하스켈 연구
연구 배경
코어의 수를 늘림으로써 CPU의 성능을 향상시키는 다중코어 구조 시스템에서는 병렬 프로그래밍이 필수적이다. 병렬 프로그래밍은 기존 방법에 비해 훨씬 어렵고 오류를 내포할 가능성이 큰 문제점을 가지고 있다. 이를 해결하는 한 방법으로써, 본 연구에서는 순수 함수형(pure functional) 언어인 Haskell을 이용한 병렬 프로그래밍에 대한 연구를 진행하고 있다.
하스켈의 특징
하스켈은 지연 계산(lazy evaluation) 방식의 순수 함수형 언어이다. 하스켈은 람다 계산법(the lambda calculus), 타입 이론(type theory) 등의 강력한 이론적 기반으로 갖고 있는 언어로서 소프트웨어의 모듈성(modularity), 무결점성(safety), 생산성(productivity), 가독성(readability) 등에서 탁월한 장점을 갖고 있다. 병렬 프로그래밍의 관점에서 볼 때, 하스켈은 mutable 변수를 사용하지 않으며, 계산 순서에 상관없이 모든 식(expression)은 언제나 유일한 값을 갖는 특징이 있으므로, 계산 할 식(redex)을 병렬처리 할 수 있는 내재적 병렬성을 갖는다.
연구 목표
본 연구에서는 다음과 같은 문제들을 해결하기 위한 연구를 진행한다.
- 하스켈 고유의 특징인 순수성, 지연계산 등의 특징과 기존의 장점을 유지하면서, 하스켈의 병렬성을 자연스럽게 표현할 수 있는 병렬 프로그래밍 방법 연구
- 본 사업을 통해서 새로 구성되고 있는 매니코어 시스템 구조에 맞는 최적화된 병렬처리 기능의 하스켈 프로그래밍 환경 연구(Eval 모나드, Cloud Haskell, SAM(simple actor model)
- GHC의 GC(Garbage Collection) 메커니즘 분석 및 튜닝 기법에 대한 연구
- SAM 성능 개선을 위한 lock free 구조 기반의 메시지 전달 방법 연구(ex. STM(Software Transaction Memory), MV-RLU)
- 매니코어 리눅스 환경과 분할형 운영체제 환경을 위한 하스켈 병렬 프로그래밍 환경 연구
연구 결과
매니코어 환경에서의 병렬 프로그래밍 모델 연구
본 연구에서는 표절 검사 프로그램을 기반으로 하스켈의 병렬 프로그래밍 모델에 관해 연구를 진행하였다. 첫 번째 연구로 하스켈의 병렬 프로그래밍 모델 중 공유 메모리를 기반으로 하는 Eval 모나드를 대상으로 확장성을 실험하였으며 그 결과는 다음 그림 1과 같다.
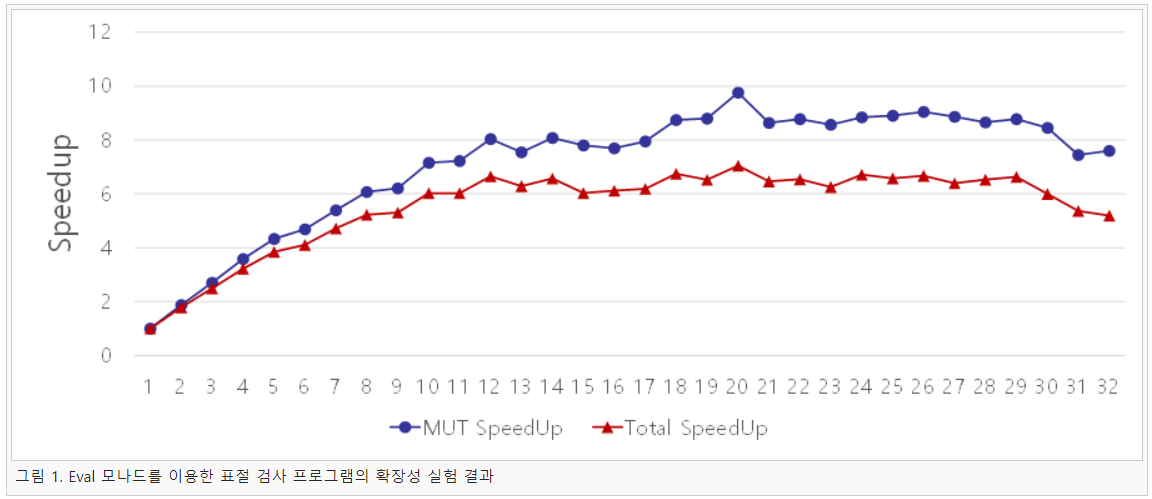
그림 1은 Eval 모나드를 이용하여 표절 검사 프로그램을 작성한 뒤 81개의 Java 코드를 대상으로 표절 검사를 수행한 결과이다. 그림 1에서 MUT SpeedUp은 하스켈 프로그램에서 실제 계산에만 사용된 시간만 고려하여 속도 상승을 측정한 결과이며 Total SpeedUp은 초기화 시간과 GC 시간을 포함한 전체 실행 시간을 이용하여 측정한 속도 상승 결과이다. 프로그램 실행 결과를 살펴보면 코어 10개 이후로는 확장성에 병목 현상이 발생하고 있으며 이는 프로그램의 속도 상승 한계 및 GC에 걸리는 시간이 줄어들지 않기 때문에 발생한 것으로 추정된다.
두 번째 연구로는 병렬 프로그래밍 모델 중 액터 모델에 관해 연구를 진행하였다. 액터 모델은 Erlang에서 이용하고 있는 모델로 각 액터가 고유의 메모리 공간을 가지고 다른 액터와 연결하기 위해서는 메시지를 이용하여 공유 메모리가 존재하지 않는 특징을 지니고 있다. 하스켈에서는 Cloud Haskell을 통해 액터 모델을 제공하고 있으며 본 연구에서는 이를 이용하여 표절 검사 프로그램을 구현하였다. 그리고 두 모델 간의 성능을 비교한 결과는 그림 2, 3과 같다.
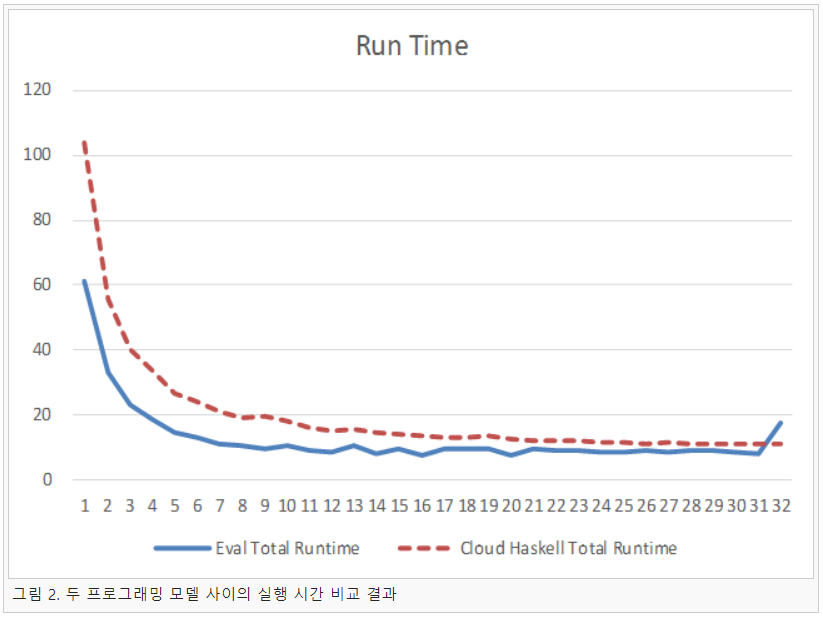
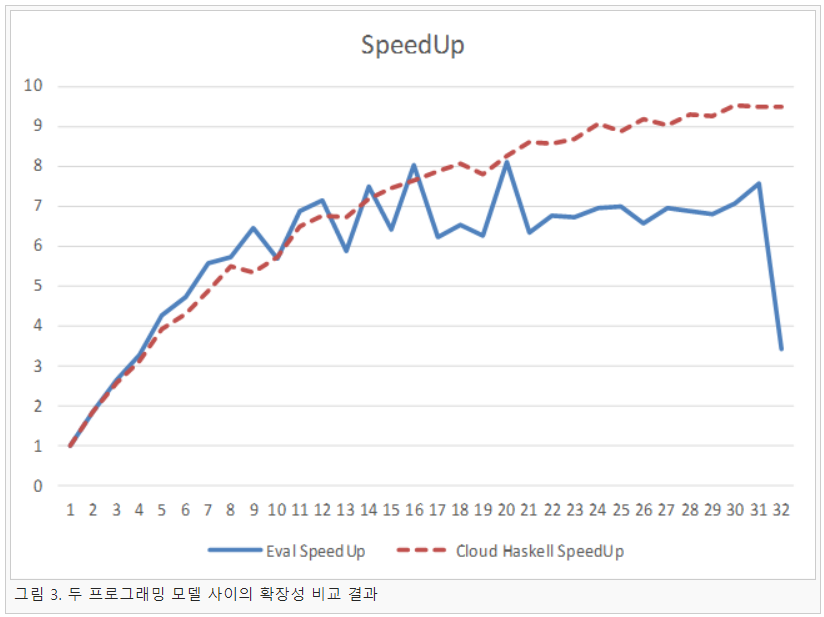
두 프로그래밍 모델 사이의 실행 시간은 그림 2와 같이 측정되었다. 1개의 코어에서는 Eval 모나드를 이용한 방법이 Cloud Haskell을 이용한 방법보다 약 2배가량 실행 시간의 차이가 나타났지만, 코어 수가 늘어남에 따라 그 차이는 점차 줄어드는 것으로 나타났다. 그리고 두 모델 간의 확장성을 비교한 결과는 그림 3과 같이 나타났다. 그림 3과 같이 Cloud Haskell이 Eval 모나드보다 확장성이 우수한 것으로 나타났으며, 이는 Cloud Haskell이 노드마다 개별 GC를 실행하기 때문에 코어가 늘어남에도 확장성이 유지되는 것으로 추정된다.
