Lock-less 기법 연구
연구 방향
리눅스 커널의 확장성은 매니코어 시대에 중요한 역활을 한다. 커널의 확장성 중 메모리 관리에 대한 부분이 중요한 역할을 한다. 또한 메모리 관리의 확장성을 위해 락에 대한 분석 역시 중요하다. 따라서 락에 대한 분석이 필요한 상황이다. 락에 대한 분석을 통해 락 경합 없는 자료구조를 만드는 것이 목표이다. 본 설계에서는 락 경합에 대해서 분석한 내용을 설명하고, 락 경합을 줄이는 자료구조에 대해서 설명한다. 구체적인 연구 목표는 아래와 같다.
- 매니코어 시스템에서 Lock에 의한 성능 지연을 개선한 메모리 관리 기술 개발
- 메모리 관리 중심 벤치마크 대상 성능 Lock에 의한 성능 저하를 개선한 메모리 관리 기술 개발
- 해당 메모리 관리 기술을 적용한 리눅스 커널 패치를 오픈 프로젝트로 발표
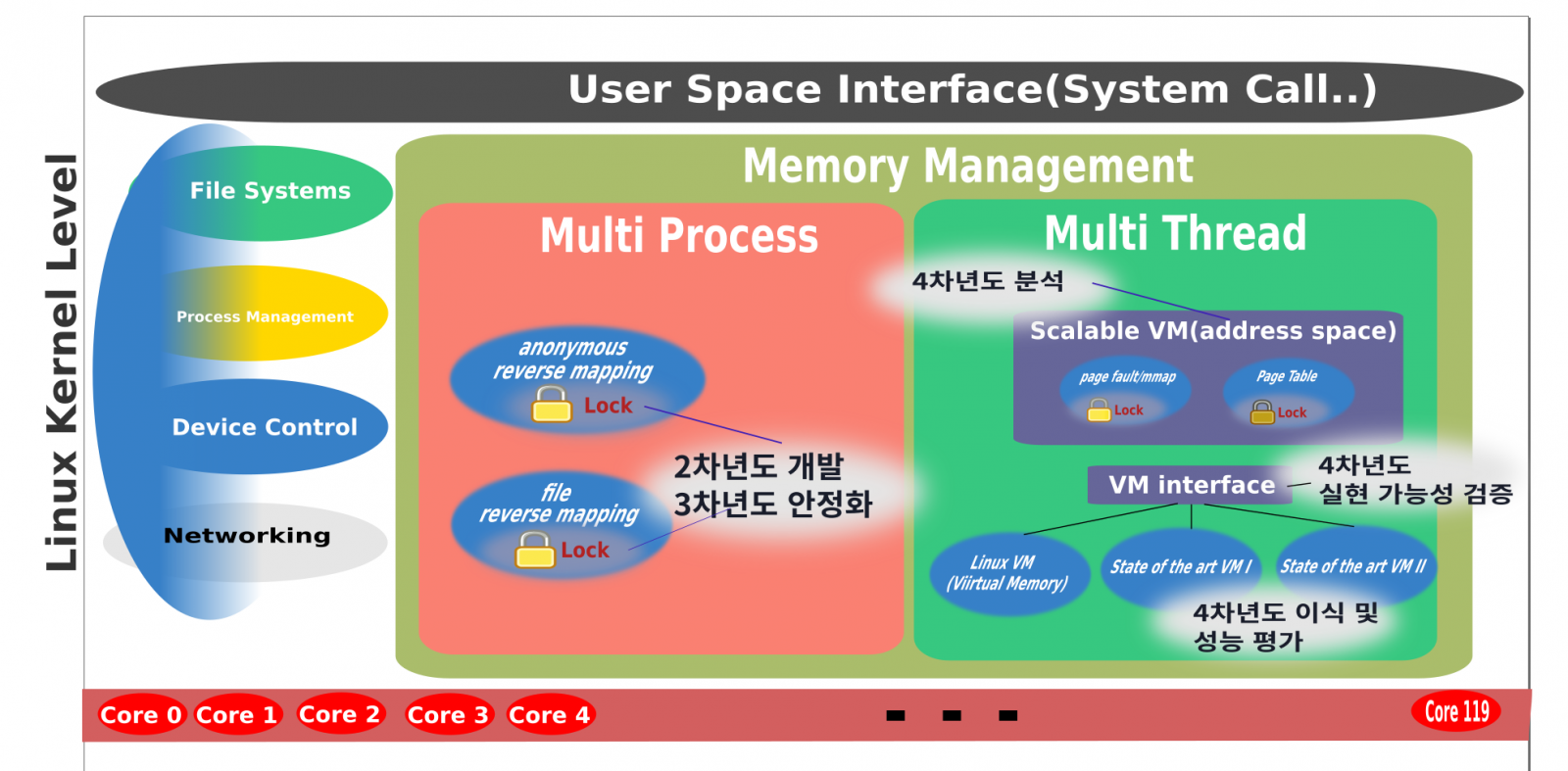
매니코어 시스템에서의 메모리 관련 문제점
- 멀티 프로세스, 쓰레드 기반 문제점 : 1~4차년도
연구 진행사항
Lightweight Log-based Deferred Update
연구 요약
본 연구는 매니코어 환경에서 리눅스 가상 메모리 관리의 확장성에 대한 문제점을 해결 하였고, 이를 위해 로그 기반의 동시적 업데이트 기법을 개발하였다. 