스케일러블 F2FS 파일시스템
Node Cache와 Atomic Range Lock을 이용한 단일 파일 I/O 병렬화
연구 개요
매니 코어 환경에서 단일 파일 I/O를 수행하는 경우 F2FS는 성능이 확장하지 않는다. 우리는 이러한 문제점의 원인으로 세가지를 밝혔다.
첫째, F2FS 파일 시스템에서 사용하는 파일 단위의 Inode Mutex Lock이 모든 I/O를 Serialize 한다. 따라서 각 쓰레드가 다른 데이터 블락에 대해 I/O를 수행하는 경우에도 I/O는 병렬적으로 수행하지 못한다. 둘째, 첫째에서 언급한 I/O Serialization 문제를 해결 하기 위해 도입한 Interval Tree 기반의 Range Lock에서 Lock Contention이 발생한다. 특히 Interval Tree에서 노드 삽입/삭제시 트리 단위로 사용하는 Mutex Lock이 F2FS의 I/O 성능 확장성을 크게 감소시킨다. 셋째, 여러 쓰레드가 단일 파일에 대해 I/O를 수행하는 경우 커널 쓰레드가 페이지 캐시에 있는 F2FS의 인덱스 자료구조에 접근하는데 이 때 인덱스 자료구조에서 Lock Contention이 발생한다. 우리는 이에 대한 해결책으로 다음과 같은 설계를 제안한다.
첫째, 단일 파일 I/O를 병렬화 하기 위해 F2FS의 Inode Mutex Lock을 Range Lock으로 대체한다. Range Lock은 파일 전체가 아닌 접근하고자 하는 일부분 만을 Lock함으로써 단일 파일 I/O를 병렬화 할 수 있다. 둘째, Interval Tree 기반의 Range Lock에서 발생하는 Lock Contention을 최소화하기 위해 Lightweight한 Atomic 연산 기반 Range Lock을 적용하였다. 셋째, 페이지 캐시에서 발생하는 Lock Contention을 해결하기 위해 F2FS의 인덱스 자료구조를 캐싱하는 Node Cache를 제안한다.
연구 내용
- Range Lock의 설계 및 구현
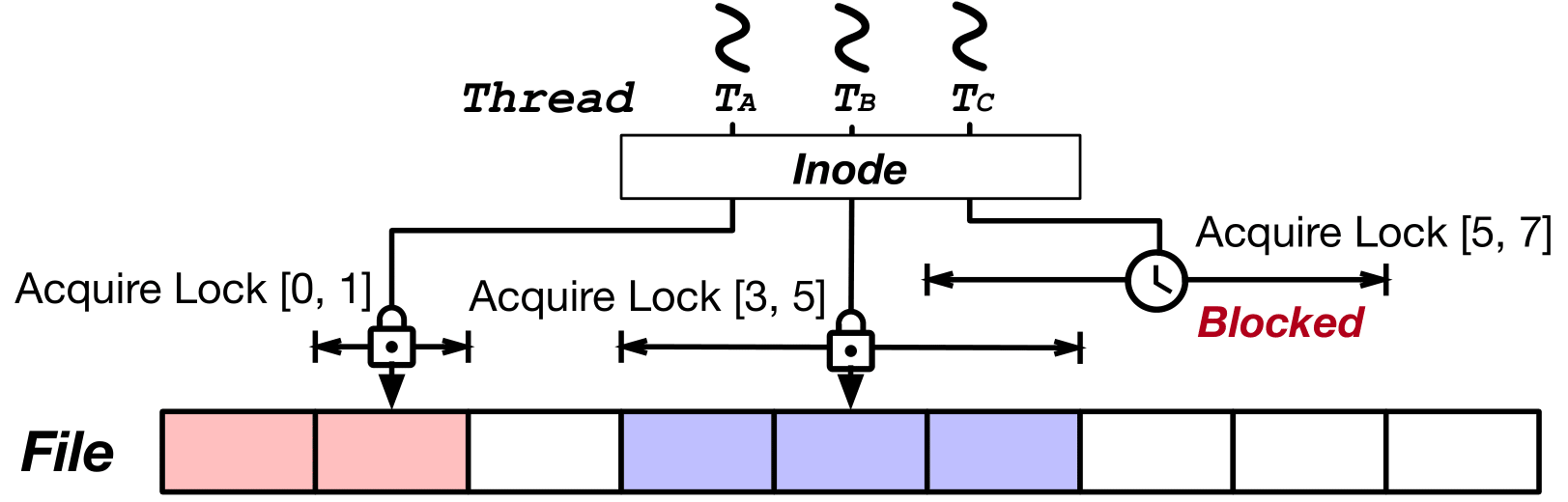
