신에서 확장성 높은 kernel 및 user application 개발 및 성능 분석 가능
- 매니코어 확장성의 다양한 병목구간 해소 및 분석이 가능
- 매니코어 확장성있는 다양한 user/kernel-level 소프트웨어 기대
- MVCC를 운영체제 커널에 도입하여 성능 확장성 있는 운영체제 연구 활성화를 기대
- 운영체제의 다양한 구성요소(메모리관리, 입출력처리, 네트워크 등) 적용 기대
- 다양한 환경의 멀티스레드 워크로드에 대한 성능향상 기대
- 연구용 운영체제를 통해 RCU-style 동기화 기법의 테스트베드로 사용 가능
- 연구용 운영체제의 주요 자료구조에 대한 동기화 기법 적용을 바탕으로 파일시스템 전체 동작에 대한 동기화 기법 적용
- 파일시스템 외 운영체제의 구성요소(예: 가상메모리 시스템, 네트워크 스택 등)에 RCU-style 동기화 기법 적용으로 성능향상 기대
연구 결과물
- 논문
- 공개 소프트웨어
- Github: KHRONOS
- 시연 동영상
- Youtube: A Lockfree Scalable Operating System
Timestone
연구 배경
제안한 MV-RLU는 휘발성 메모리(DRAM)에서 동작하는 알고리즘으로 데이터 변경 내역을 관리하는 로그가 시스템의 오류나 전원차단 등으로 소실될 수 있다. 최근 컴퓨터시스템의 큰 변화중 하나는 매니코어와 함께 영구메모리를 탑재한 머신의 출시이다. 영구메모리는 바이트단위 접근과 DRAM과 유사한 성능을 제공하므로 사용자 데이터 손실을 방지할 수 있는 응용 개발에 유용하다. 하지만 높은 성능과 매니코어 확장성을 제공하기 위해서는 영구메모리 관리 소프트웨어의 지원이 반드시 필요하다. 대부분 트랜잭셔널 메모리 방식으로 사용자 데이터 복구를 지원하지만 고성능과 매니코어 확장성을 제공하는 소프트웨어 관리 기법이 전무하다. 대표적으로 인텔에서 제공하는 Persistent Memory Development Kit (PMDK) 소프트웨어는 매니코어 머신에서 성능 확장성을 전혀 제공하지 못하는 문제를 보인다. 따라서 본 논문에서는 고성능과 높은 성능 확장성을 제공하는 트랜잭셔널 메모리 소프트웨어인 TimeStone을 제안한다.
연구 내용
TimeStone은 MV-RLU를 기반으로 다음의 기능을 강화하였다. 1) 영구메모리에서 쓰기 트래픽과 쓰기 증폭을 줄이기 위해서 휘발성 메모리-영구메모리 기반 하이브리드 로깅 기법을 제안하고, 2) MV-RLU 보다 강력한 일관성 모델(strong consistency model)을 제공하는 방안 제안하였다. TimeStone은 이와 같은 기능 강화를 위하여 TOC(Transient, Operational, Checkpoint) 이라는 로깅 기법을 제안하고 높은 성능 확장성과 다양한 트랙잭션 isolation level을 지원하기 위해 MV-RLU에서 사용한 MVCC 방식을 도입하였다.