본 연구를 통해 개발 된 기법을 리눅스 운영체제의 확장성 문제를 야기 하는 두 가지 역 매핑에 적용하였으며, 120코어를 가진 매니코어 시스템을 대상으로 실험을 하였다. 실험 결과 120코어 상에서 멀티 프로세스 기반의 벤치마크에서 1.5배의 성능 향상을 보았다. 본 기법은 앞으로 매니코어 환경에서 리눅스 메모리 관련 확장성을 향상 시키기 위해 유용하게 사용될 수 있다.
문제점은 60코어 이상에서는 확장성이 떨어진다. 그 이유는 리눅스 커널의 2가지 reverse mapping 때문이다.
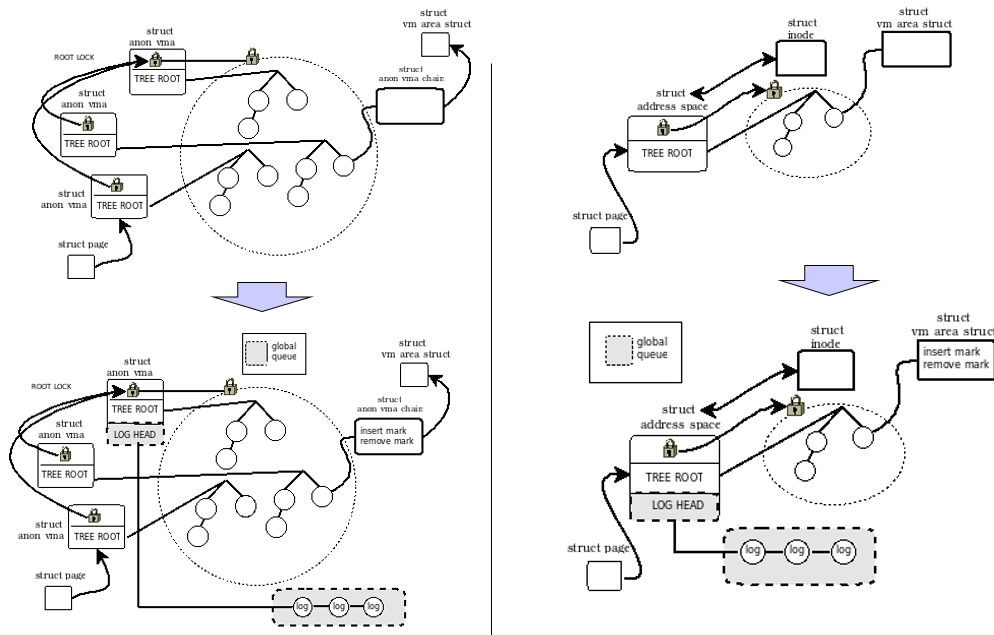
해결 방법
우리가 제안하는 방법은 앞서 연구한 방법인 타임스탬프를 사용하지 않고, 개별적인 오브젝트를 대상으로 스왑(swap) 명령어를 사용하여 공유되어 있는 로그를 삭제하는 방법을 사용 하였다. 이를 위해, 우리는 모든 오브젝트를 대상으로 삽입 (insert)와 삭제(remove)에 대한 마크 필드를 추가해서 업데이트 순간 로그를 지우는 작업을 수행 하였다. 예를 들어 만약 특정 오브젝트를 대상으로 삽입-삭제 명령어 순서가 수행 될 경우 처음 삽입 명령어는 삽입 마크 필드에 표시하고 큐에 저장한다. 다음 삭제 명령어부터는 로그를 큐에 저장하지 않고 상태 플래그인 삽입에 표시한 마크 필드에 표시한 값만 원자적으로 지워주는 방식으로 로그를 삭제하였다.