Native 파일 시스템에서는 I/O 처리시 Inode Mutex Lock을 이용하여 한번에 하나의 I/O만 처리한다. 그러나 이는 응용에서 발생하는 같은 파일에 대한 다수의 I/O를 처리할 때 엄청난 오버헤드를 발생시킨다. 이러한 단일 파일 I/O의 Serialization을 해결하기 위해 우리는 I/O 하려는 범위에만 Lock을 얻는 Range Lock을 제안한다. 위 그림은 3개의 쓰레드(TA, TB, TC)가 단일 파일에 I/O를 수행하는 상황이다. 우선 쓰레드 TA가 파일의 블록 [0, 1]에 I/O를 수행한다. 겹치는 영역에 I/O를 수행하는 다른 쓰레드가 없기 때문에 TA는 Block되지 않고 I/O를 수행한다. 쓰레드 TB도 마찬가지로 블록 [3, 5]에 I/O를 수행한다. 그 후 쓰레드 TC가 블록 [5, 7]에 I/O를 수행하려고 하지만 이미 I/O를 수행하고 있는 쓰레드 TB와 범위가 겹치기 때문에 쓰레드 TC는 블록된다. 쓰레드 TB의 I/O 수행이 끝나면 쓰레드 TC가 I/O를 시작할 수 있다. 이를 통해 데이터의 Consistency를 지키면서 단일 파일 I/O를 병렬적으로 수행할 수 있다
- nCache 설계 및 구현
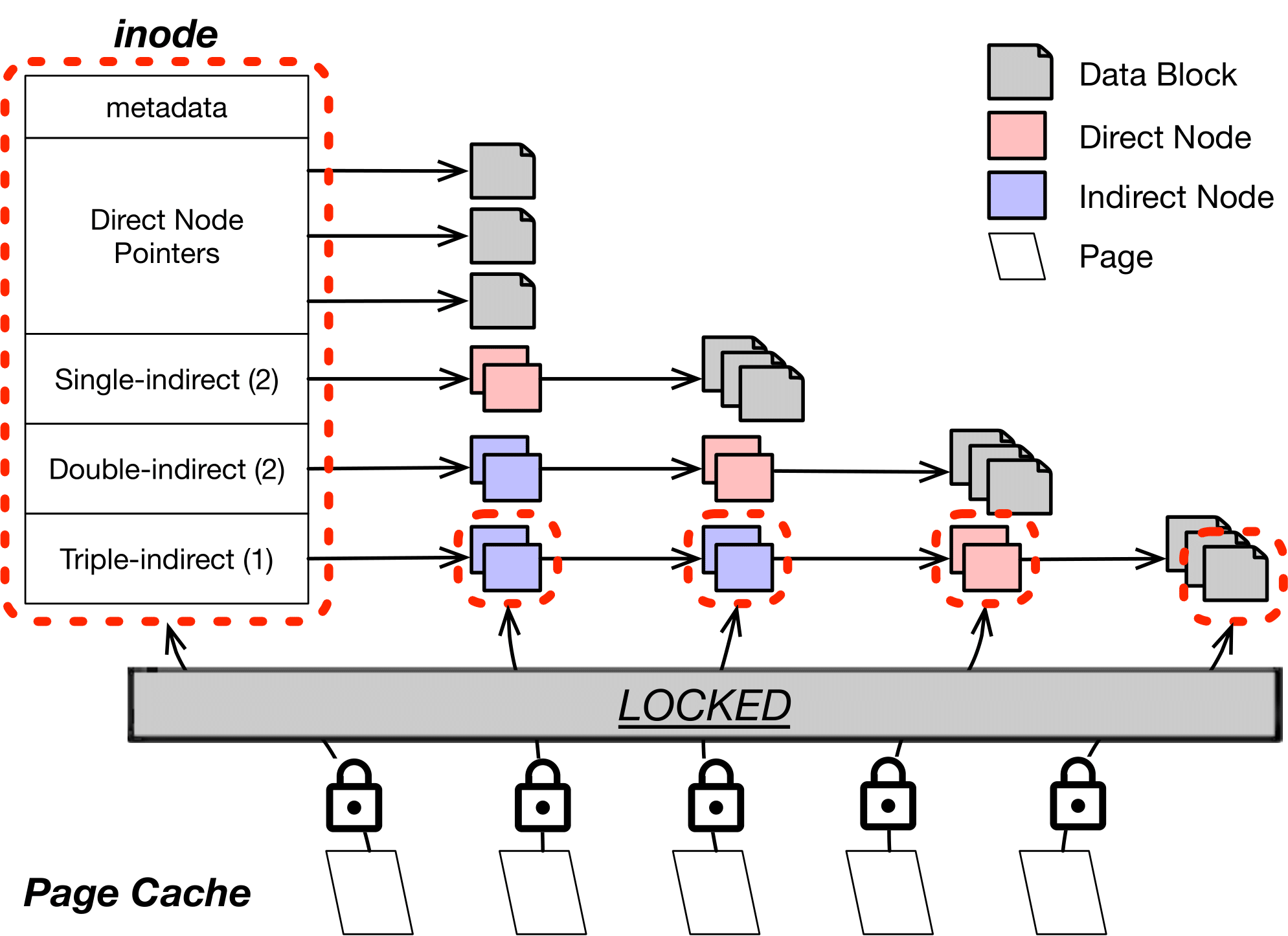
F2FS에서 단일 파일 I/O 수행시 페이지 캐시 내부의 Node를 접근하는데 이 때 사용하는 mutex lock 때문에 확장성 저하가 발생한다. 위 그림은 F2FS에서 커널 쓰레드가 I/O를 수행할 때 페이지 캐시에 있는 Node를 접근하는 과정이다. F2FS에서 Node를 접근할 때, 해당 Node를 포함하는 Inode로부터 탐색을 시작한다. 파라미터로 얻은 Offset값을 이용하여 Inode부터 자식 Node를 반복적으로 탐색하여 원하는 Node에 접근할 수 있다. 이 과정에서 Node에 접근할 때 페이지 캐시를 참조하게 된다. 접근하려는 Node id를 얻으면 페이지 캐시에서 이에 해당하는 Node가 있는지를 체크한다. 이 때 Node를 보호하기 위해 페이지 캐시에서는 mutex lock을 사용한다. 여러개의 커널 쓰레드가 각각 다른 데이터 페이지에 대해 I/O를 수행하면 Range lock을 통해 병렬 I/O 수행은 허용하지만 여러 데이터 페이지들이 Node를 공유하기 때문에 Node에 접근하는 과정에서 lock contention이 발생한다.
