스케일러블 네트워크 스택
연구 배경
검색, 소셜 네트워크, 전자상거래 등 서비스를 제공하는 데이터센터의 애플리케이션은 일반적으로 수백 개의 마이크로 서비스로 동작한다. 즉, 사용자의 요청은 마이크로 서비스화하기 위해 수천 개의 원격 프로시저 호출(RPC, remote procedure call)로 바뀌어 처리된다. 이러한 환경에서 빠른 통신 및 서비스를 지원하기 위해 40G/100G를 지원하는 네트워크 어댑터를 사용한다. 또한, 기존의 TCP/IP 처리 외에도 RDMA(remote direct memory access) 기능을 지원하는 네트워크 카드가 도입되고 있다. 스위치, 라우터, 미들박스와 같은 네트워크 장비들은 특정 하드웨어에서 최적화된 소프트웨어를 사용하여 고성능 패킷 처리가 가능하다. 하지만, 현재의 데이터센터는 수천 개의 가상머신과 컨테이너를 통해 서비스를 제공하기 때문에 물리적인 네트워크와 상관없이 자체적인 토폴로지를 구성하고 네트워크를 지원한다. 따라서 하드웨어 기반의 네트워크 성능 향상은 데이터센터에서의 유연성과 확장성을 충족시키기 어렵다. 데이터센터에서 유연성과 확장성을 지원하기 위해 네트워크 기능 가상화(NFV, network function virtualization)가 연구되었다. 네트워크 기능 가상화는 하드웨어로 제공되는 네트워크 기능을 소프트웨어로 구현한 기술로 일반 소프트웨어와 같이 운영체제 커널의 기능을 사용하여 통신을 제공한다. 하지만 현재 사용되는 네트워크 및 프로토콜 스택으로 인해 데이터센터에서 많은 대기시간이 발생한다. 데이터센터의 시스템 소프트웨어에 의해 대기시간이 랙 사이에는 66%, 랙 안에서는 81% 발생한다. 이는 네트워크 및 프로토콜 스택이 빠른 통신에 최적화되지 않았기 때문은 오버헤드가 발생하여 네트워크 성능을 모두 사용하지 못하기 때문이다. 이와 같은 환경에서 높은 네트워크 성능을 얻기 위해서는 더 많은 코어 자원이 필요하다.
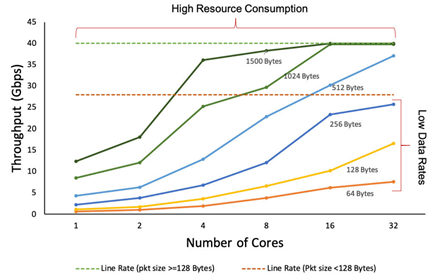
그림에서는 40G 네트워크 환경에서 코어 수와 패킷 크기에 따른 네트워크 성능을 보인다. 패킷 크기가 작은 경우(256바이트 이하) 코어 수에 상관없이 네트워크의 성능을 지원하지 한다. 패킷 크기가 큰 경우(256바이트 초과)에는 적은 코어(4코어 미만)의 경우 네트워크의 성능을 여전히 지원하지 못하지만, 많은 코어(4코어 이상)의 경우에는 네트워크의 모든 성능을 지원할 수 있음을 확인하였다. 엑사스케일 컴퓨팅 환경이 발전함에 따라 이를 지원하는 프로세서도 기존 수십 개의 코어로 구성된 멀티코어에서 수백~수천 개의 코어로 구성된 매니코어 환경으로 발전하고 있다. 프로세서의 발전과 함께 컴퓨팅 시스템이 점점 더 강력해짐에도 불구하고, 빠른 네트워크의 지원하기 위해 많은 코어를 사용해야 하기 때문에 연산에 활용되는 코어는 작아진다. 매니코어 환경에서 빠른 네트워크를 지원하기 위해 소프트웨어 수준에서의 최적화 연구가 필요하다.