위의 실험 결과인 그림 3의 Eval 모나드 SpeedUp 그래프에서 볼 수 있듯이 실행에 사용되는 코어 수가 늘어남에 따라 확장성이 보장되지 않고 성능 증가의 변동성이 크게 요동치는 것으로 나타났다. 이는 하스켈이 GC를 사용하는 가상머신 위에서 동작하기 때문에 GC에 사용되는 시간에 많은 영향을 받기 때문인 것으로 추정된다. 따라서 세 번째 연구로 GHC의 GC 튜닝에 대한 연구를 진행하였다. 먼저 그림 3의 Eval 모나드 실험 결과를 분석한 결과 10, 13, 15, 17, 18, 19, 20, 23개의 코어를 사용한 부분에서 성능 증가의 변동 폭이 크게 요동치는 것으로 나타났다. 따라서 이 8가지의 코어 환경을 바탕으로 GHC에서 제공하는 GC-TUNER를 사용하여 최적의 GC 옵션인 –A, -H를 표 1과 같이 구할 수 있었다.
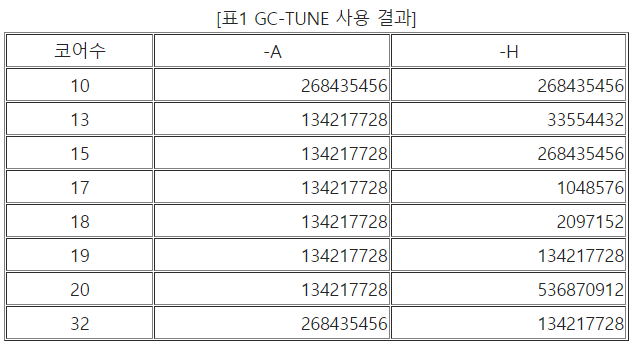
GHC는 여러 가지 GC 중 세대별 GC을 주로 사용하는데 –A옵션은 가장 어린 세대를 위한 힙 메모리 설정 옵션이고 –H옵션은 GC에 사용되는 전체 힙 메모리 설정 옵션이다. 표 1에서 구한 최적의 GC 옵션을 바탕으로 GHC에서 다시 실행한 결과는 그림 4와 같다.
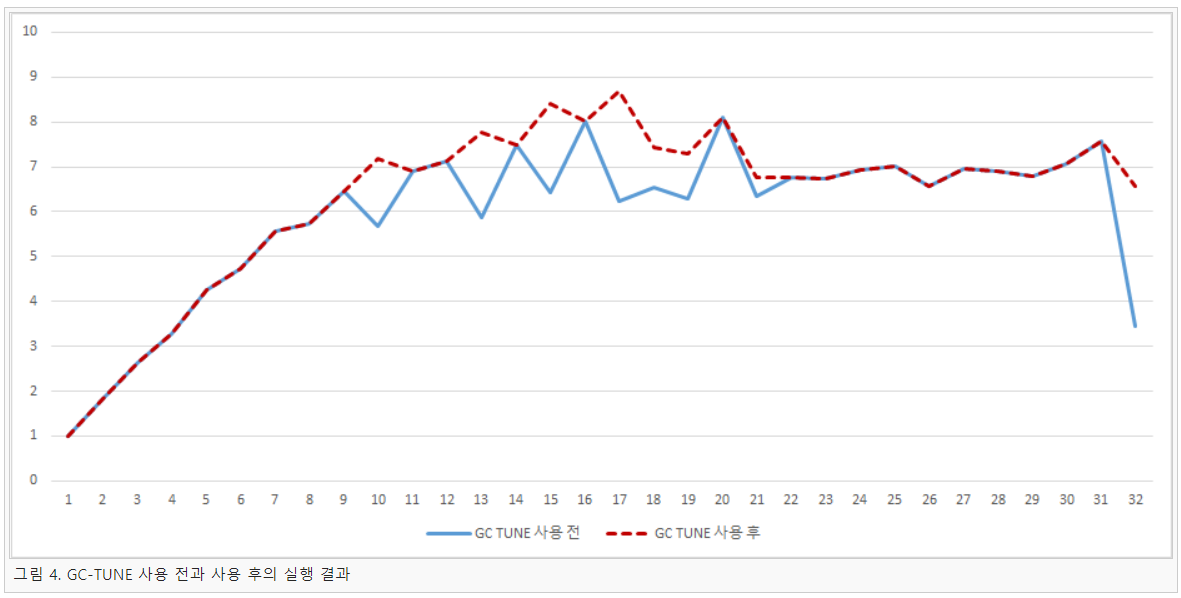
그림 4는 GC-TUNE을 사용하기 전과 사용한 후의 초기 SpeedUP을 측정한 결과 이다. 실험결과 어느 정도 변동 폭이 줄어든 그래프를 얻을 수 있었다. 특히 32코어에서 GC-TUNE의 사용 전과 후의 결과 그래프를 비교했을 때 훨씬 좋은 결과를 얻을 수 있었다. 그림 5는 GC-TUNE을 사용하여 얻을 결과를 바탕으로 각각 10번의 반복실행을 통해 평균을 계산한 결과 이다.
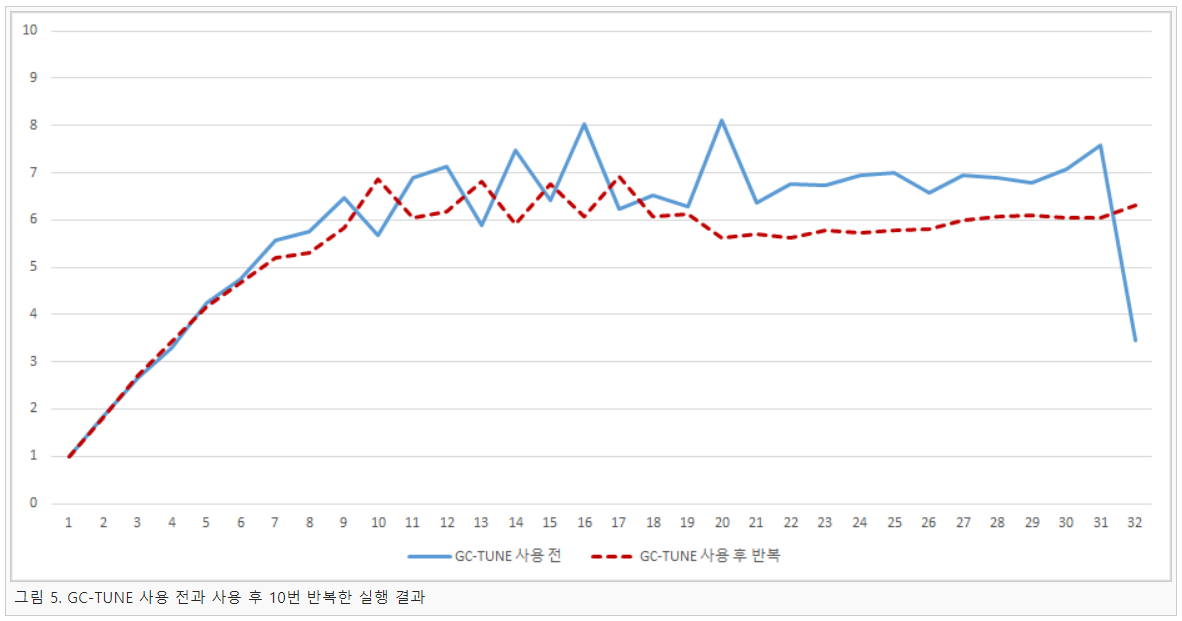
그 결과 전체적인 SpeedUp 기울기는 다소 낮아졌지만 어느 정도 완만한 모양의 그래프를 얻을 수 있었다. 그림 5의 결과를 바탕으로 성능 변동 폭이 생긴 11, 14, 16개의 코어를 사용한 부분은 GC-TUNE을 사용하여 GC 최적화를 통하면 변동 폭이 줄어들 것이라고 예상할 수 있다. 또한 실행 SpeedUp이 감소하는 부분만을 이용하여 변동 폭의 차이를 계산해 본 결과 GC-TUNE을 사용한 그래프다 사용하지 않은 그래프보다 약 34%의 변동 폭이 감소한 것을 확인할 수 있었다.