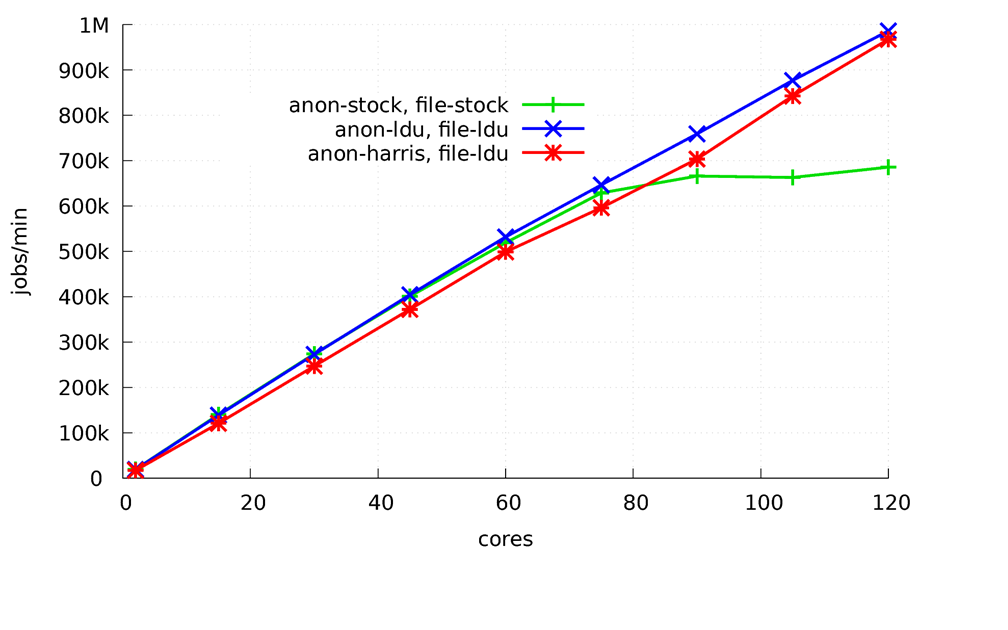
결과
로그 기반 알고리즘을 사용해서 개선된 성능을 보여준다. 75코어 까지는 두 버전의 리눅스 커널은 비슷한 성능을 보이나. 그 이후에는 디폴트 리눅스 커널 보다 1.5배의 성능 향상을 보인다. 그 이유는 업데이트 명령들을 병렬로 수행되었기 때문이다.
Spark Scalability for Scale-up server
요약
스파크는 많은 컴퓨팅 환경이 네트워크로 연결되어 있는 환경인 scale-out 환경에서 많이 쓰이고 있다. 이러한 scale-out 환경을 사용하는 이유는 고가의 컴퓨터 환경을 구성하지 않아도 적당한 가격의 컴퓨터 환경을 여러 대 구성하여 더 좋은 효율을 낼 수 있기 때문이다. 그러나 최근 코어수가 증가함에 따라 HPC(High-Performance Computing) 시스템 환경인 scale-up 환경에서도 스파크 시스템의 성능에 대한 연구가 필요해지고 있다. 이유는 코어 수가 많은 고성능의 컴퓨터가 보편화되기 시작한다면, 코어 수가 적은 서버 여러 대를 구성해서 데이터를 처리하는 것보다 고성능 컴퓨터 몇 대를 두고 처리하는 것이 더 효율적일 수 있다. 하지만 아직 매니코어와 같이 HPC 환경에서의 스파크 시스템에 대한 연구가 부족한 것이 문제이다. 이러한 문제를 해결하기 위해, 본 문서는 분산 처리 클러스터 시스템의 자원을 HPC 시스템에서 구성했을 때, 이에 대한 성능(Performance)과 확장성(scalability)에 대한 문제를 분석하였다. 본 연구에서는 120코어로 구성된 매니코어 시스템을 위에 분산 파일 시스템(HDFS)과 스파크 시스템(Master/Worker)을 한 시스템에서 구성하였다.