네트워크 스택 개선을 통한 패킷 처리 고속화 기법
- 연구 내용
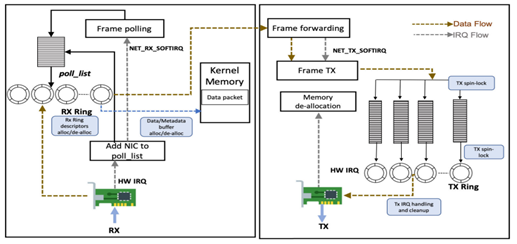
리눅스에서의 TCP/IP 스택은 그림과 같이 메타 데이터와 데이터 버퍼 할당 및 삭제 오버헤드, 패킷 송신 큐의 잠금 오버헤드와 빈번한 송신 인터럽트 처리로 병목 원인이 된다. mKPAC(kernel packet processing for manycore systems)은 40G 이상의 고속 네트워크에서 커널의 TCP/IP 스택에서 발생하는 병목 요인을 제거하여 커널 패킷 처리를 고속화한 연구이다. mKPAC에서 네트워크 스택의 병목을 제거하기 위해 수신(Rx)/송신(Tx) 데이터 및 메타 데이터 버퍼 할당 및 해제, 송신(Tx)/수신(Rx) 링 디스크립터 관리, 송신(Tx) 스핀락, 송신(Tx) 인터럽트 처리 및 정리(cleanup)를 개선하여, 네트워크 스택에서 발생하는 오버헤드를 줄이고 패킷 처리 성능을 개선하였다. 또한, 실험을 위해 그림의 오픈소스 기반 패킷 생성기 테스트베드를 구축하였다. mKPAC은 DPDK와 달리, 네트워크 서비스 제품 환경에서 이미 견고하고 안정성이 입증된 리눅스 커널의 기능을 활용한다.
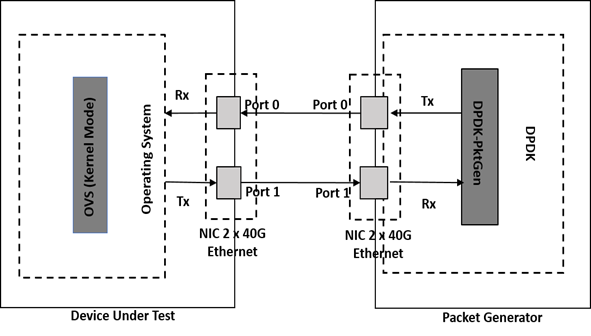
테스트베드를 위해 인텔 제온 CPU E7-8870v2 2.3GHz로 15코어, 8소켓으로 구성된 120코어의 매니코어 시스템을 구축하였다. 네트워크를 위해 2개의 40GbE 포트로 구성된 인텔 이더넷 컨트롤러 XL710를 설치하여 데이터의 수신과 발신에 사용하고, 데이터 플레인의 전송을 위해 OVS 커널 모듈을 사용한다. 패킷 생성기는 56코어의 서버로 DPDK-Pktgen을 사용하여 40Gbps의 트래픽을 생성한다.