종합적으로 본다면 매니코어 환경에는 Eval 모나드보다 Cloud Haskell을 사용하는 것이 유리하다. 즉 확장성 측면의 성능만을 논하자면 Cloud Haskell을 사용해야 하지만 코딩 편의성까지 고려한다면 Eval 모나드가 유리할 수 있다. 이는 Cloud Haskell이 병렬 코딩을 위해 별도의 코드를 작성해야 하기에 발생하는 문제이다.
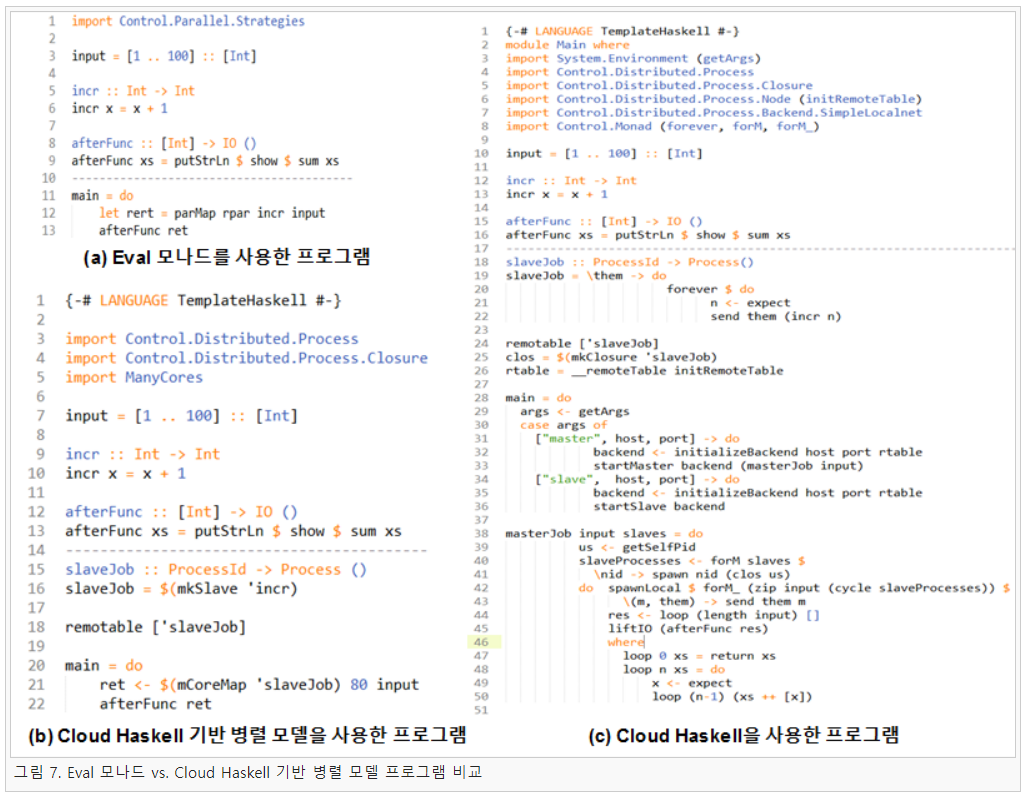
본 연구에서는 코딩 편의성이 떨어지는 Cloud Haskell을 개선하여 Eval 모나드와 Cloud Haskell의 장점을 합친 Cloud Haskell 기반 병렬 모델을 개발하였다. 이 병렬 모델은 Eval 모나드와 유사하게 손쉽게 병렬 코딩을 할 수 있으면서 Cloud Haskell의 확장성을 확보한 것이다. Cloud Haskell 기반 병렬 모델의 병렬화 개념은 그림 6과 같다.

Cloud Haskell 기반 병렬 모델은 그림 6의 (c)와 같이 병렬 프로그래밍을 하는 것을 목표로 한다. 기존 Eval 모나드의 경우 병렬 고차 함수인 parMap을 이용하여 간단하게 병렬 프로그래밍을 할 수 있다. 반면에 Cloud Haskell의 경우 병렬로 동작할 함수를 별도의 마스터/슬레이브 방식의 함수로 새로 작성하여야 병렬로 동작할 수 있다. 두 경우를 비교해보면 Eval 모나드가 Cloud Haskell보다 새로 프로그램을 작성할 때나 기존 프로그램을 병렬 프로그램으로 변경할 때 유리하다. 즉 본 연구에서 개발하고자 하는 Cloud Haskell 기반 병렬 모델은 매니코어 환경에서 Eval 모나드와 같이 Cloud Haskell을 사용할 수 있도록 하고자 한다.
Cloud Haskell은 분산 컴퓨팅 환경에 초점이 맞춰져 있으므로 매니코어 환경에서는 코딩 편의성 이외에도 몇 가지 문제점이 존재하는데 이는 아래와 같다.
-
마스터/슬레이브 실행 함수(ex. startMaster)로 인해 프로그램의 부분 병렬화가 어려움
-
프로그램을 별도로 실행해야 함 (ex. 슬레이브 별도 실행 -> 마스터 실행)
Cloud Haskell 기반 병렬 모델에서는 코딩 편의성과 함께 위 두 가지 문제점도 아울러 개선하였다. 이를 이용해 프로그램을 개발한 코드를 비교하면 그림 7과 같다.
그림 7의 코드는 Haskell을 이용하여 1에서 100 사이의 배열에 1을 더하고 총합을 출력하는 프로그램이다. 그림 7의 (a)와 같이 Eval 모나드로 작성한 프로그램의 경우 LoC가 9이며 기본 로직을 제외한 병렬화 부분도 보통의 Haskell 프로그램과 거의 유사한 것을 알 수 있다. 그리고 그림 7의 (c)와 같이 Cloud Haskell을 이용하여 작성한 프로그램의 경우 LoC가 43으로 slaveJob을 통해 슬레이브가 어떻게 동작하고 masterJob을 통해 마스터가 어떻게 동작하는지를 작성해야 된다. 하지만 그림 7의 (b)와 같이 Cloud Haskell 기반 병렬 모델을 이용해 프로그램의 경우 LoC가 15로 슬레이브에서 동작할 함수를 넘겨주는 작업과 실행할 함수를 remotetable을 통해 정의하는 부분 이외에는 Eval 모나드 프로그램과 거의 유사한 것을 확인할 수 있다.
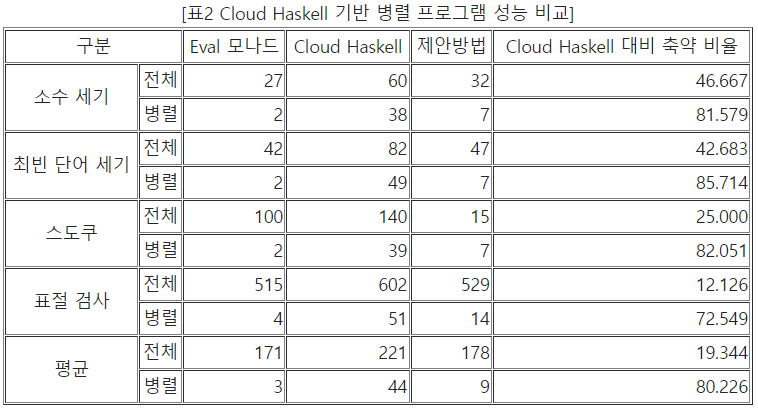
즉 그림 7과 같은 코드의 경우 기존 Cloud Haskell 대비 코드 사이즈를 65% 축약한 것을 확인할 수 있다. 그리고 본 연구에서는 4종의 병렬 프로그램을 대상으로 Cloud Haskell 기반 병렬 모델을 적용한 결과, 표 2와 같은 결과를 얻을 수 있었다.
SAM 모델 개선을 위한 연구
본 연구에서는 SAM 성능향상을 위한 연구를 위해 하스켈 STM(software transactional memory) 구조에 대한 연구를 진행하였다. SAM은 노드 간의 통신을 위해 소켓 통신을 사용하기 때문에 공유 메모리 환경에서 오버헤드가 존재한다. 이를 해결하기 위해 노드 간 통신 채널을 개선해야 하는데 본 연구에서 선택한 방법은 하스켈의 lock free 구조인 STM을 통신 채널로 사용하는 방법이다.