F2FS는 Node를 lock/unlock 하기 위해 페이지 캐시 API를 사용한다. 그러나 Linux의 페이지 캐시는 mutex lock/unlock API만을 제공한다. 따라서 Node를 읽기만 하는 경우에도 mutex lock을 얻어야 한다. Node를 읽는 작업은 File read 뿐만 아니라 File write 호출시에도 수행된다. Node를 읽는 과정에서 발생하는 lock contention은 I/O 확장성을 크게 감소시킨다. 따라서 lock contention을 줄이기 위해 Node를 캐싱하는 nCache를 설계하였다. nCache는 페이지 캐시와 비슷한 역할을 한다. F2FS가 특정 Node에 처음 접근하면 해당 Node는 nCache에 캐싱이 된다. 그 이후 캐싱된 Node에 대한 읽기나 쓰기 요청이 들어오면 해당 연산은 페이지 캐시를 거치지 않고 nCache에서 수행된다. nCache는 R/W Semaphore을 이용하여 Node를 보호하기 때문에 Node를 동시에 읽는 작업은 병렬적으로 수행할 수 있다.
- nCache의 Consistency를 위한 Double-Checked Locking
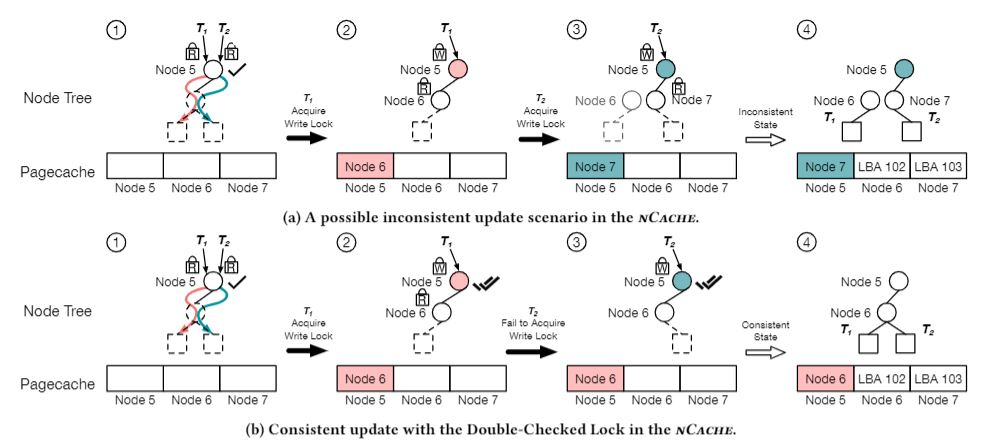
기존 nCache에서는 consistency를 해칠 수 있는 경우가 존재했다. 위 그림과 같이 두 Thread T1, T2가 동시에 겹치지 않는 범위의 데이터 블록을 write하려고 하는 경우가 존재한다. 이 때, 기존 nCache의 경우인 위 그림의 (a)에서 Reader Lock을 걸고 부모 노드인 Node 5의 child가 없는 것을 확인한다. 이후 T1이 node 6을 생성하고 node 5와 연결한다. 그 다음 T2 역시 Node 7을 생성하고 Node 5와 연결하는데 처음에 Node 5가 child가 없음을 확인하였으므로 바로 Node 5와 연결한다. 이 경우 Node 7이 Overwrite되어 Node 6에 대한 링크를 잃어버려 Node 6에 접근할 수 없게 된다. 이러한 상황을 방지하고 Consistency를 유지하기 위해 Double Checked Lock을 이용한다. 위 그림의(b)와 같이 처음 부모노드인 Node 5에 Reader Lock을 걸어 read하는 경우뿐만 아니라 Node 6과 7이 링크를 추가하기 전 부모노드인 Node 5에 Child가 존재하는지를 한번 더 확인하여 새로 생성된 Node에 대한 링크를 잃어버리지 않게 한다.