- 성능 실험
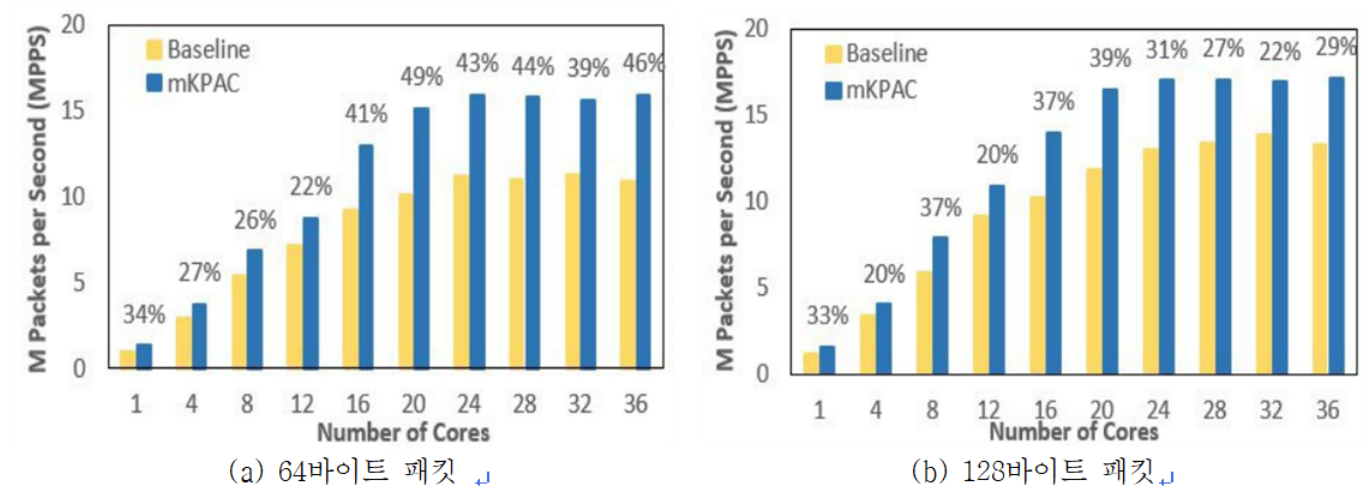
그림은 코어 수와 패킷 크기에 따른 기존 리눅스와의 성능 비교 결과이다. 64바이트 패킷의 경우 기존 리눅스 대비 37% 성능이 향상됨을 확인할 수 있었다. 또한, 코어당 지연시간은 64바이트 패킷의 경우 23%, 128바이트 패킷의 경우 22% 감소한 것으로 측정되었다. 이러한 결과를 통해 커널을 우회하거니 특수 하드웨어 지원 없이 매니코어를 활용할 경우 성능이 향상될 수 있음을 보인 것이다. 패킷 처리 성능은 매니코어 시스템의 다른 오버헤드 및 확장성 문제를 해결하면 더욱 향상될 수 있다.
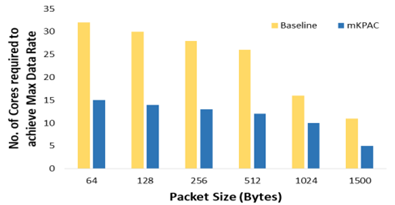
그림은 서로 다른 패킷 크기를 기준으로 리눅스와 비교하여 최대 속도를 얻는 데 필요한 코어 수를 비교한 결과이다. 모든 패킷 치수에서 mKPAC이 50% 이상 필요한 코어 수가 적음을 확인하였다. 이를 통해 특히 매니코어 시스템에서 네트워크의 고속화를 위해 많은 코어를 사용하지 않음으로써, 연산에 더 많은 코어를 활용할 수 있음을 의미한다. 이는 전체 시스템 관점에서 응용 프로그램의 성능을 향상시킬 수 있다.
프로토콜 스택 개선을 통한 성능 개선 연구
- 연구 내용
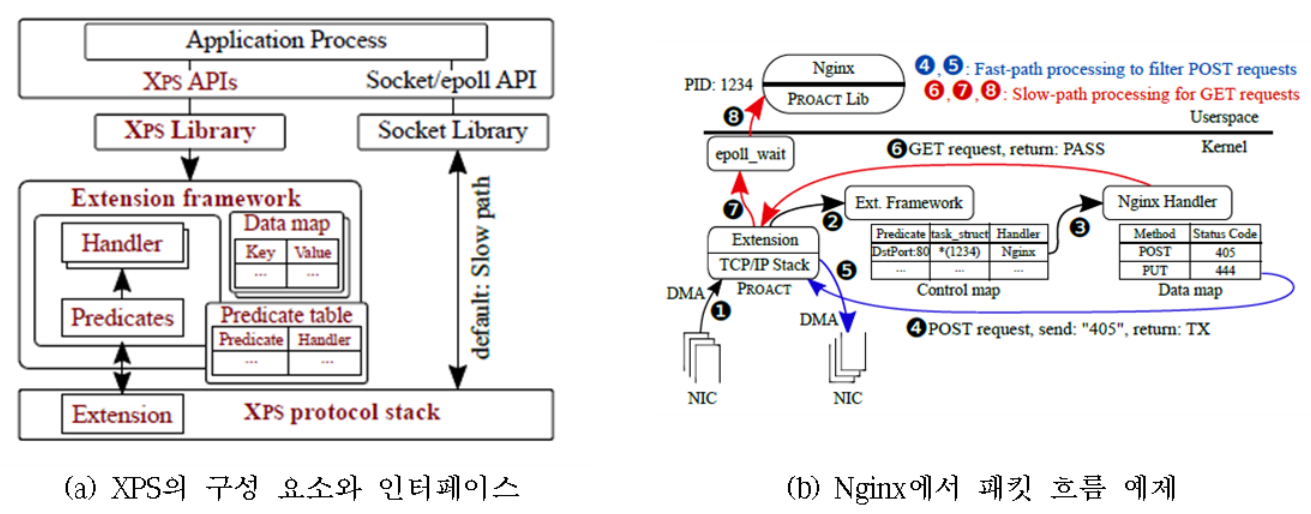
네트워크 통신을 위해 현재 TCP/IP의 소켓 인터페이스를 사용하면 epoll() 및 read()/write()의 소켓 인터페이스 자체인 오버헤드와, 콜드 네트워크 데이터에 접근할 때의 캐시 미스로 인한 오버헤드뿐만 아닐, 커널 페이지테이블 격리(KPTI, kernel page table isolation)와 같은 커널 기능으로 인해 오버헤드가 발생한다. XPS (eXtensible Protocol Stack)은 TCP와 UDP와 같은 프로토콜 스택에서 발생하는 소켓 오버헤드를 줄이기 위해 연구이다.