STM은 병렬 컴퓨팅을 위한 모델로 DB에서 사용되고 있던 트랜잭션(transaction) 개념을 공유 메모리상의 동시성 프로그램 작성에 적용한 것이다. STM은 기본적으로 각 병렬 단위마다 개별적 메모리 공간을 가지고 내용을 작성하게 된다. 그리고 작성된 내용을 공유된 공간에 업데이트하는 경우 버전 검사를 통해 업데이트 가능 여부를 확인하고 업데이트를 수행하는 방법이다. 만약 충돌이 발생하거나 업데이트가 불가능한 경우 처음부터 다시 시도하는 방법을 채택하고 있다. 그리고 현재 STM은 다양한 언어에서 라이브러리 형태로 제공하고 있지만 가장 널리 알려지고 범용적으로 사용되고 있는 언어는 하스켈이다.
하스켈 STM이 가장 널리 사용되는 이유는 몇 가지 장점이 있기 때문이다. 우선 하스켈 STM은 모나드를 이용하여 작성되었는데, 모나드를 이용한 경우 하스켈의 강력한 타입 시스템으로 쓰레드가 트렌잭션 안에서만 공유 자원에 접근할 수 있게 된다. 그리고 하스켈은 GHC 컴파일러 런타임 시스템 차원에서 STM을 지원하기 때문에 다른 언어보다 효과적으로 STM을 사용할 수 있다. 또한 하스켈 STM은 처음 설계 시 operational semantics를 정의하여 구현하였기 때문에 의미가 명확하게 구현되어 있다. 이외에도 하스켈은 다른 언어보다 런타임 시스템 규모가 작기 때문에 STM을 쉽게 수정해볼 수 있어 연구에 적합하다.
하지만 기존 연구에 의하면 하스켈 STM이 매니코어 환경에서 한계점이 있다는 보고가 존재한다. 해당 연구에서 언급한 문제점 중 본 연구와 관련이 있는 문제점은 아래와 같다.
- 하스켈 TM 문제
- 하스켈 GC 문제
- 아키텍처의 문제
하스켈 TM 문제는 로컬 자원의 내용을 공유 자원으로 commit 단계에서 성능 저하가 발생하는 문제이다. 이는 예전 GHC에서는 commit 단계에서 coarse-grained 락을 이용하여 충돌이 발생하지 않는 부분에서도 병렬 처리가 불가능하였던 문제점이다. 하지만 최근 GHC에서는 이를 fine-grained 락 기반으로 변경하여 일정 부분 해결된 것으로 알려져 있다. 다음으로 GC 문제는 코어가 늘어남에 따라 높은 메모리 사용으로 인해 힙과 스택 사이에 불필요한 전송이 늘어나게 되는 문제와 STM 연산 재시도 시 점프 대상 주소가 자주 변경되어 분기 예측 실패로 인한 GC 성능 저하 문제이다. 마지막으로 아키텍처 문제는 NUMA 환경에서 STM 이용 시 쓰레드 위치에 따른 스케줄링 이슈를 의미하는 것으로 NUMA 환경의 특성상 다양한 위치에서 쓰레드가 발생할 수 있기 때문에 나타나는 문제이다.
본 연구에서는 최근 GHC STM이 매니코어에서 성능 확보 문제가 많은지를 판단하기 위한 실험을 진행하였다. 실험에 사용된 프로그램 STM 벤치 마크 프로그램으로 연결 리스트 프로그램과 레드-블랙 트리를 실험에 사용하였다. 실험환경은 인텔 KNL 64코어 단일 노드 환경에서 진행하였다. 그리고 실험 결과는 그림 8, 9와 같이 나타났다.
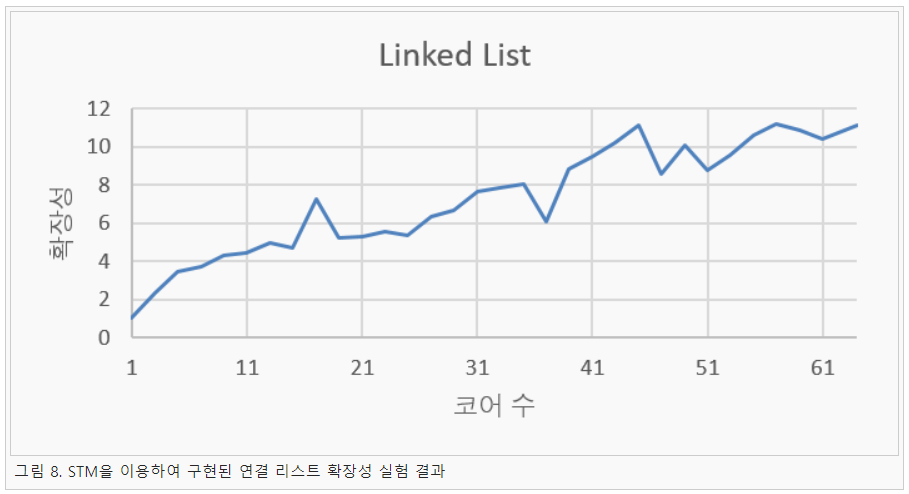
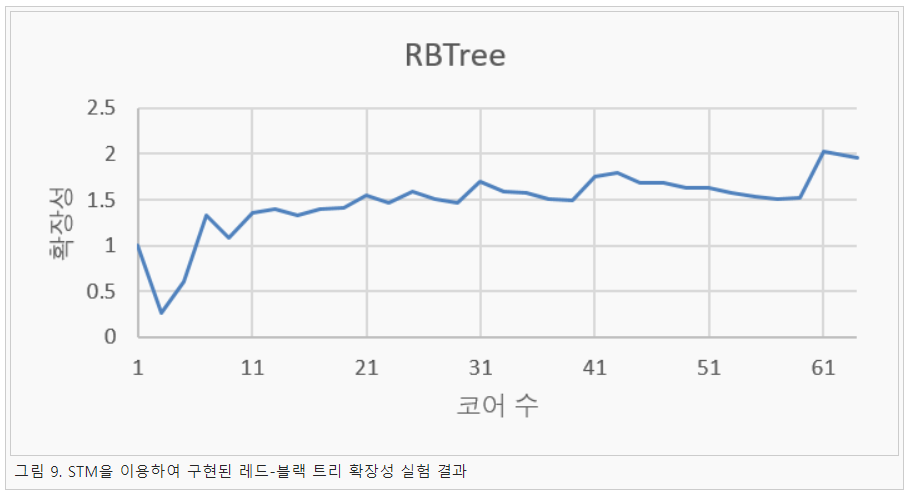
실험 결과 연결 리스트는 매니코어 환경에서 확장성이 확보되는 것을 알 수 있다. 하지만 레드-블랙 트리는 확장성이 거의 보이지 않으며, 심지어 작은 코어에서는 단일 코어 환경보다 느리게 동작하는 것을 확인할 수 있었다. 이는 레드-블랙 트리의 특징 때문으로 노드를 이동 시 발생하는 밸런싱 작업으로 인해 트랜잭션이 지속적으로 충돌하기 때문에 발생하는 문제점으로 판단된다. 즉 매니코어 환경에서 STM은 확장성은 보이지만 응용 선택이 중요한 것을 알 수 있다. 그리고 향후 SAM에서 STM을 사용 시 채널의 역할로 이용할 것이며, 이는 연결 리스트에 가까운 형태로 예상된다. 그렇기 때문에 SAM에 STM을 사용하여도 확장성이 확보될 것으로 판단된다.
그리고 본 연구 에서는 SAM의 소켓 통신 문제를 해결하기 위해 Cloud Haskell의 통신 채널을 변경하는 연구를 진행하였다. SAM의 내부 동작은 Cloud Haskell으로 구현되어 있다. 그리고 Cloud Haskell은 기본적으로 모든 메시지 전달이 소켓 통신을 이용하고 있다. 즉, 단일 노드의 매니코어 환경에서 프로그래밍하여도 오버헤드가 존재한다.
이를 해결하기 위해 본 연구에서는 메시지 전달을 소켓이 아닌 공유 메모리 환경인 STM을 이용하는 방법을 연구하였다. 앞에서 언급한 바와 같이 STM이 Haskell에 SAM의 통신 채널에 사용하기에 적합한 것으로 연구되었기 때문에 본 연구에서는 이를 구현하기 위해 network-transport-inmemory 라이브러리를 이용해 SAM의 구조를 변경하였다. 본 연구에서 개발한 STM 채널을 이용하는 SAM은 SAMSTM이라 이름지었다. 그리고 기존의 소켓의 사용하는 SAM은 향후 SAMSoc라 부르기로 하였다. 그리고 새롭게 개발된 SAMSTM와 SAMSoc과 구조를 비교하면 아래 그림 10과 같다.