Spark Scalability problem
1개의 노드로 구성된 manycore Scale-up 서버에서 아파치 스파크는 아래와 같이 확장성 문제가 있다.
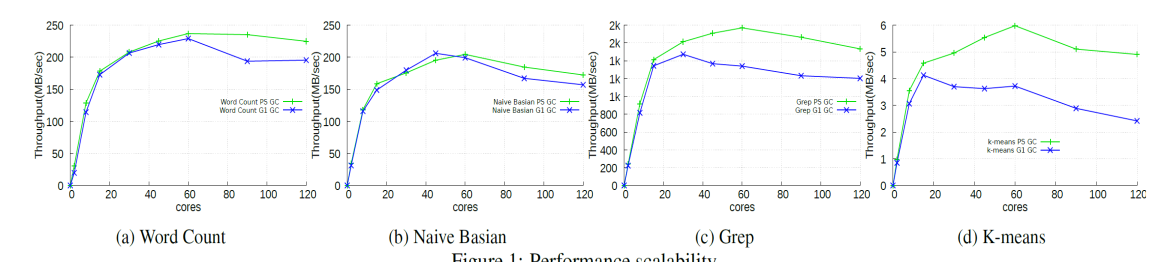
Solution
본 연구는 도커 기반의 매니코어 관리 기술에 관한 것으로, 보다 상세하게는, 누마(NUMA) 구조에 대응하도록 그룹화된 복수의 노드들을 도커의 컨테이너로 구성함으로써 성능을 향상시킬 수 있는 도커 기반의 매니코어 관리 방법 및 이를 수행하는 도커 기반의 매니코어 관리 방법을 이용하여 해결하였다.
Result
도커를 이용한 파티션닝 기법을 이용하면 확장성이 향상된다. 이를 기반으로 설계를 하였다.
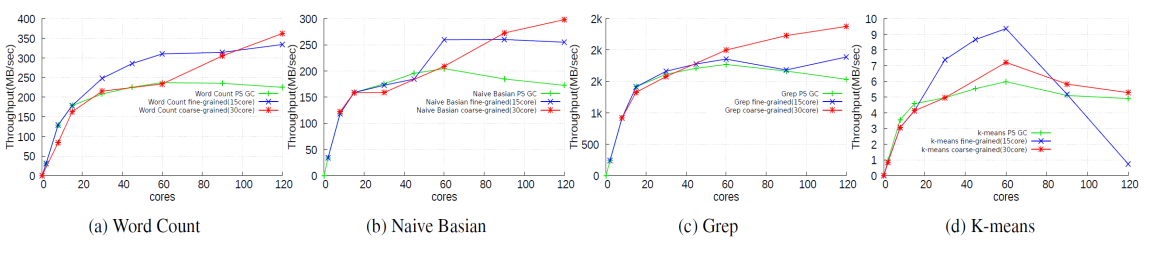
Multithreaded program scalability problem
연구 요약
본 연구는 매니코어 환경에서 리눅스 가상 메모리 관리의 확장성에 대한 문제점을 멀티 쓰레드 관점으로 해결하고자 했다.