Double-Checked Locking을 통해서 Consistency를 보장하였으므로 nCache와 Range Lock을 적용한 F2FS에서는 아래 그림과 같이 실행 파이프라인을 최적화하는 것을 보장할 수 있을 것이다. 아래 그림에서의 3개의 쓰레드 T1, T2, T3는 서로 겹치지않는 영역에 I/O를 수행한다고 가정한다
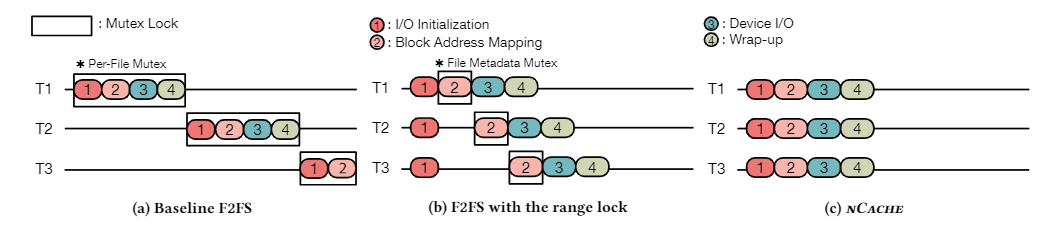
(a)는 기존 F2FS의 I/O시 pipeline이다. 파일에 Mutex가 걸려있어서 다른 쓰레드가 같은 파일에 접근하려고 하면 Mutex에 의해 직렬화 된다. (b)는 Range Lock을 적용한 F2FS이다. Range Lock에 의해 겹치지 않는 범위에 대해서는 I/O initialize가 동시에 가능하지만, Page Cache 내부의 Mutex에 의해 Block Address Mapping부터 직렬화된다. (c)는 Range Lock과 nCache를 둘다 적용한 F2FS이다. 겹치지 않는 범위에 대해서는 동시에 I/O initialize가 가능하고, nCache가 Page Cache를 대체하여 Block Address Mapping을 수행하고 nCache는 Mutex가 아닌 R/W semaphore로 구현되어 동시에 가능하다. 따라서 Range Lock과 nCache의 적용으로 인해 병렬 I/O가 향상되었음을 알 수 있다.
성능 평가
매니코어 환경에서 F2FS의 단일 파일 I/O 확장성 향상을 보기 위하여 FxMark 벤치마크의 DWOM과 DRBM 워크로드를 사용하였다. DWOM은 병렬 단일 파일 쓰기 워크로드이이며 DRBM은 병렬 단일 파일 읽기 워크로드이다. 두 워크로드 모두 쓰레드들이 겹치지 않는 영역에 I/O를 수행한다. 120코어 서버를 사용하였다. 그래프에서 F2FS는 기존 F2FS를 나타내고 F2FS AT+NC의 경우 본 연구에서 제안한 기법을 적용한 F2FS를 나타낸다. 스토리지로는 Samsung EVO 970, Intel SSD 750, Intel Optane 900P에서 실험을 진행하였고 Device Spec은 다음과 같다.