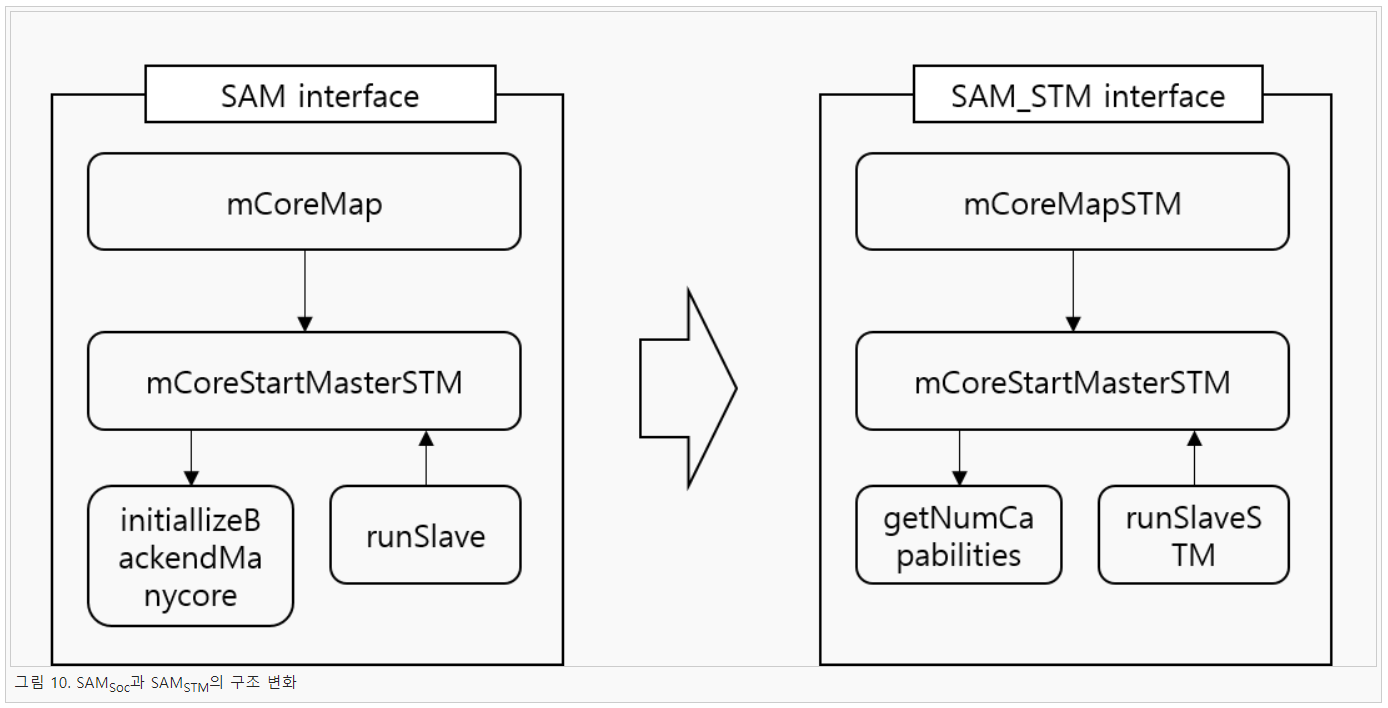
SAMSTM은 응용 프로그램에서 mCoreMapSTM 함수를 호출하면 mCoreStartMaster 함수를 내부적으로 호출한다. 이는 기존 Soc의 방식과 큰 차이가 없다. 다만 기존 Soc은 슬레이브의 수를 별도로 입력해주어야 했지만 SAMSTM은 getNumCapailities 함수를 이용해 실행할 슬레이브의 수를 알아낸다. 그리고 Soc은 네트워크를 사용하기 때문에 Backend를 만들기 위해 initializeBackendManycore 함수를 호출해야 됬지만 SAMSTM은 필요없다. 이후 두 모델 다 슬레이브를 실행하기 위한 함수를 호출하여 실제 계산에 들어가게 된다. 본 연구에서는 SAMSTM의 성능을 평가하기 위해 매니코어 환경 중 비교적 코어가 적은 환경인 32코어 환경에서 실험을 진행하였다. 비교 대상으로는 적은 코어에서 우수한 성능을 보이는 Eval 모나드와 SAMSoc을 비교하였다. 그리고 실험 결과는 그림 11과 같이 나타났다.
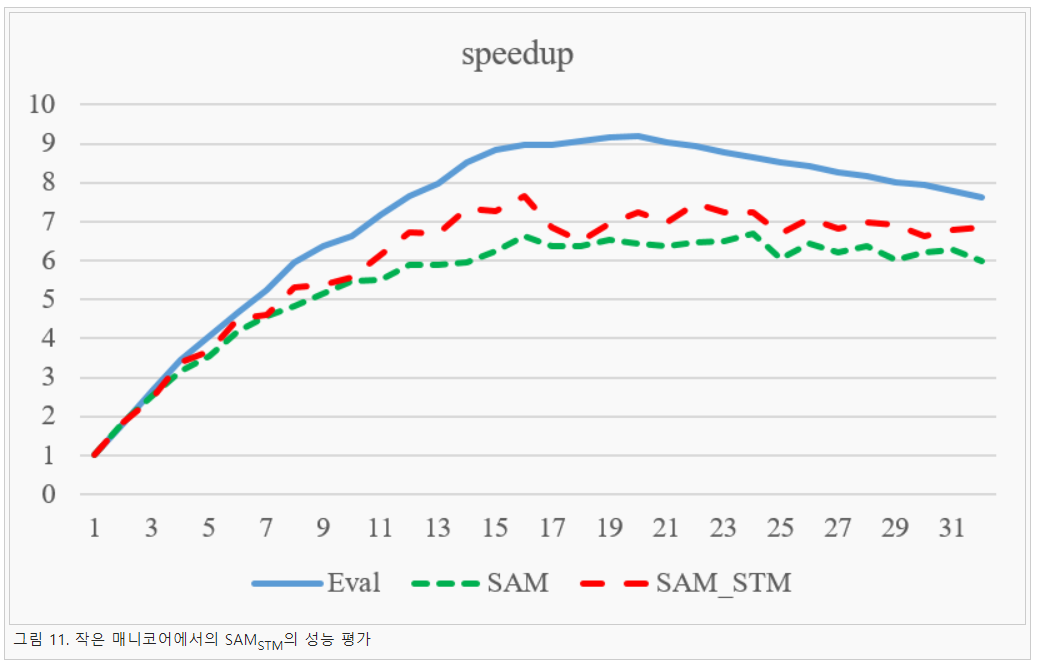
실험 결과를 살펴보면 Eval 모나드의 확장성이 가장 높은 것을 알 수 있다. 다음은 SAMSTM의 확장성이 높으며, SAMSoc은 세 모델 중 확장성이 가장 낮을 것을 알 수 있다. 이는 매니 코어 환경 중 비교적 코어가 낮은 32코에서 실험을 진행하였기 때문이다. 실제 120코어 환경에서 50코어가 넘어가면 SAMSoc의 성능이 더 좋아지는 것을 알 수 있다[7]. 실험 결과를 자세히 살펴보면 32코어를 기준으로 Eval 모나드는 7.63의 확장성을 보인다. 그리고 SAM은 5.99의 확장성을. SAMSTM은 6.84의 확장성을 보이는 것을 알 수 있다. 즉 SAMSTM은 Eval 모나드보다는 느리지만 SAMSoc보다 약 14% 확장성이 올라간 것을 알 수 있다.
위와 같이 SAM은 코어 환경마다 적합한 모델을 사용하면 우수한 성능을 보이는 것을 확인할 수 있다. 이는 두 모델의 메시지 전달 채널과 프로세스 실행 모델이 다르기 때문에 발생하는 차이점이다. 즉, 상황에 맞는 SAM을 선택하는 것이 중요하다. 하지만 이는 불편한 방식이며 하드웨어에 종속적인 프로그램 개발이라는 문제점이 있다. 그렇기 때문에 본 연구에서는 두 SAM 모델의 장점만을 합친 모델인 SAMShm을 개발하였다. SAMShm은 다양한 리눅스 IPC 중 속도가 빠르다고 알려진 공유 메모리(shared memory)를 메시지 전달 채널로 사용하고 슬레이브 실행은 OS 프로세스를 사용하는 모델이다. 즉, SAMSoc와 마찬가지로 OS 프로세스를 사용하기 때문에 코어 수가 올라가더라도 GC 문제가 적으면서, 공유 메모리를 사용하여 소켓 생성에 필요한 오버헤드가 줄어들기 때문에 어떤 상황에도 우수한 성능이 보장된다. 하지만 이와 같은 공유 메모리는 Haskell에서 바로 사용할 수 없는 문제점이 있다. 이는 공유 메모리가 리눅스 커널 영역에 공유되는 공간을 이용하여 프로세스 사이에 데이터를 주고받을 수 있는 방법이기 때문이다. 즉 Haskell에서 공유 메모리를 사용하기 위해서는 시스템 함수(C 함수)를 사용할 수 있어야 되기 때문에 SAMShm에서는 FFI(foreign function interface)를 사용하여 시스템 함수를 래핑하였다. 이와 같이 구현된 SAMShm은 그림 12와 같다.