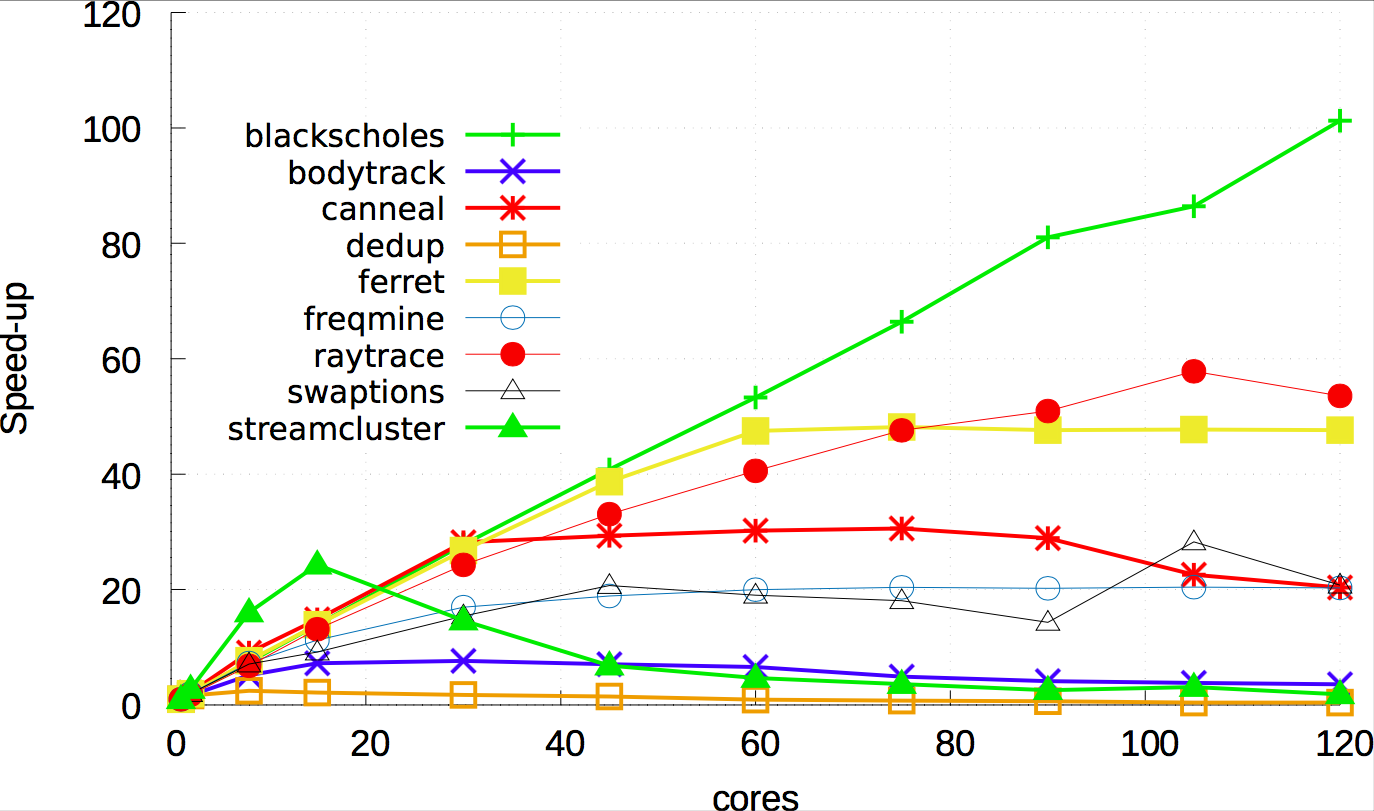
Multi threaded program (PARSEC benchmark) scalability problem
120코어 시스템에서 멀티 쓰레드 프로그램 실행시에 실제로 확장성이 떨어지는지 확인해보았다. 실제로 40코어 부근부터 대부분의 프로그램이 급격히 확장성이 떨어짐을 알 수 있었다. 이 과정에서 PARSEC 실제로 각 task 에 존재하는 rw_semaphore 의 경합 문제가 가장 크게 대두 되었으며, 실제 스레드가 cpu를 점유했음에도 아무것도 하지 못하고 다음 스레드로 스위칭하는 문제 등이 다양하게 나타났다. 하지만 blackscholes 의 경우에는 비교적 완만하게 확장성의 증가를 보여주었으며, 이점에 주목해서 무엇이 다른 프로그램과 다른가를 확인해 보았다.
결과
blackscholes 가 다른 워크로드 들과 달랐던 점은 공유되는 오브젝트의 크기가 작고, 또한 동기화 숫자도 작기 때문에 확장성을 가질 수 있었다. 이 점에서 착안하여 멀티 스레드 프로그램을 설계하는 과정에서 잘 만드는 것이 중요하고, 커널에서 락을 통해 확장성을 가지긴 힘들다고 판단하였다.