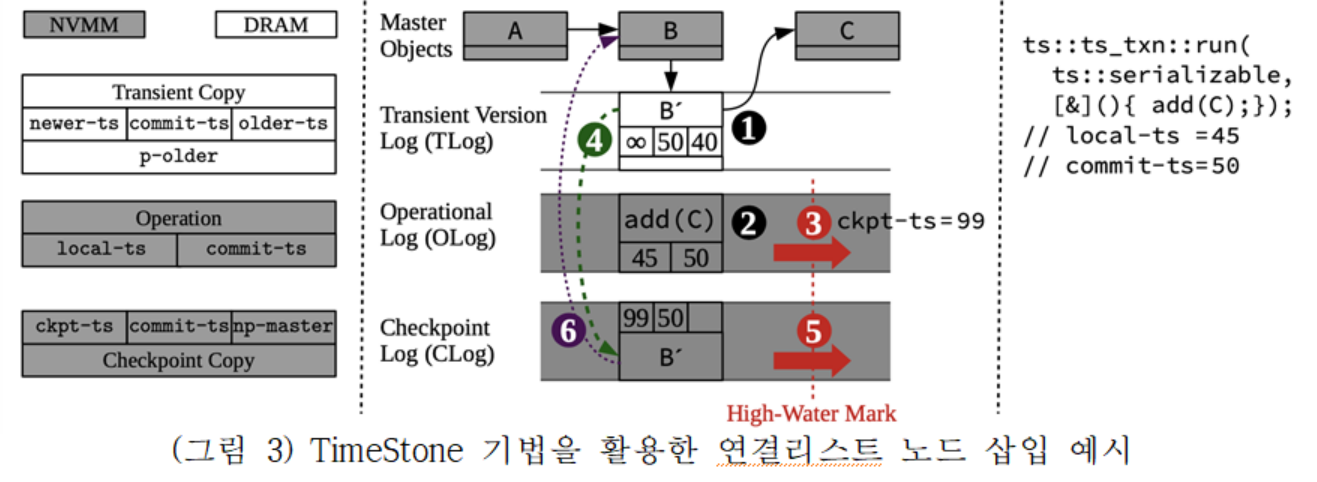
(그림 3)은 TimeStone 기법에서 연결리스트 노드 삽입 시 TOC 로깅의 동작을 도시하였다. TOC 로깅은 휘발성-영구메모리의 계층화된 하이브리드 구조를 사용한다. (그림 3)에 도시된 TOC 로깅의 구조를 살펴보면, 휘발성 메모리(DRAM)을 사용하는 Transient Version Log(TLog)가 있고 아래 영구메모리를 사용하는 Operational Log(OLog)와 Checkpoint Log(CLog)가 계층화 되어 있다. TLog는 중복된 쓰기를 흡수하여 영구메모리로 가는 쓰기량을 크게 줄인다. OLog와 CLog는 사용자 데이터 복구를 위해서 사용된다. (그림 3)에서는 연결리스트에 A, B노드가 있는 상황에서 노드 C가 추가되는 경우 연산을 순서대로 도시하였다. (1) TLog에 B노드의 복사본을 생성하여 노드 C를 다음 노드로 포인팅 한다. (2) add(C) 라는 연산 명칭을 OLog에 영구메모리에 기록하여 추후 트랜잭션 복구 시 사용한다. (3)과 (5) 단계에서는 각각 OLog와 CLog의 사용량을 기록해둔다. (4) TLog를 재생하고 (6) CLog를 재생하는 절차를 통해 로그를 연속적으로 사용할 수 있다. (그림 3)은 TimeStone 기법에서 연결리스트 노드 삽입 시 TOC 로깅의 동작을 도시하였다. TOC 로깅은 휘발성-영구메모리의 계층화된 하이브리드 구조를 사용한다. (그림 3)에 도시된 TOC 로깅의 구조를 살펴보면, 휘발성 메모리(DRAM)을 사용하는 Transient Version Log(TLog)가 있고 아래 영구메모리를 사용하는 Operational Log(OLog)와 Checkpoint Log(CLog)가 계층화 되어 있다. TLog는 중복된 쓰기를 흡수하여 영구메모리로 가는 쓰기량을 크게 줄인다. OLog와 CLog는 사용자 데이터 복구를 위해서 사용된다. (그림 3)에서는 연결리스트에 A, B노드가 있는 상황에서 노드 C가 추가되는 경우 연산을 순서대로 도시하였다. (1) TLog에 B노드의 복사본을 생성하여 노드 C를 다음 노드로 포인팅 한다. (2) add(C) 라는 연산 명칭을 OLog에 영구메모리에 기록하여 추후 트랜잭션 복구 시 사용한다. (3)과 (5) 단계에서는 각각 OLog와 CLog의 사용량을 기록해둔다. (4) TLog를 재생하고 (6) CLog를 재생하는 절차를 통해 로그를 연속적으로 사용할 수 있다.
성능 실험
TimeStone은 성능 평가를 위해 2소켓 112 코어의 Intel Xeon Platinum 8280M CPU(2.5GHz)와 768GB DRAM 그리고 1.5TB의 Intel Optane DC Persistent Memory(영구메모리)가 장착된 서버를 사용하였다. 실험에서는 다양한 자료구조(Linked list, Hash table, Binary search tree)를 접근하는 마이크로 벤치마크와 실제 응용 워크로드를 통해 성능평가를 실시하였다. 비교대상 동기화 기법으로는 DudeTM, Romulus, Intel PMDK를 선택하였다.