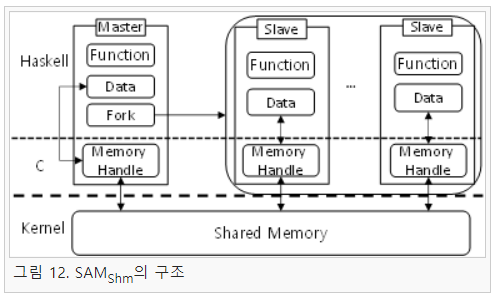
그림 12는 SAMShm의 구조를 도식화한 것이다. 구조를 살펴보면 앞서 언급한 바와 같이 Haskell에서 C로 데이터를 전달하여 커널 영역의 공유 메모리에 저장하는 것을 알 수 있다. 이는 이전 SAM과 달리 다양한 계층을 이용하여 메시지 전달 채널을 구현한 것이지만 C 함수를 이용하고 하나의 메모리 안에서 이루어지는 연산이기 때문에 오버헤드가 작은 것이 특징이다. 이외에 마스터 노드가 fork 함수를 이용하여 슬레이브를 실행하고 슬레이브에서 계산을 수행 후 다시 마스터에 결과를 넘기는 과정은 이전 SAM과 동일하다. 또한, SAMShm에서는 공유 메모리를 사용하지만 락 사용을 최소화하는 구조로 설계되었다. 공유 메모리를 사용하는 경우 여러 프로세스가 메모리에 동시에 접근하고, 메모리에 데이터를 쓸 수 있기에 데이터 무결성을 위해 락이 필요하다. 하지만 매니코어 환경에서 락은 성능 저하를 유발하는 요인 중 하나이기 때문에 락 사용은 메시지 전달 오버헤드를 증가시킬 수 있다. 그렇기 때문에 본 연구에서는 공유 메모리를 사용하면 발생하는 락(lock) 처리의 오버헤드를 최소화하기 위해 SAMShm에서는 그림 13과 같은 자료 구조를 채택하여 처리하고 있다.

그림 13은 SAMShm에서 채택하고 있는 자료 구조이다. 공유 메모리의 특성상 데이터 무결성을 위해서는 같은 공간에 쓰기 연산을 사용하는 경우 락이 필요하다. 즉, 데이터를 읽거나 다른 공간에 쓰는 것이 확실하다면 락이 필요하지 않는다. 이 때문에 SAMShm에서는 항상 데이터를 마지막에 추가하는 방식으로 자료 구조를 설계하여 락 사용을 최소화한다. 자세한 구조를 살펴보면 SAMShm은 Last 변수에 공유 메모리의 마지막 위치를 저장한다. 이는 데이터 추가 시 오버헤드를 줄이기 위한 변수이다. 그리고 Count는 공유 메모리에 저장된 데이터의 수를 나타내는 값이며, 마스터 노드에서 슬레이브 노드의 연산 종료를 기다리는 변수이다. Data는 실제 데이터가 저장되는 영역으로 Haskell 데이터는 ByteString 형태로 저장되기 때문에 가변적인 길이를 가지게 된다. 그렇기 때문에 처음에는 Data의 길이를 알 수있는 Length를 저장하고 이후에 해당 값이 몇 번째 위치인지를 저장하는 변수가 저장된다. 그리고 마지막으로 실제 자료는 Chunk에 저장된다. 본 연구에서는 이처럼 개발된 SAMShm의 성능을 분석하기 위해 기존 SAM과 Eval 모나드 프로그램을 대상으로 실험을 진행하였다. 실험에는 72코어 환경(Intel Xeon Phi 7290)을 사용하였으며, OS는 Fedora 22, 컴파일러는 GHC 8.0.2 버전을 사용하였다. 실험 프로그램은 Java 표절 검사 프로그램을 사용하였으며, 입력은 108개의 Java 코드를 사용하였다. 그리고 실행 결과는 그림 14, 그림 15와 같이 나타났다.
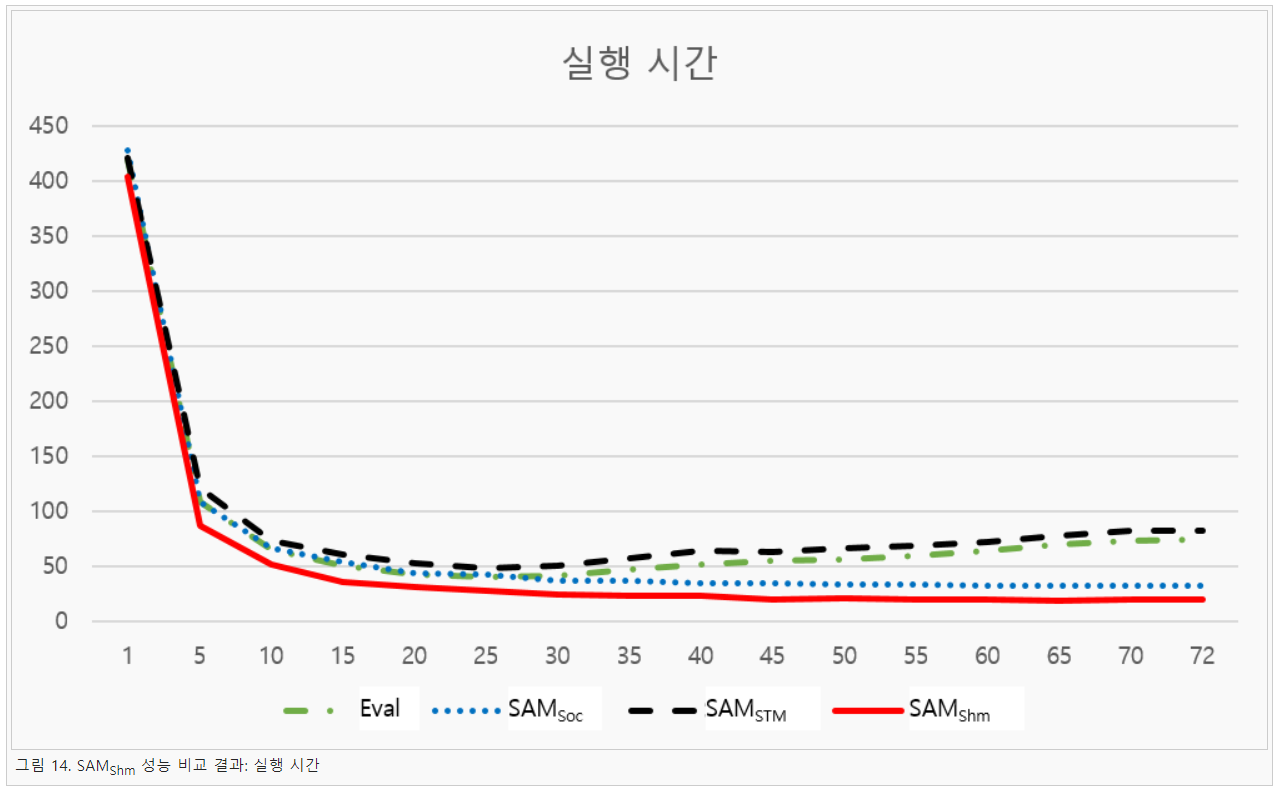
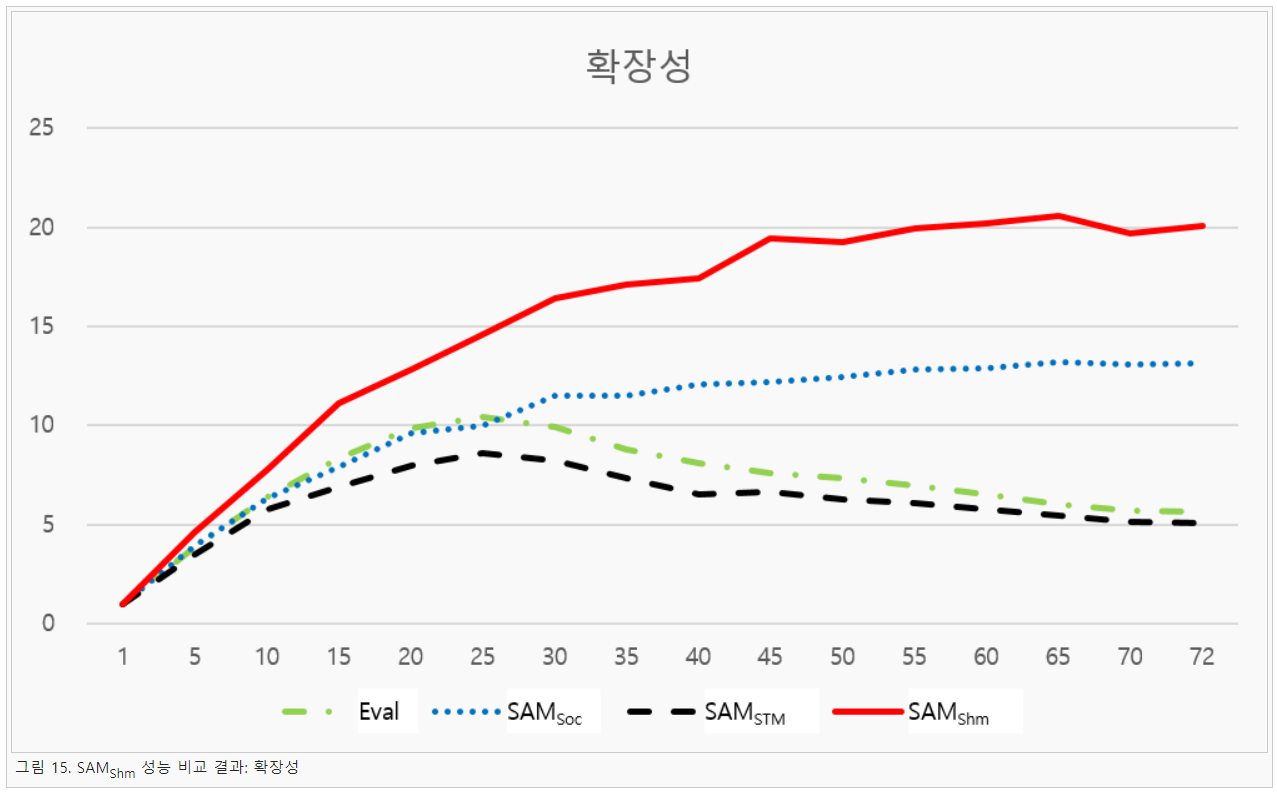
그림 14는 Eval 모나드, SAMSoc, SAMSTM, SAMShm의 실행 시간을 비교한 것이며, 그림 15는 이를 이용하여 확장성을 계산한 결과이다. 우선 실행 시간을 살펴보면 최종적으로 SAMShm이 가장 빠른 것을 알 수 있으며, 다음으로는 SAMSoc, Eval 모나드 SAMSTM은 비슷한 것을 확인할 수 있다. 이를 확장성 측면에서 살펴보면 확실하게 알 수 있는데, 72코어 기준에서 비교해보면 SAMShm의 확장성이 약 20으로 가장 높게 나타났으며 다음으로 SAMSoc가 약 13으로 나타났으며, SAMSTM과 Eval 모나드는 약 5로 낮게 나타났다. 즉, SAMShm이 SAMSoc보다 약 52% 확장성이 높게 나타났으며, SAMSTM보다 약 295% 확장성이 높게 나타났음을 알 수 있다. 즉, SAMShm을 사용하면 코어 수에 상관없이 매니코어 환경에서 쉽게 확장성을 확보할 수 있음을 알 수 있다.
분할형 운영체제를 위한 하스켈 프로그래밍 환경 분석