Grouping method for Scalability for Scale-up server
요약
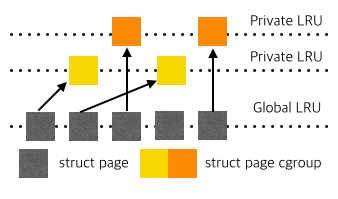
기존 리눅스 커널의 페이지 교체 알고리즘인 LRU(Least Recently Used) 는 하나의 전역 LRU로만 운영되고있다. 이는 여러명의 유저가 접속하는 환경에 적합하지 않다. 이를 위해 Docker 를 구성하고 있는 Cgroups 의 기능인 Private LRU 를 이용하여 각 유저마다 또는 그룹마다 LRU 를 추가해 확장성을 가질 수 있는 기법을 제안하고 성능 분석을 통해 확장성을 입증한다.
Scalability problem
1개의 노드로 구성된 manycore Scale-up 서버에서 AIM7 benchmark 는 아래와 같이 확장성 문제가 있다.
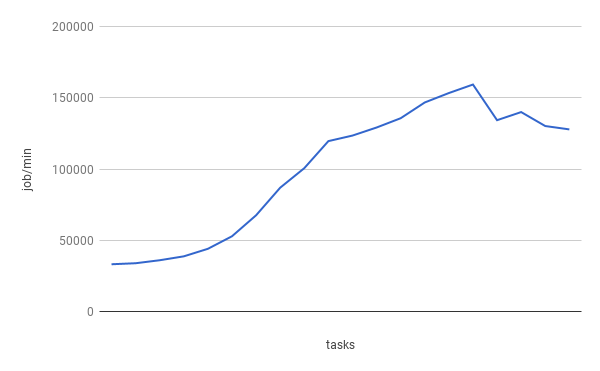
Solution
본 연구는 도커 의 기반 기술인 Cgroups 안에 존재하는 private LRU 를 활용하기 위해 도커로 task들을 그룹핑 하는 방법을 통하여 Scale-up 서버에서의 확장성을 증가시켰다.
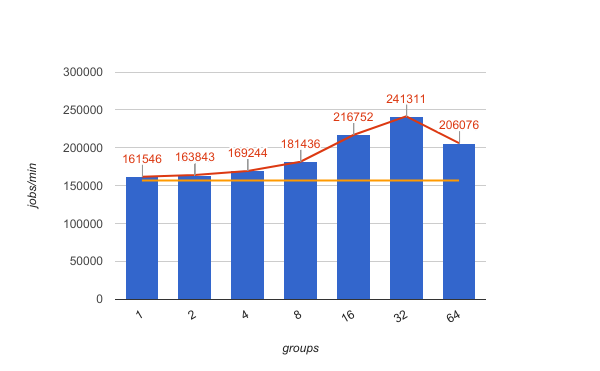
Result
해당 기법을 통해 최대 150% 성능이 향상 되었다.
결과물
- 논문
- Improving Scalability of Apache Spark-based Scale-up Server through Docker Container-based Partitioning
- 매니코어 환경에서 로그 기반 동시적 업데이트 기법을 활용한 리눅스 확장성 향상
- HPC 환경에서의 오픈소스 아파치 스파크 시스템 성능 측정 및 분석
- LDU: A LIGHTWEIGHT CONCURRENT UPDATE METHOD WITH DEFERRED PROCESSING FOR LINUX KERNEL SCALABILITY
- 매니코어 환경에서 자동 NUMA 밸런싱 효과 분석
- 매니코어 시스템을 위한 리눅스 가상 메모리 관리의 락 경합 분석
- 다중 코어 기반의 실시간 가상화 시스템을 위한 이종 운영체제 통합 성능 분석 방법에 관한 연구
- 매니코어 환경에서 PARSEC 벤치마크 ROI 확장성 분석
- 매니코어 환경에서 멀티 유저 확장성 을 위한 docker 기반 프로그램 실행 기법
- 공개 소프트웨어
- Github: Scalablelinux
- Github: lksm
- Github: PARSEC_MANYCORE
- Github: LDU