매니코어 스케줄링 연구
Feather-Like(FL) Scheduler
연구 배경 및 목표
현재 리눅스 운영체제의 기본 스케쥴러인 CFS스케쥴러는 task들 간의 fairness를 유지하는 것을 원칙으로 한다. 따라서 fairness를 유지하기 위한 많은 특징들이 존재한다. 그러나 매니코어 프로세서 환경에서는 충분한 코어수로 인해 fairness를 유지하기 위한 작업들이 불필요할 수 있다. 또한, high-performance computing 같은 fairness의 유지보다 성능을 더 중요시하는 환경에서는 CFS 스케쥴러의 무거운 동작이 성능 저하의 원인이 될 수 있다.
최근 발표된 논문(Jean-Pierre Lozi et al., "The Linux Scheduler: a Decade of Wasted Cores", eurosys 16)에 의하면 리눅스 CFS 스케쥴러에서 동작 가능한 쓰레드들이 runqueue에 막혀 idle 한 cpu가 발생하는 문제점이 발견되었다. 이러한 문제로 인해 실제 성능보다 14%의 성능저하가 있음이 발견되었다. 다음 그림은 위 논문에서 인용한 것으로, 리눅스 커널 컴파일 과정에서 idle한 cpu가 발생하고 있음을 보여준다.
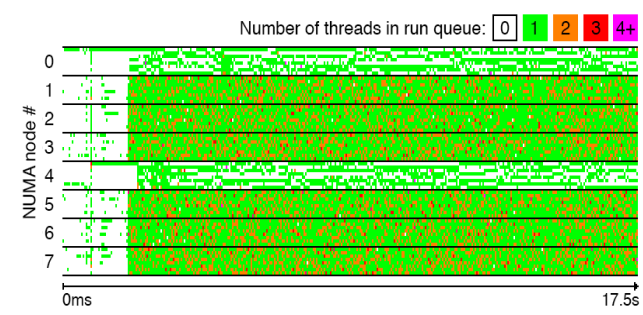
본 연구의 목표는 리눅스 운영체제의 CPU 스케쥴링 알고리즘을 개선하여 매니코어 프로세서 환경에 적합한 스케쥴러를 개발하는 것이다.
문제점
다음 표는 리눅스 운영체제의 기본 스케쥴러인 CFS 스케쥴러의 문제점을 확인하고자 Xeon Phi에서 hackbench를 수행하였을 때, 주요 스케쥴링 함수들의 수행 횟수와 평균 수행 시간을 조사한 것이다.
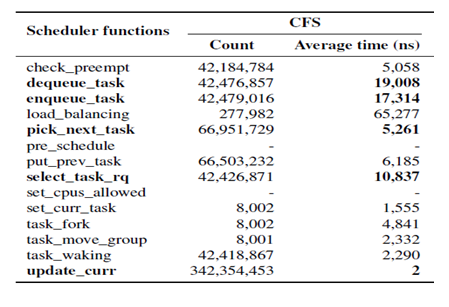
굵게 표시된 함수는 스케쥴링에 필수적으로 수행되는 함수를 의미한다. 조사한 결과에 의하면 가장 많이 호출된 함수는 update_curr 함수였으며, 평균 수행 시간이 가장 긴 함수는 load_balancing 함수였다. 이 두 함수는 task들 간의 fairness를 유지하기 위해 수행되는 함수로, 위 두 함수가 스케쥴러의 성능에 많은 비중을 차지하고 있음을 쉽게 짐작할 수 있다. 따라서 본 연구에서는 위와 같은 비용을 최소화 하는 경량화된 스케쥴러를 고안하는 방향으로 연구를 진행하였다.
연구 내용
본 연구에서는 스케쥴링 오버헤드를 최소화 하는 것을 목표로 하는 스케쥴러인 Feather-Like Scheduler(FLSCHED)를 구현하였다. FLSCHED는 기존의 리눅스 Round Robin 스케쥴러 기반의 경량 스케쥴러로, 다음의 특징을 갖는다.