본 연구에서는 분할형 운영체제의 일종인 유니커널에서 하스켈 병렬 프로그램이 잘 동작하는지를 확인하고 그 성능을 알아보기 위한 연구를 진행하였다. 이를 위해 사용한 유니커널은 HaLVM(Haskell Lightweight Virtual Machine)은 Galois에서 개발한 유니커널로, 수정된 Xen 위에서 동작하는 커널이다. HaLVM은 기존 마이크로커널 기반 시스템의 한계점을 극복하기 위해 개발된 것으로 소규모 단일 용도 프로그램에 적합하며, 특히 클라우드 서비스에 유용하다고 알려져 있다.
HaLVM은 OS 프로그래밍을 순수 하스켈을 이용하여 작성하였기 때문에 POSIX와 같은 인터페이스를 제공하지 않는다. 그렇기 때문에 기존 하스켈 컴파일러를 사용하지 못하고 HaLVM에서 제공하는 halvm-ghc와 외부 패키지 설치를 위한 halvm-cabal을 이용하여 프로그램을 개발해야 한다. 그리고 HaLVM 간의 통신은 순수 하스켈로 구현된 네트워크 통신을 이용하거나 IVC(inter virtual machine communication)을 이용하여 OS 간의 통신이 이루어진다. 본 연구에서는 이러한 HaLVM의 병렬 프로그래밍 성능을 알아보기 위한 실험을 진행하였으며, 연구에 사용된 하스켈 병렬 프로그래밍 모델은 아래와 같다.
- Eval 모나드
- forkIO
- forkOS
- IVC
- Cloud Haskell
- SAM
Eval 모나드는 병렬 전략을 이용하여 병렬 프로그래밍을 하는 모델이다. 해당 모델의 병렬 단위는 GHC에서 제공하는 병렬 단위 중 가장 작은 스파크(spark)이며, 이를 기반으로 병렬 작업이 수행된다. forkIO는 하스켈 언어에서 제공하는 쓰레드를 이용하여 병렬 프로그래밍을 하는 모델이다. 이 모델의 병렬 단위는 그린 쓰레드이며, 이는 언어 수준에서 제공하는 쓰레드로 통상적으로 사용하는 운영체제 수준의 쓰레드보다 작은 단위이다. forkOS는 하스켈에서 운영체제의 쓰레드를 이용하여 병렬 프로그래밍을 하는 모델이다. 이 모델의 병렬 단위는 쓰레드이며, 사용 방법은 forkIO와 유사하지만 운영체제 쓰레드를 사용하기 때문에 큰 단위의 쓰레드가 실행된다. Cloud Haskell은 메시지 전달 기반의 병렬 프로그래밍 모델이다. 해당 모델의 병렬 단위는 프로세스이며, 노드간 메시지는 소켓을 통해 이루어진다. SAM은 맵 스타일 프로그래밍을 이용한 메시지 전달 기반의 병렬 프로그래밍 모델이다. 해당 모델의 병렬 단위는 프로세스이며, Cloud Haskell과 마찬가지로 소켓을 통해 메시지가 전달된다. 마지막으로 IVC는 HaLVM에서 제공하고 있는 유니커널간의 통신 채널로 이를 이용하여 병렬 프로그래밍을 하는 모델이다. 해당 모델의 병렬 단위는 프로세스로 Xen의 dom0를 통해 데이터를 주고받는다.
본 연구에서는 1에서 40까지의 피보나치 수를 구하는 프로그램을 기준으로 실험을 진행하였다. 즉, 위 6종의 병렬 프로그래밍 모델을 이용하여 피보나치 수를 구하는 프로그램을 병렬로 작성하였으며 실험환경은 인텔 KNL 64코어 단일 노드 환경에서 진행하였다. 실험 결과는 표 3과 같다.
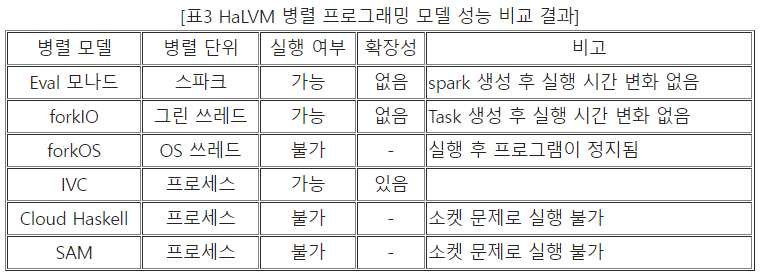
위 표의 결과를 살펴보면 현재 HaLVM에서 병렬성이 있는 것으로 나타나는 것은 IVC 뿐이다. 이는 병렬 단위가 프로세스 단위보다 작은 병렬 모델의 경우 병렬화가 제대로 이루어지지 않는 것으로 판단된다. 이 문제는 HaLVM의 구조적 문제로 판단되며 이를 해결하기 위해서는 HaLVM 구조에 대한 자세한 분석이 필요하다. 이외에 Cloud Haskell과 SAM의 경우 내부적으로 소켓 통신에서 유니캐스트 통신을 사용하는데, HaLVM의 네트워크 스택에서는 이를 지원하지 않는다. 이 문제를 해결하기 위해서는 유니캐스트 기능을 구현하거나 소켓 통신부를 IVC와 같은 내부 통신 구조로 변경할 필요가 있다. 본 연구에서는 HaLVM에서 IVC를 이용한 병렬 프로그래밍을 위한 라이브러리를 개발하였다. IVC는 VM 사이의 메시지 전달 방법이기 때문에 이를 이용하여 병렬 프로그램을 작성하기 위해서는 항상 별도로 슬레이브를 실행해야 한다. 본 연구에서는 이 문제를 해결하기 위해 그림 16과 같은 실행 모델의 라이브러리를 구현하였다.