그림은 XPS의 구조와 웹서비스의 흐름을 나타낸다. XPS는 라이브러리, 확장 프레임워크, 프로토콜 스택의 세 가지로 구성된다. 확장 프레임워크는 예측 테이블(predicate table)과 패킷 처리 프레임워크가 포함되어 있으며, 애플리케이션 핸들러(handler)를 추가할 수 있다. 이를 통해 프로토콜 스택에서의 오버헤드는 데이터 복사, 모드 스위칭, 캐시 미스 등에서 발생하며, XPS는 이를 해결하여 시간에 민감한 연산을 프로토콜 처리 이후에 즉시 실행할 수 있는 추상화된 기능을 제공한다. 이는 일반적인 운영체제의 프로토콜 스택이나, mTCP와 같은 유저 스페이스 프로토콜 스택, 최근의 스마트 NIC에도 적용이 가능하다. 특히 다른 모든 연산은 기존의 소켓 계층을 사용하면서 시간에 민감한 작업을 위해 기능을 확장하였다.
- 성능 실험
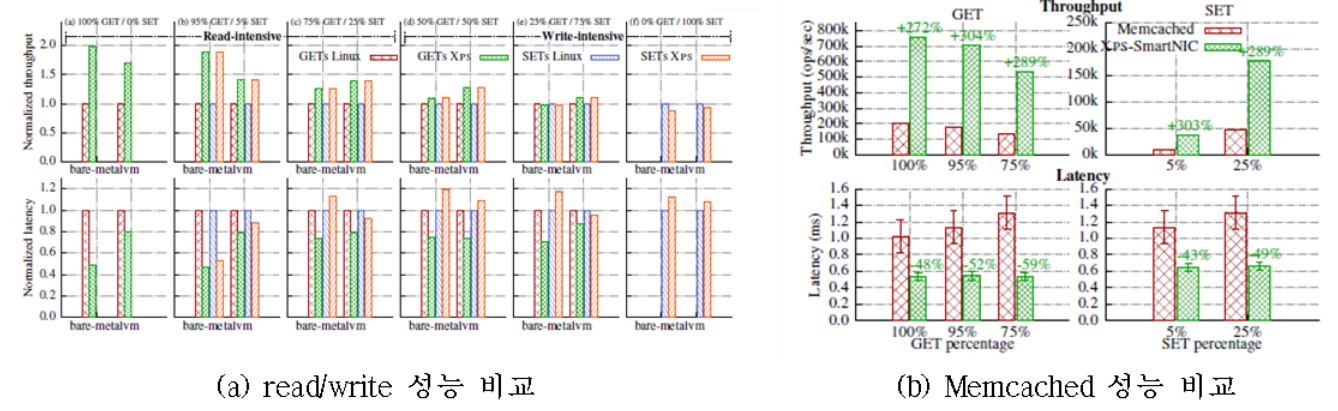
XPS는 키밸류 스코어에서의 캐싱, 웹서버에서 HTTP 요청의 제한 및 필터링, 분산 시스템에서 하트비트 처리의 3가지 실제 서비스를 통해 성능을 확인하였다. 그림은 XPS를 웹서비스와 DB 서비스에서 실험한 결과이다. XPS는 Redis 키밸류 스토어에서 처리량을 98.1% 향상시키고 지연시간이 73.3% 줄어듦을 확인하였다. Nginx 웹서버의 경우 최대 2.2배와 82%까지 성능 향상을 보였다. IX와 ZygOS에 비해 XPS-mTCP는 Redis의 처리량이 최대 50.1% 향상되며, 꼬리 응답시간이 63.5% 향상시킨다.