- Lockless 구현
다음 표는 리눅스 커널 2.6.38 버전(Xeon Phi 공식버전)에서 lock 관련 함수가 등장한 횟수를 보여준다. 표의 CORE는 스케쥴러의 필수적인 부분에 들어가는 lock이며, CFS는 CFS 스케쥴러에 별도로 사용되는 lock, FIFO/RR은 FIFO/RR 스케쥴러에 별도로 사용되는 lock을 의미한다. 스케쥴러에서 사용되는 lock은 global한 lock은 제거되었기 때문에 per-runqueue lock을 의미한다. 리눅스 커널 4.5.4 버전에서는 각각 74, 42, 21회로 증가하였다.
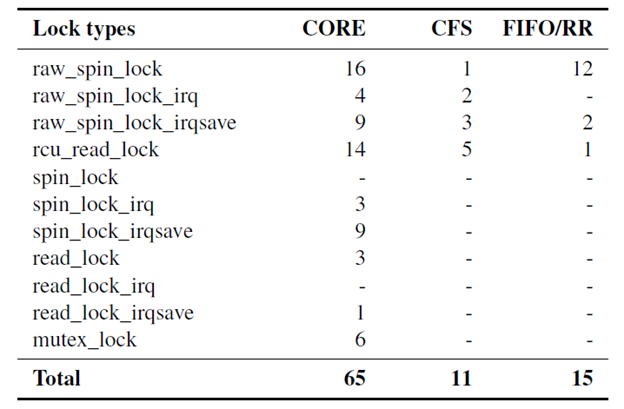
FLSCHED에서는 FIFO/RR에서 사용하고있는 15개의 lock을 모두 제거하였다. CORE에서 사용하는 lock은 여전히 남아있지만, FIFO/RR이 자체적으로 갖는 lock은 존재하지 않는다.
- Context switch 최소화
Time-slice에 의한 context switch를 제외하면 주로 선점이 발생하는 경우에 context switch가 동작하게 된다. 선점은 주로 priority에 의해 발생하는데, FLSCHED에서는 priority를 제거하여 선점을 줄였다. 다음 그래프는 AIM7 벤치마크에서 각 스케쥴러 별 수행시간과 context switch 수를 보여준다.
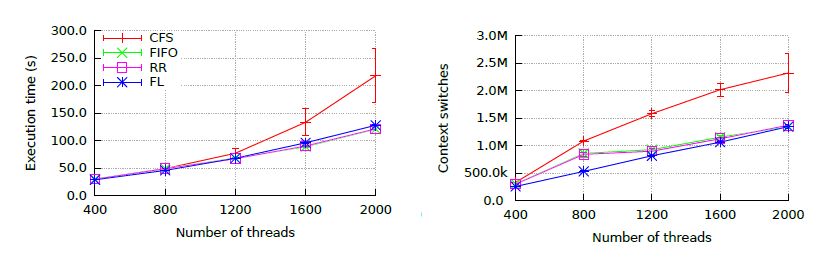
FLSCHED가 CFS 스케쥴러에 비해 최대 28%의 수행시간 감소를 보였고, context switch 횟수는 다른 스케쥴러와 비교하였을 때 가장 낮은 수치를 보였다.
- 각종 특징들 제거
FLSCHED에서는 리눅스 CFS 스케쥴러에서 많은 수행시간을 차지하였던 특징들인 load balancing이나 scheduling information(update_curr 함수)등을 제거하였다. load balancing은 주기적으로 수행되는 load balancing과 fork 같은 상황에 의해 조건적으로 수행되는 load balancing이 존재한다. FLSCHED는 주기적으로 수행되는 load balancing을 제거하여 그에 사용되는 lock도 5개 제거하였다. 그 외에도 Xeon Phi 환경에서는 불필요하다고 생각되는 여러 특징들이 제거되었다. 다음 표는 위에 hackbench로 조사한 함수 호출 횟수 및 평균 수행시간을 CFS와 FLSCHED로 비교한것이다.