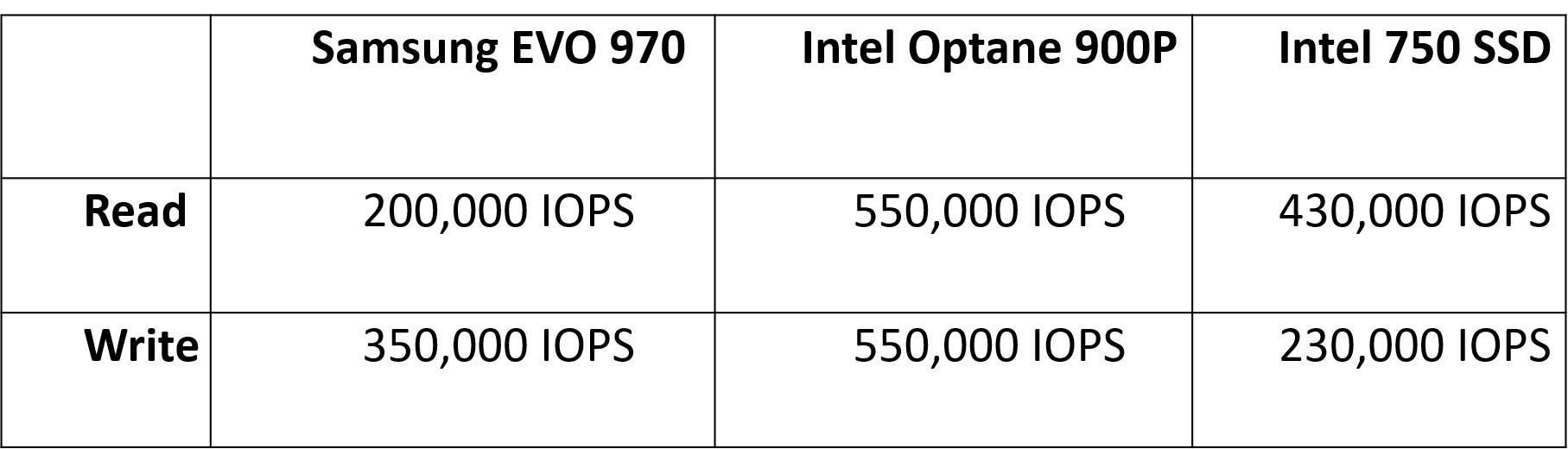
- Write
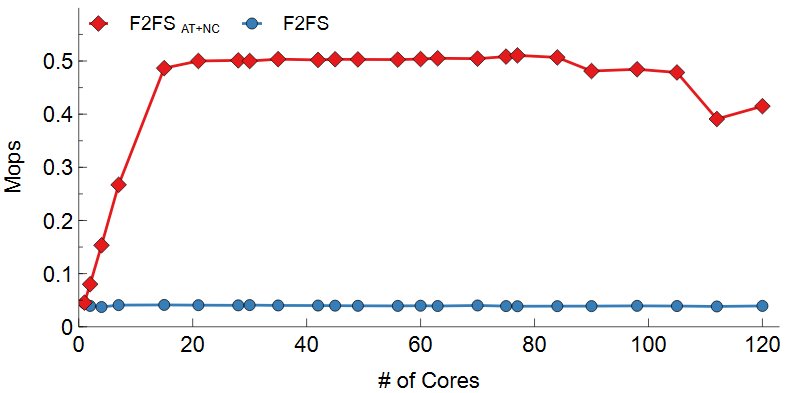
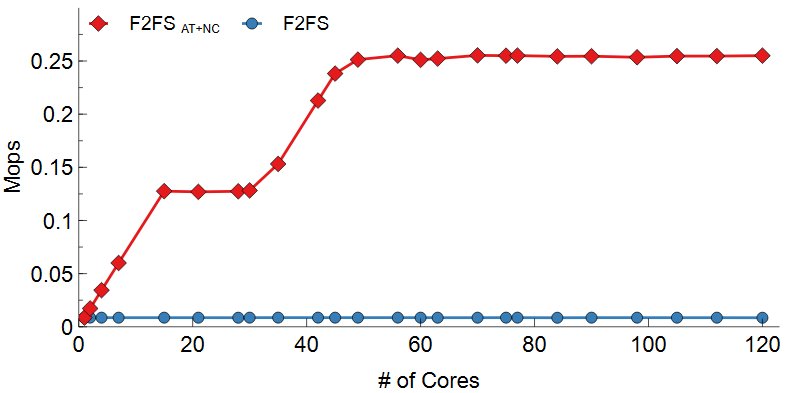
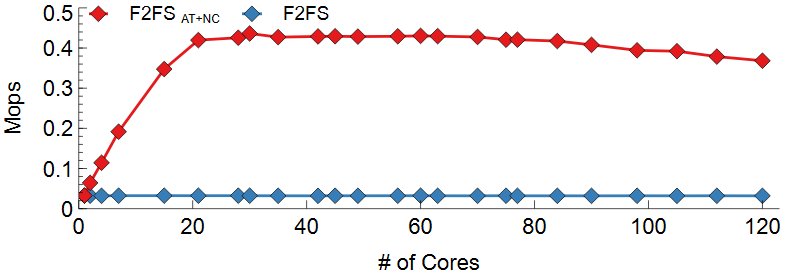
위 그림는 DWOM 실험 결과이다. Range Lock과 nCache가 파일 시스템의 병목을 효과적으로 줄였는지를 실험하기 위하여 차례대로 Samsung EVO 970, Intel SSD 750, Intel Optane 900P에서 실험을 진행하였다. 공통적으로 F2FS의 경우 Inode mutex lock이 모든 I/O를 Serialization하기 때문에 코어 수에 따른 성능 변화가 없다. F2FS AT+NC의 경우 lock contention의 감소로 확장성 있음을 볼 수 있다. 일정 코어 이후로는 성능이 확장하지 않는데 이는 F2FS가 Disk Bandwidth를 전부 다 소모했기 때문이다. 디바이스의 Write 성능에 따라 Write의 Max Throughput은 달랐지만 F2FS AT+NC를 사용한 경우 디바이스의 Throughput까지 확장하였다.