서비스 기능 체이닝 구성 시 네트워크 서비스 간 성능 개선
- 연구 내용
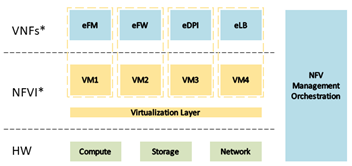
네트워크 기능 가상화(NFV, network function virtualization)는 네트워크 기능들을 전용 하드웨어 장비 대신 소프트웨어 기반의 범용 서버에 가상화하는 기술로, 그림과 같이 가상 네트워크 기능 요소(VNF, virtual network functions)들로 구성된다. 이처럼 가상화를 기반으로 소프트웨어적으로 VNF를 구성하므로, 운용하고자 하는 구성 목적에 따라 네트워크 기능들을 유연하게 구성할 수 있으며, 이에 따라 하드웨어를 직접 구성하지 않아도 되기 때문에 전체 구성 비용이 절감된다.
NFV 기술이 도입되면서 네트워크 서비스 기능이 전달 경로상에 존재하는 형태가 아니라 자신이 필요로 하는 네트워크 서비스 기능이 존재하는 곳을 경유하는 형태로 되게 된다. 이와 같이 특정 서비스를 위해 필요한 서비스 기능들과 이들 간의 적용 순서를 추상화한 것이 서비스 기능 체이닝(SFC, service function chaining)이다. 가상화 기반으로 소프트웨어적으로 VNF 구성할 경우, 네트워크 성능 저하 및 CPU 성능 과부하가 생길 수 있게 되는데, 이를 해결하면 SFC 전체 네트워크 스택의 성능을 향상시킬 수 있다.
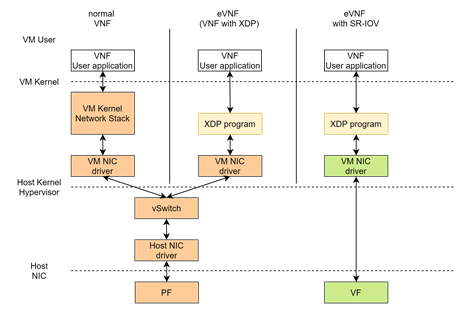
VNF는 하드웨어로 고정되지 않고 소프트웨어적으로 유연하게 구성할 수 있는 장점이 있지만, 커널 네트워크 스택에서 처리되어 사용자 프로그램을 통해 네트워크 기능을 처리해야 하므로 네트워크 성능 저하되고, CPU 성능에 과부하가 발생한다. 이러한 VNF의 성능적 문제점을 해결하려고 했던 연구로는 eVNF가 있으며, eVNF는 eBPF(extended Berkeley Packet Filter)의 네트워크 버전인 XDP(eXpress Data Path)로 VNF를 구현하여 VNF의 네트워크 성능 저하 및 CPU 성능 과부하의 문제점을 해결하였다.