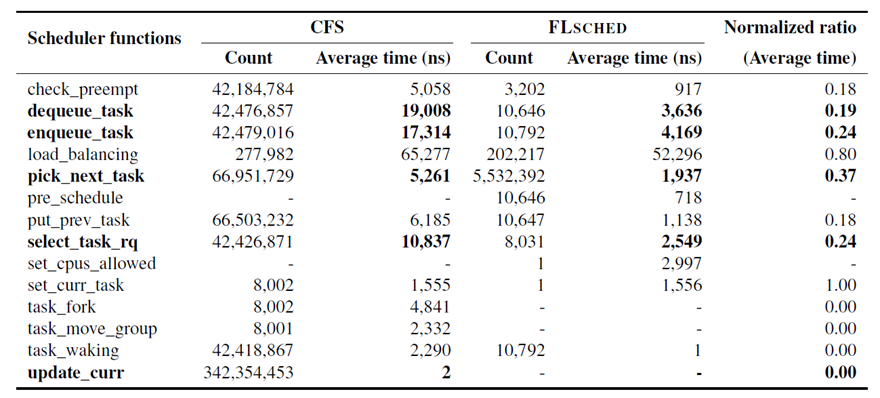
update_curr 함수가 제거되었고 load_balancing의 감소, 선점 관련 함수의 감소 등으로 인해 필수 스케쥴링 함수들도 같이 줄어든것을 확인할 수 있다. 이 결과에서 각 스케쥴러의 총 수행시간은 CFS스케쥴러의 경우 30.81초, FLSCHED의 경우 14.429초 였다.
성능 평가
본 연구에서는 High-performance computing에서의 FLSCHED의 성능평가를 위해 병렬 벤치마크 프로그램인 NPB를 사용하여 성능평가를 수행하였다. 다음 표와 그래프는 벤치마킹에 사용된 어플리케이션 종류와 성능평가 결과를 보여준다.
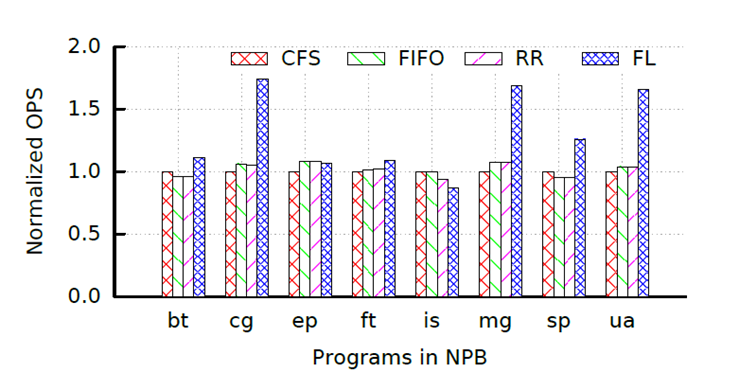
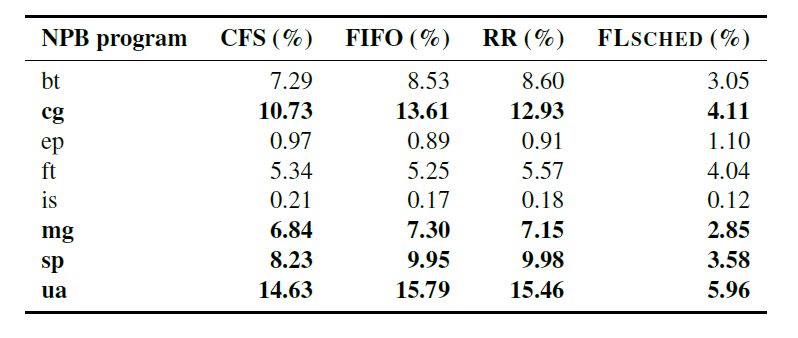
is의 경우를 제외하면 모든 경우에서 CFS스케쥴러보다 좋은 성능을 보였다. 특히 cg, mg, sp, ua의 경우는 최대 1.73배의 뛰어난 성능을 보였다. 분석결과 spinlock에 의한 병목현상이 성능에 상당부분 영향을 미쳤다. 다음은 spinlock에 의한 수행시간 비율을 나타낸 표이다.
FLsched 확장
- FLscheduler for KNL
FLsched의 확장성을 위하여 FLsched for KNL을 구현하였다. Lock을 줄이기 위해 update_curr() 및 여러 lock을 제거 하였고, priority를 제거하여 preemption을 줄여 context switch를 최소화하였다. 그 외에 주기적으로 동작하는 load balancing을 제거하여 성능 개선을 하였다.
FLsched를 적용한 KNL의 성능을 확인하기 위해 Intel(R) Xeon Phi(TM) CPU 7250 @ 1.40GHz, 68cores, 4 threads/core, 16GB HBM, 96GB memory의 KNL 머신에서 다음 그림과 같이 Hackbench와 redis, YCSB_MongoDB 벤치마크 프로그램을 사용해 테스트를 진행하였다.