- Read
기존의 FxMark DRBM 워크로드(단일 파일 병렬 Read)에서는 디바이스 Throughput만큼의 확장성을 보여주지 못하였다. 이에 대한 원인을 분석하기 위해 디바이스가 FxMark 실행 시 파일 시스템 영향을 최소화하였을 때의 성능을 기존 구현의 성능과 비교하였는데, 디바이스 자체의 성능으로 인해 bound되었음을 알 수 있었다. 따라서 추가적인 파일 시스템의 병목을 관측하기 위해 디바이스의 성능을 충분히 활용할 수 있는 방법을 활용하였다. 이를 위해 FxMark의 파일 stride를 수정하여 SSD의 특성을 충분히 활용하는 I/O를 하였다. 또한 Read 성능이 더 뛰어난 디바이스들을 활용하였을 때 추가적인 파일 시스템의 병목을 찾을 수 있는지, 혹은 계속해서 디바이스 Throughput까지 확장성을 보이는지를 실험하였다. Range Lock과 nCache가 파일 시스템의 병목을 효과적으로 줄였는지를 실험하기 위하여 차례대로 Samsung EVO 970, Intel SSD 750, Intel Optane 900P에서 실험을 진행하였다.
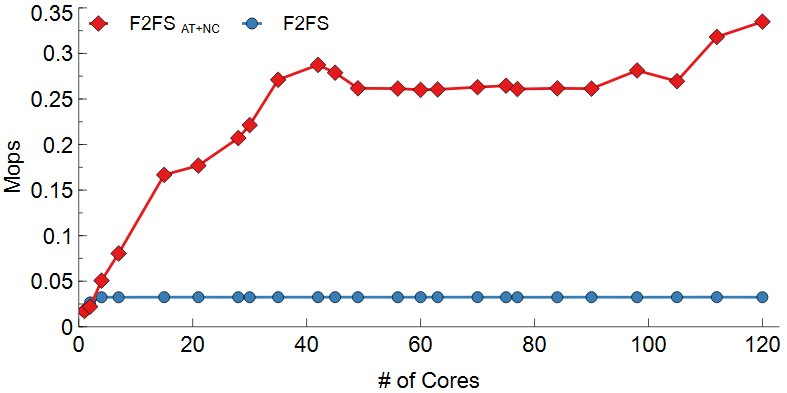
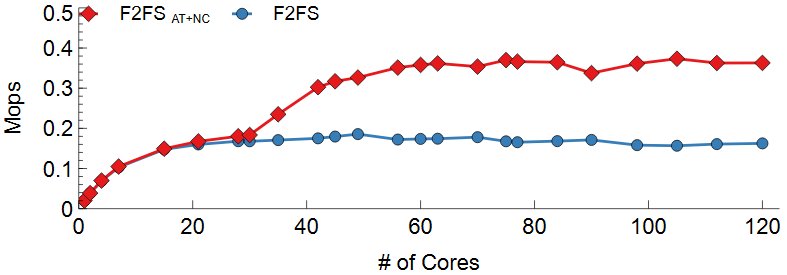
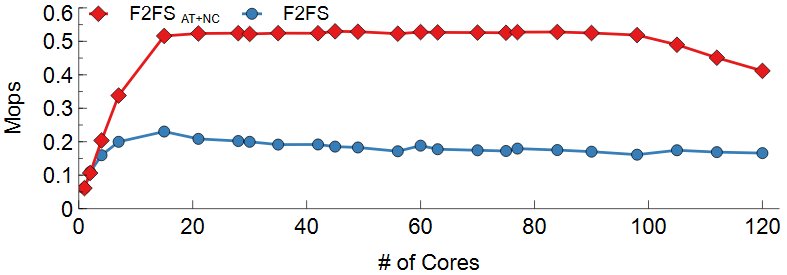
F2FS의 경우 Inode mutex lock으로 인해 모든 I/O가 Serialize 되고 8MB stride를 사용하여 SSD의 특성을 충분히 활용하지 못해 코어수에 따른 성능 변화가 없다. F2FS AT+NC의 경우 4KB의 파일 stride를 이용하여 SSD의 특성을 충분히 활용하였고 lock contention의 감소로 확장성을 보였다.일정 코어 이후로는 성능이 확장하지 않는데 이는 F2FS가 Disk Bandwidth를 전부 다 소모했기 때문이다. 다만 Intel Optane 900P는 NAND FLASH 기반이 아닌 3DX-POINT를 이용하여 이전의 SSD들과는 달리 파일 stride에 따라 성능이 거의 변화하지 않는다. 그렇지만 F2FS AT+NC는 Intel Optane 900P에서도 디바이스 성능만큼의 Throughput을 보여준다. 위 실험 결과들을 통해 Atomic Operation기반 Range Lock과 nCache를 사용하여 단일 파일의 병렬 Read시 발생할 수 있는 파일 시스템 병목을 최소화하였음을 알 수 있다.