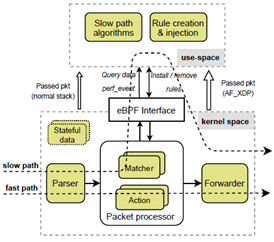
단일 루트 I/O 가상화(SR-IOV, single root I/O virtualization)은 하나의 네트워크 디바이스를 가상화 기술을 통해 여러 개의 네트워크 카드로 만들어 가상머신에서 사용하게 하는 기술이다. SR-IOV를 사용하면 가상머신이 호스트 머신의 네트워크 인터페이스 카드에 직접 연결된 것처럼 동작하여 I/O 성능이 향상된다. 본 연구에서는 가상머신 환경에서 eVNF 기반으로 SFC를 구성하는 데 있어서 SR-IOV 기술을 적용하여 가상화 단계에서 발생할 수 있는 네트워크 성능 저하를 최소한으로 함으로서, NFV의 유연함과 구성 비용 절감 효과를 가져오면서 성능 저하는 최소한 줄일 수 있는 방안을 제시한다.
- 성능 실험
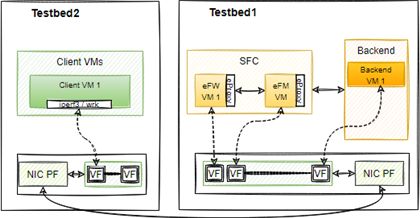
eVNF와 SR-IOV를 적용한 SFC의 성능 개선을 확인하기 위해 그림과 같이 테스트베드를 구축하였다. 테스트베드 1은 SFC를 구성한 시스템으로, eVNF 기반으로 방화벽(eFW), 플로우모니터(eFM), 로드밸런서(eLB)로 SFC를 구성하였다. 프론트엔드에는 SFC, 백엔드에는 웹서버가 동작한다. 테스트베드 2는 클라이언트 노드로 패킷을 생성하여 전달한다. 이를 위한 벤치마크로는 iperf3과 wrk를 사용하였다. 테스트베드는 인텔 XL710 40G 네트워크 카드 기반으로 연결하였다. 비교를 위해 VNF 기반 SFC에서 방화벽은 리눅스의 iptables를 사용하였고, 플로우모니터는 eFM을 참고하여 구현하였다.
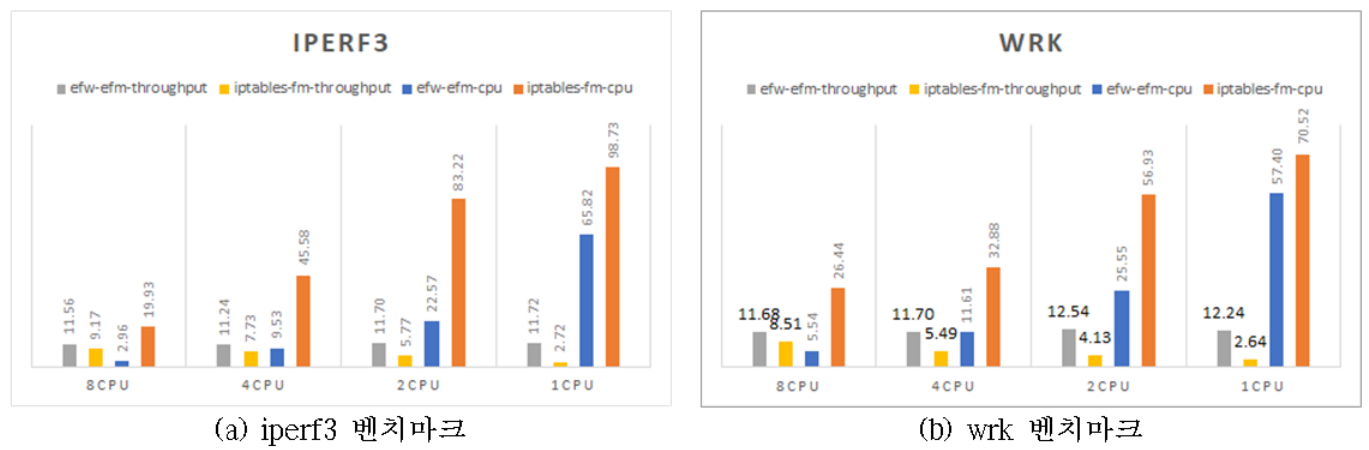
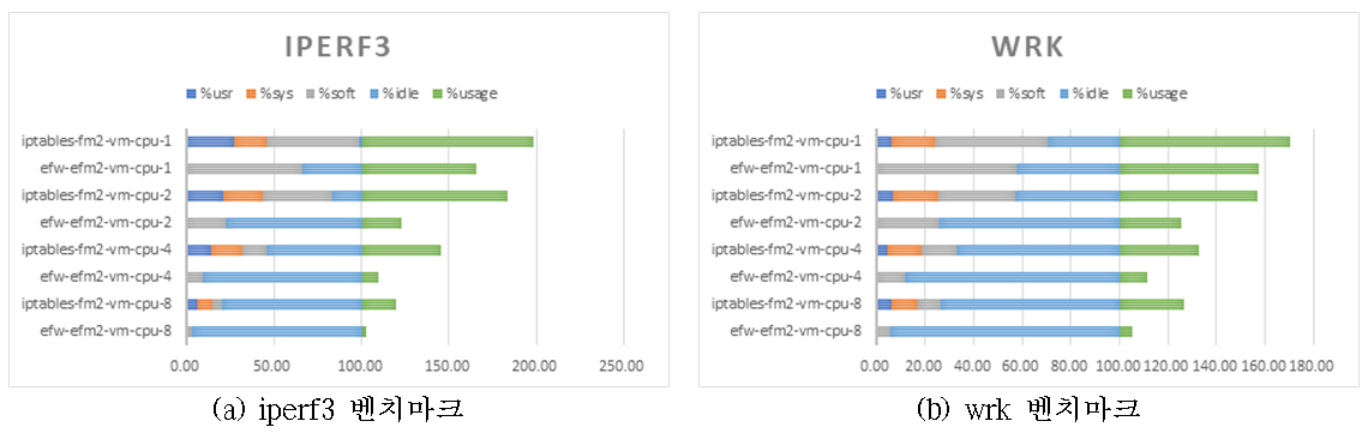