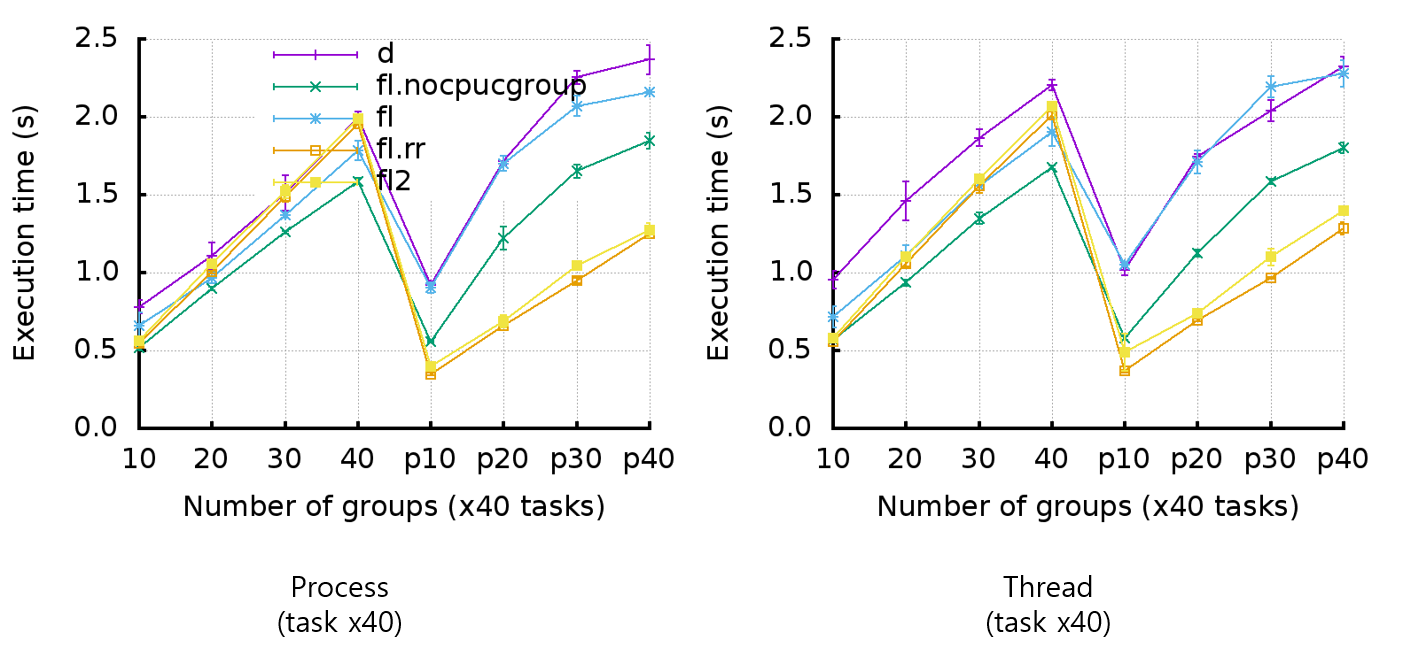
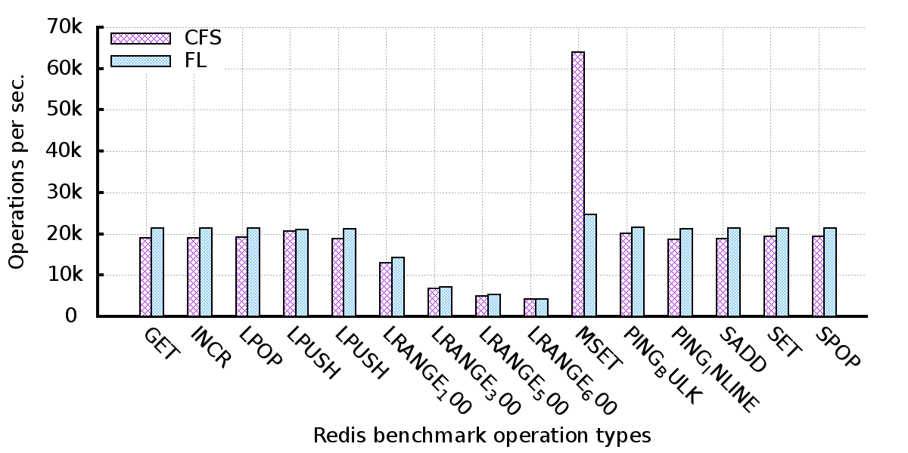
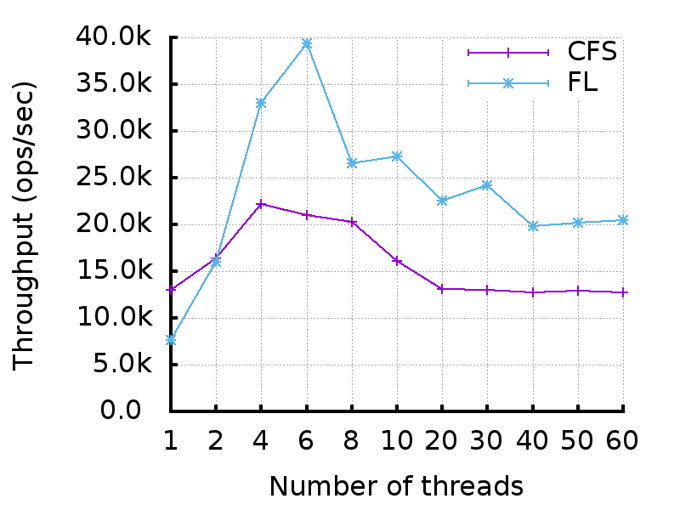
- FLscheduler for Xeon
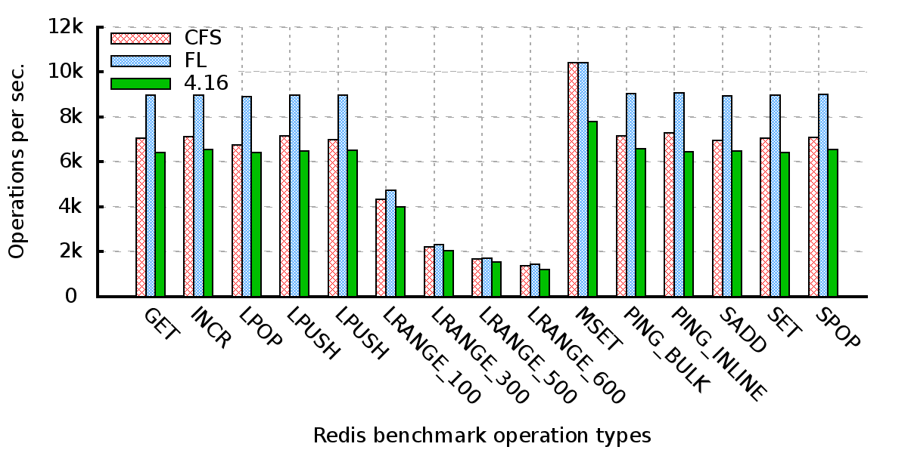
또한 기존에 구현한 FLsched 기반을 Xeon에 4.16 kernel에 포팅하였다. 그리고 성능평가를 위해 redis와 NPB와 벤치마크 프로그램 사용하여 성능 평가를 수행하였다. 실험 환경은 Intel(R) Xeon(R) CPU E5-2696 v4 @ 2.20GHz, 2 socket, 44 cores, 128GB memory의 머신에서 실행하였다. 다음의 그림들은 성능 평가 결과를 나타낸 그래프이다.