결과물
- 논문
- Write Optimization of Log-structured Flash File System for Parallel I/O on Manycore Servers, C.-G. Lee, H. Byun, S. Noh, H. Kang, Y. Kim, In Proceedings of the 12th ACM International Systems and Storage Conference (SYSTOR) (2019), Haifa, Israel, June 3-5, 2019.
- Concurrent File Metadata Structure using Readers-Writer Lock, C.-G. Lee, S. Noh, H. Kang, S. Hwang, Y. Kim, In Proceedings of the 36th ACM/SIGAPP Symposium On Applied Computing (SAC) (2021)
NVM 기반 노드 로깅 기법
연구 개요
F2FS는 fsync가 불렸을 때 파일의 데이터뿐만 아니라 파일의 Inode를 저장하기 위한 I/O를 수행한다. 또한 세그먼트 클리닝과 체크포인팅(Checkpointing)을 위한 추가적인 I/O를 생성한다. 세그먼트 클리닝은 로그 기반 파일시스템에서 새로운 로그 영역을 만들기 위한 과정으로 반드시 체크포인팅을 수반한다. 체크포인팅은 메모리에 존재하는 파일시스템 메타데이터들을 SSD에 저장하여 일관성을 보장하는 과정이다. 특히 체크포인팅은 파일시스템의 모든 I/O 요청을 블록킹(Blocking)하기 때문에 전체적인 성능에 치명적이다.
위와 같은 추가적인 I/O와 체크포인팅으로 인한 I/O 블록킹 문제를 개선하기 위하여 본 연구에서는 비휘발성 메모리(NVM)를 이용한 노드(Node) 로깅 기법을 제안한다. NVM 노드 로깅 기법은 데이터 로그는 SSD에 저장하며 노드 로그와 파일시스템 메타데이터는 NVM에 저장한다. 이를 통하여 체크포인팅 시간을 줄이고 I/O 블록킹 시간도 최소화할 수 있다.
연구 내용
- F2FS에서의 Flush 과정
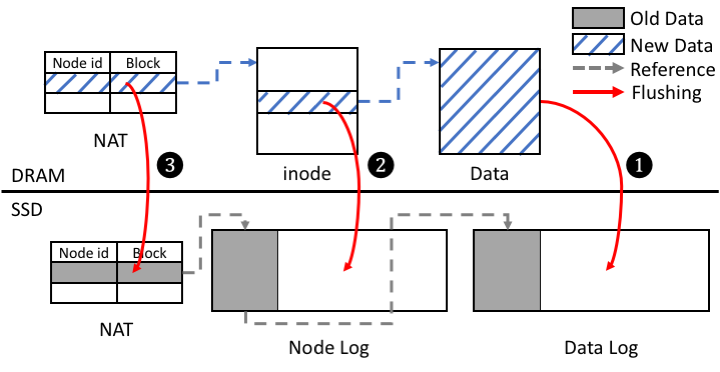
F2FS는 노드(Node) 로그와 데이터(Data) 로그로 구성된다. 노드 로그는 파일의 Inode와 Direct 노드, Indirect 노드로 구성되며 노드 ID를 통해 접근한다. 데이터 로그는 사용자의 데이터와 디렉토리 정보들로 구성되며 블록 주소로 접근한다. F2FS는 파일의 Inode 번호를 노드의 ID로 사용하여 NAT(Node Address Table)를 통해 해당 Inode의 블록 주소를 알아내고 Inode를 참조한다. 파일의 Inode에는 파일의 메타데이터들과 데이터 블록에 대한 주소들이 있어 이를 이용하여 데이터를 참조할 수 있다. 이러한 파일의 데이터와 노드 로그, NAT는 fsync 시스템 콜이 호출되었을 때 SSD로 Flush되어야 한다. 이 때, 파일시스템은 일관성을 보장하기 위하여 (1) 데이터 로그, (2) 노드 로그, (3) 파일시스템 메타데이터의 순서로 Flush 한다.
이러한 Flush 과정들은 파일시스템의 다른 I/O 요청들을 블록킹하고 진행되기 때문에 전체적인 I/O 성능을 저하시킨다. 특히 fsync가 자주 호출될수록 데이터와 노드 로그가 많이 쓰이며 세그먼트 클리닝도 자주 호출되므로 체크포인팅도 자주 발생하게 된다. 또한 메모리에 비하여 느린 블록 디바이스에 저장해야 하므로 fsync는 다른 쓰기들에 대한 Latecny에도 영향을 미친다.