그림은 벤치마크별로 성능을 실험한 결과이다. iperf3 벤치마크에서는 eVNF 기반 SFC는 VNF 기반 SFC에 비해 네트워크 성능이 26%~331% 향상되었으며, 17%~62%의 CPU 사용률 감소를 확인하였다. wrk 벤치마크에서는 37%~361%의 네트워크 성능 향상 및 13%~31%의 CPU 사용률 감소를 확인하였다. 두 벤치마크 모두 eVNF기반 SFC에서는 모든 vCPU(1개~8개)에서 비슷한 네트워크 성능을 확인하였지만, VNF 기반 SFC에서는 vCPU 개수에 따라 큰 폭의 네트워크 성능 저하를 확인하였다. 1개의 vCPU 실험에서 가장 높은 네트워크 성능 차이, 2개의 vCPU 실험에서 가장 높은 CPU 사용량 차이가 있었다. 이러한 성능 차이는 커널 네트워크 스택을 거치지 않는 XDP의 특성 때문인데, SFC를 거쳐 가는 패킷이 해당 VNF가 구현된 가상머신의 커널 네트워크 스택을 거치지 않고 네트워크 드라이버 단에서 처리되어 진행되기 때문이다.
그림은 CPU 사용량을 세분화하여 분석한 결과이다. eVNF와 VNF의 가장 큰 차이는 %sys(커널 영역) %usr(사용자 영역)의 CPU 사용량의 존재 여부다. XDP를 적용한 eVNF의 경우 패킷이 네트워크 드라이버 단에서 바로 처리되기 때문에 커널 영역 및 유저 영역에서의 CPU가 사용되지 않는다. 이 차이로 eVNF기반 SFC에서는 비교적 적은 vCPU에서도 일정한 네트워크 성능을 내면서도 CPU 사용량이 낮게 되는 결과를 보여 준다. 이를 통해 매니코어 시스템에서 네트워크의 성능을 보장하기 위해 많은 코어를 사용하지 않음으로써, 연산에 더 많은 코어를 활용할 수 있음을 의미한다. 이를 통해 매니코어 시스템의 전체적인 성능을 향상시킬 수 있다.
결과물
- 논문
- 소프트웨어
- Github: mKPAC
- 시연영상