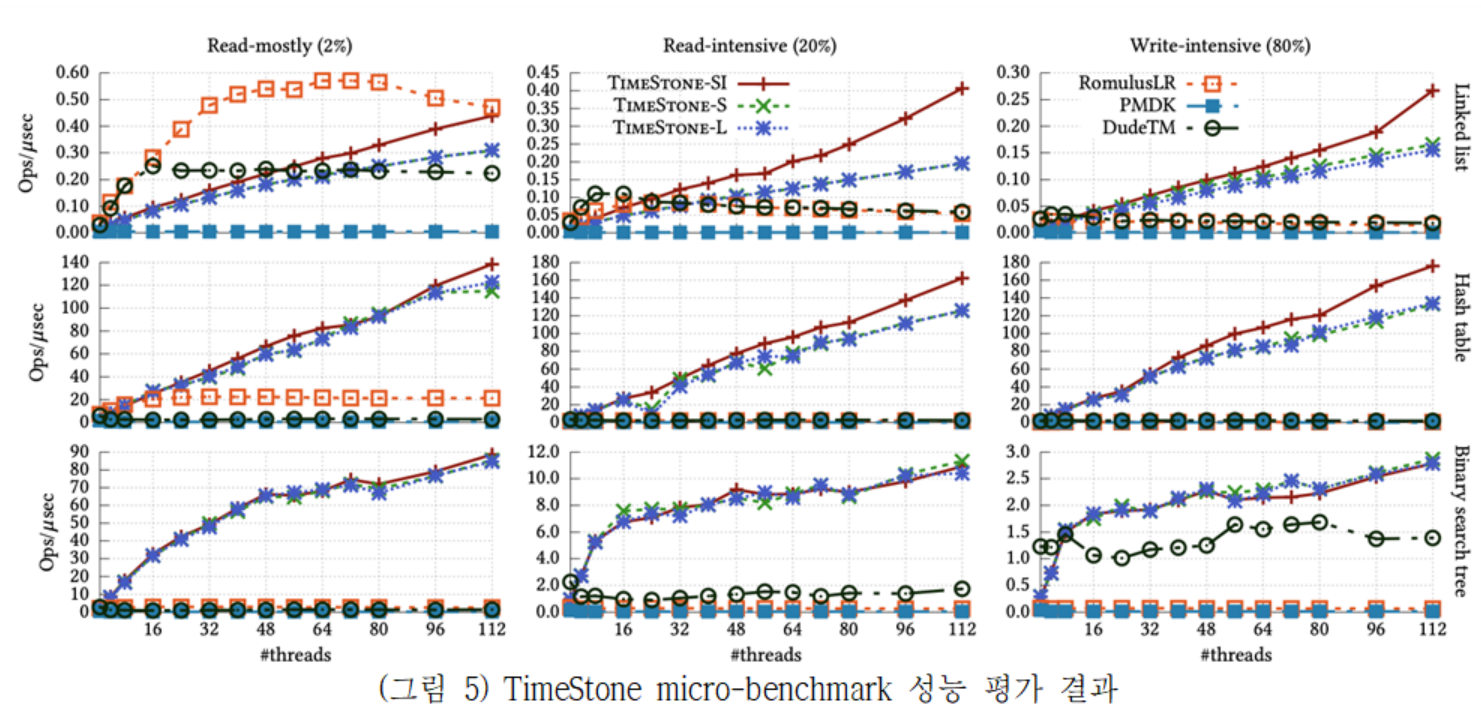
(그림 5)는 MV-RLU와 동일한 세 가지 자료구조에 대하여 Read-mostly, Read-intensive, Write-intensive로 구분한 마이크로 벤치마크의 성능결과를 보여준다. TimeStone은 대부분의 경우에서 가장 우수한 성능과 확장성을 보여준다. Romulus의 경우 Linked list 자료구조 Read-mostly에서만 가장 좋은 성능을 보일뿐 나머지 경우 TimeStone이 가장 좋은 성능을 보인다. Hash table의 경우 TimeStone이 다른 기법에 비해 최대 30배 이상의 성능 향상을 보이고 선형적인 성능 확장성을 보였다.
연구 결과물
- 논문
- 공개 소프트웨어
- Github: Timestone
- Github: Timestone optimized B-tree
- 시연 동영상