- NVM 노드 로깅 기법
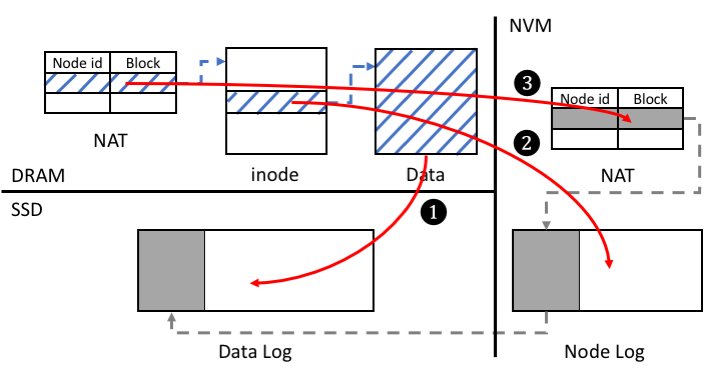
NVM 기반 노드 로깅 기법은 기존 F2FS에서 노드 로그와 파일 시스템 메타데이터를 NVM으로 저장함으로써 쓰기 속도와 체크포인팅 시간을 개선하여 fsync로 인한 성능 저하를 개선할 수 있다.
데이터 로그의 경우 기존 F2FS와 같이 SSD에 존재하며 노드 로그와 NAT는 NVM에 존재하게 된다. NVM에 노드 로그와 파일시스템 메타데이터를 쓸 때에도 일관성을 보장해야 하므로 기존의 Flush와 같이 (1) 데이터 로그, (2) 노드 로그, (3) 파일시스템 메타데이터의 순서로 저장하게 된다. 이때, 노드 로그와 NAT를 저장하는 순서는 일관성에 치명적이므로 clflush와 mfence 같은 명령들을 이용하여 캐시라인을 Flush하고 Reordering을 방지해야 한다.
성능 평가
NVM 노드 로깅 기법의 성능을 평가하기 위하여 파일시스템 스케일러빌리티 벤치마크인 FxMark을 이용하였다. 워크로드로는 fsync가 자주 호출되는 DWSL을 사용하였다.
- fsync 지연시간
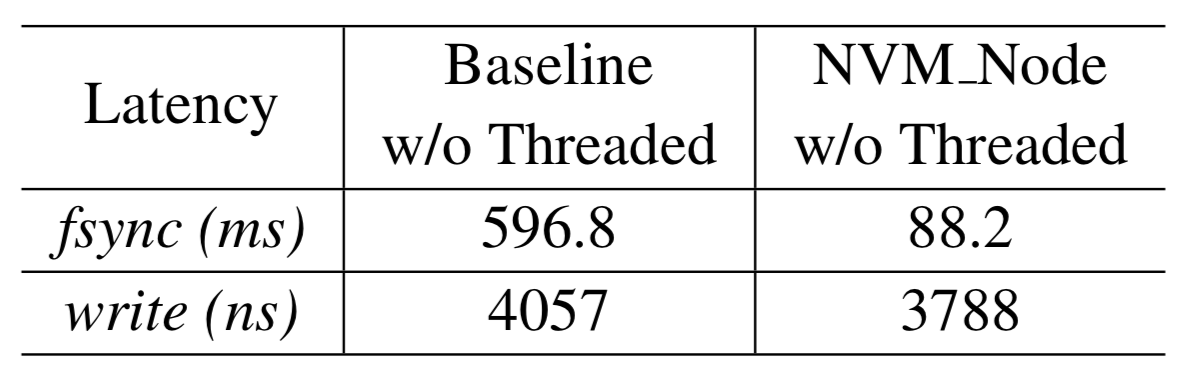
위의 표는 DWSL에서 기존 F2FS와 NVM 노드 로깅 기법의 fsync와 write에 대한 지연시간을 나타낸 표이다. NVM 노드 로깅 기법을 통하여 노드 로그 Flush와 체크포인팅 오버헤드가 감소함에 따라 fsync의 지연시간이 감소한 것을 확인할 수 있다.
- fsync 처리량
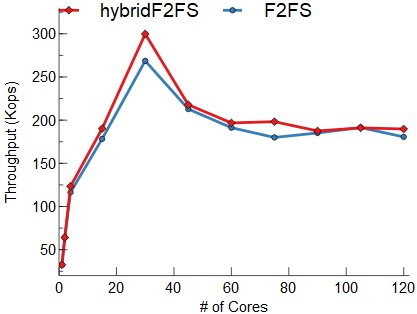
위의 그래프는 코어 수에 따른 DWSL에서의 처리량을 보여준다. Threaded 로깅으로 인한 변화를 보기 위하여 기존 F2FS와 NVM 노드 로깅 기법 모두 Threaded 로깅을 활성화/비활성화 했을 때에 대하여 모두 실험하였다. NVM 노드 로깅 기법을 통하여 fsync 오버헤드를 개선하여 기존 F2FS보다 처리량이 증가한 것을 볼 수 있다.
결과물
- 논문
- Write Optimization of Log-structured Flash File System for Parallel I/O on Manycore Servers, C.-G. Lee, H. Byun, S. Noh, H. Kang, Y. Kim, In Proceedings of the 12th ACM International Systems and Storage Conference (SYSTOR) (2019), Haifa, Israel, June 3-5, 2019.
- 공개 소프트웨어
- Github: hybridF2FS
- 시연 동영상