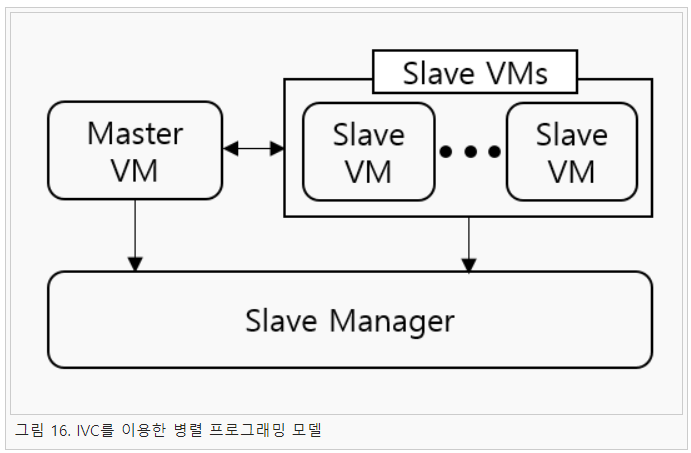
본 연구에서 개발한 라이브러리는 위와 같이 슬레이브 관리자를 두어 슬레이브를 자동으로 실행하는 방법이다. 마스터에서는 병렬로 실행할 함수가 있다면 슬레이브 매니저에게 슬레이브 실행을 요청한다. 그리고 마스터는 실행된 슬레이브와 연결하여 작업을 수행하는 방식이다. 그리고 본 연구에서는 HaLVM의 매니코어에서 확장성을 알아보기 위한 성능 실험을 진행하였다. 이를 살펴보기 위해 기존 리눅스 환경과 HaLVM에서의 Haskell 프로그램의 확장성을 비교해보았다. 실험은 기존 OS인 Fedora에서 forkOS와 Cloud Haskell 프로그램을 실행하여 비교하였다. 해당 실험 결과는 그림 17과 같이 나타났다.
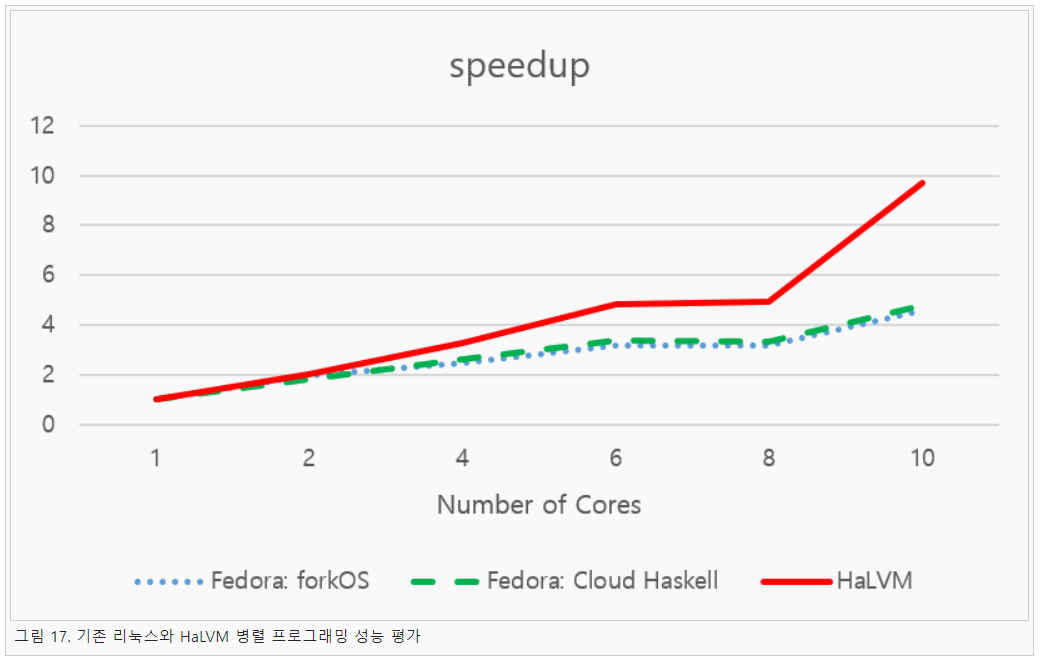
실험 결과를 살펴보면 HaLVM이 코어 수가 늘어남에 따라 확장성이 계속 증가하는 것을 확인할 수 있다. 코어가 2개인 경우 HaLVM이 Fedora 환경보다 확장성이 0.69% 더 높은 것을 알 수 있다. 코어가 10개인 경우의 확장성은 Fedora forkOS 환경에서 4.56로 나타났다. 하지만 HaLVM에서는 9.687으로 측정되어 약 112.42% 차이가 나는 것을 확인할 수 있었다. 이는 코어 수가 늘어날 때 발생하는 context switch나 커널/유저 모드 전환이 일어나지 않기 때문이다. 따라서 코어가 많은 매니코어 환경에서는 HaLVM이 유리한 것을 확인하였다.
관련 연구
다음과 같은 내용들을 기반으로 새로운 병렬 프로그래밍 모델을 추구한다.
- GHC(Glasgow Haskell Compiler)의 RTS(runtime system). 특히 Haskell의 lightweight process 및 IPC 통신 속도.
- Cloud-Haskell 및 HdpH의 구현 기술 및 응용 프로그래밍.
- 동시성 이론(concurrent theory)을 응용한 구현 방법 (Actor 및 Erlang, CSP, Pi-calculus 등)
- Function serialization 및 process migration 등
결과물
-
논문
- Data Parallel Haskell을 이용한 희소 행렬의 성능 분석
- Haskell에서 배열과 리스트의 병렬화 성능 비교
- Haskell에서 외판원 문제를 해결하기 위한 진화형 알고리즘 사용 및 평가
- Haskell을 이용한 수치해석의 효율성 연구
- 함수형 반응적 프로그램 병렬화 기법
- Yesod를 이용한 Haskell 웹 애플리케이션 개발 방법에 대한 실험
- 멀티코어 환경에서 병렬 Haskell 프로그램의 GC 성능을 측정하는 방법
- 표절 검사 기법을 이용한 Haskell의 병렬화 성능 비교
- An Approach to Improve the Scalability of Parallel Haskell Programs
- YesWeb A Concise Web Development Framework Based on Haskell
- Haskell을 이용한 병렬 프로그래밍
- Haskell의 펑터와 모나드 프로그래밍
- 분할 정복법을 이용한 HASKELL GC 조정 시간 개선.
- Haskell Eval 모나드와 Cloud Haskell 간의 성능 비교
- GC-Tune을 이용한 Haskell 병렬 프로그램의 성능 조정
- 분할 정복법을 이용한 HASKELL GC 조정 시간 개선
- An Approach to Improve the Scalability of Parallel Haskell Programs
- esWeb A Concise Web Development Framework Based on Haskell
- Haskell을 이용한 텐서플로우 프로그램의 성능 평가
- Yapures A Convenient Framework for Writing Safe JavaScript Code
- SAM A Haskell Parallel Programming Model for Many-Core Systems
- Analysis of the Parallel Programming Model in Haskell for Many-Core Systems
- 유니커널을 이용한 Haskell 병렬 프로그래밍 기법의 성능 분석
- Using SonarQube to Evaluate the Code Quality of CC++ Programming Assignments
- JNI를 이용하는 안드로이드 애플리케이션의 개인 정보 유출 탐지를 위한 정적 분석기
- 블록 프로그래밍 교육 효율을 높이기 위한 블록 라이브러리 시스템 구현
- SSAM A Haskel Parallel Programming STM Based Simple Actor Model
- An Analysis of Haskell Parallel Programming Model in the HaLVM
- Applying Code Quality Detection in Online Programming Judge
- FFI를 이용한 Haskell 병렬 프로그래밍 라이브러리
- RTBSS 실시간 블록 공유를 지원하는 블록 프로그래밍 시스템 구현
- Analyzing the Code Quality Issues in Java Programming Assignments
- API 호출 분석을 이용한 패커 분류
- 시스템 프로그래밍 언어의 크기와 수행 성능 사이의 상관관계 분석을 위한 사례 연구
- CodeHelper A Web-Based Lightweight IDE for E-Mentoring in Online Programming Courses
- 매니코어 환경을 위한 공유 메모리 기반의 Haskell 병렬 프로그래밍 모델
- QuickCheck를 사용한 neoESPA 입출력 데이터 생성 시스템
- 학습자 수준을 기반으로 한 온라인 저지 시스템의 평가 기법 분류
- 텍스트 전처리를 위한 불용어 목록의 구축
- Julia 분산-병렬 모델을 이용한 K-Means 알고리즘 최적화
-
소프트웨어
- Plagiarism Dectector
- Yesweb-blog
- Github : SAM
-
시연 영상