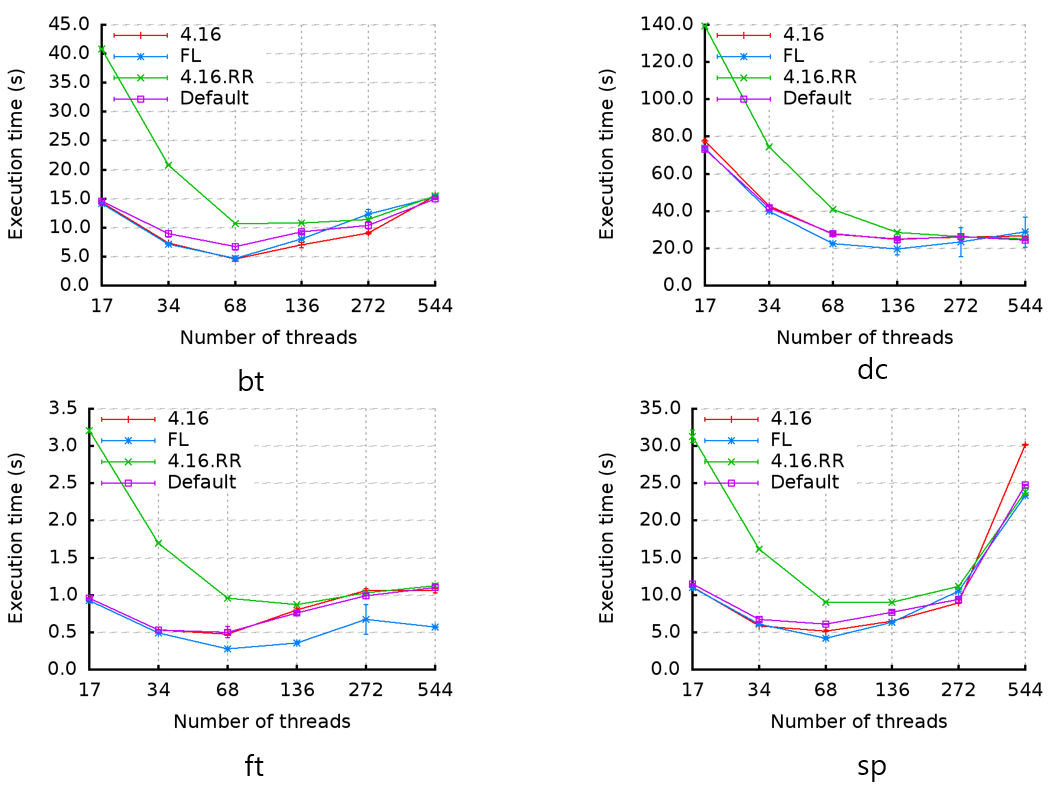
향후 계획
앞으로의 연구는 기존 FLsched 버전을 최적화 하고 CFS를 기반(NUMA awareness)으로 Xeon manycore에서 효과적으로 보이도록 개발할 예정이다. 또한 ULE를 기반으로 Lock 제거 및 최적화를 진행하여 FLsched의 차기 버전으로 발전시킬 예정이다. 이어서 스케쥴러의 CORE 부분의 lock을 줄이는 연구도 함께 진행중이다.
결과물
- 소프트웨어
- Github: flsched
- 시연 영상
스케줄러 튜너
연구 배경 및 목표
현대의 리눅스 서버들은 대규모 서버부터 소규모 IOT분야까지 다양한 방면에서 활용되고 있다. 하지만 대부분의 서버들은 자신들의 서비스를 리눅스에서 제공하는 기본 설정의 스케쥴러를 통해 제공하게 된다. 현실적으로 다양해진 현대의 리눅스 활용을 기본 OS측면에서 조율할 수 없는 문제가 존재한다. 이는 리눅스를 사용하는 멀티코어 시스템에서 역시 마찬가지로 적용되는 문제이다. 그동안 리눅스 스케쥴러의 성능을 향상시키기 위한 많은 연구가 있었다. 하지만 대부분의 경우 스케쥴링 overhead를 줄이거나 특정 상황의 job을 유리하게 처리하기 위한 우선순위 연산 수정과 같은 노력이었다. 스케쥴러의 시스템 파라미터 조정을 통한 성능 향상에 초점을 두고 연구를 진행하고자 한다.
리눅스 커널 내부에는 변수의 값을 제어하여 시스템을 최적화할 수 있는 많은 파라미터가 존재한다. 파라미터를 사용 머신과 워크로드에 맞게 값을 설정하면 성능 개선을 할 수 있지만, 사람이 모든 파라미터의 의미를 알고 각각 워크로드와 머신에 맞게 수정하는 것은 어려운 일이다. 그래서 본 연구에서는 700여 개의 커널 파라미터 중 스케줄러 성능에 영향을 미치는 14개의 파라미터를 자동으로 머신과 워크로드에 맞게 튜닝하는 연구를 진행하려 한다.
결과물
- 공개 소프트웨어
- Github: STUN
- 시연 영상