블록 레이어 스케일러빌러티
연구 개요
CPU core가 많아짐에 따라 리눅스 블록레이어에서 request_queue에 대한 경합이 발생하였다. CPU 구조가 NUMA(Non Uniform Memory Access) 구조로 바뀌게 되면서 원격 메모리 접근을 할 때 로컬 메모리 접근을 할 때보다 속도가 느리며 메모리 일관성을 유지하기 위해 성능 저하가 발생한다. 이러한 문제를 없애기 위해 리눅스 블록레이어에는 기존의 request_queue의 구조가 single queue에서 multi queue구조로 발달하였다. multi queue는 크게 software queue와 hardware queue로 구성되며 software queue는 core의 request_queue에 대한 경합을 없애기 위해 만들었으며 hardware queue는 NUMA구조에서 원격 메모리 접근을 최소화하기 위해 만들어졌다. 하지만 이 블록레이어 multi queue에서는 지수적으로 늘어날 매니코어의 확장성에 대한 충분한 검증이 이루어지지 않았다. 이에 본 연구에서는 blk-mq 기반의 실제 IO를 발생시키는 보조 기억 장치 보다 비교적으로 빠른 RAM 블록 장치인 Ramdisk_MQ를 구현하여 다중 코어 환경에서 리눅스 블록 계층의 확장성 평가를 위한 환경을 구축하고 동시에 실제 IO를 발생시키지 않고 속도가 비교적 빠른 null_blk 장치를 이용하여 blk-mq 확정성에 대해 분석한다.
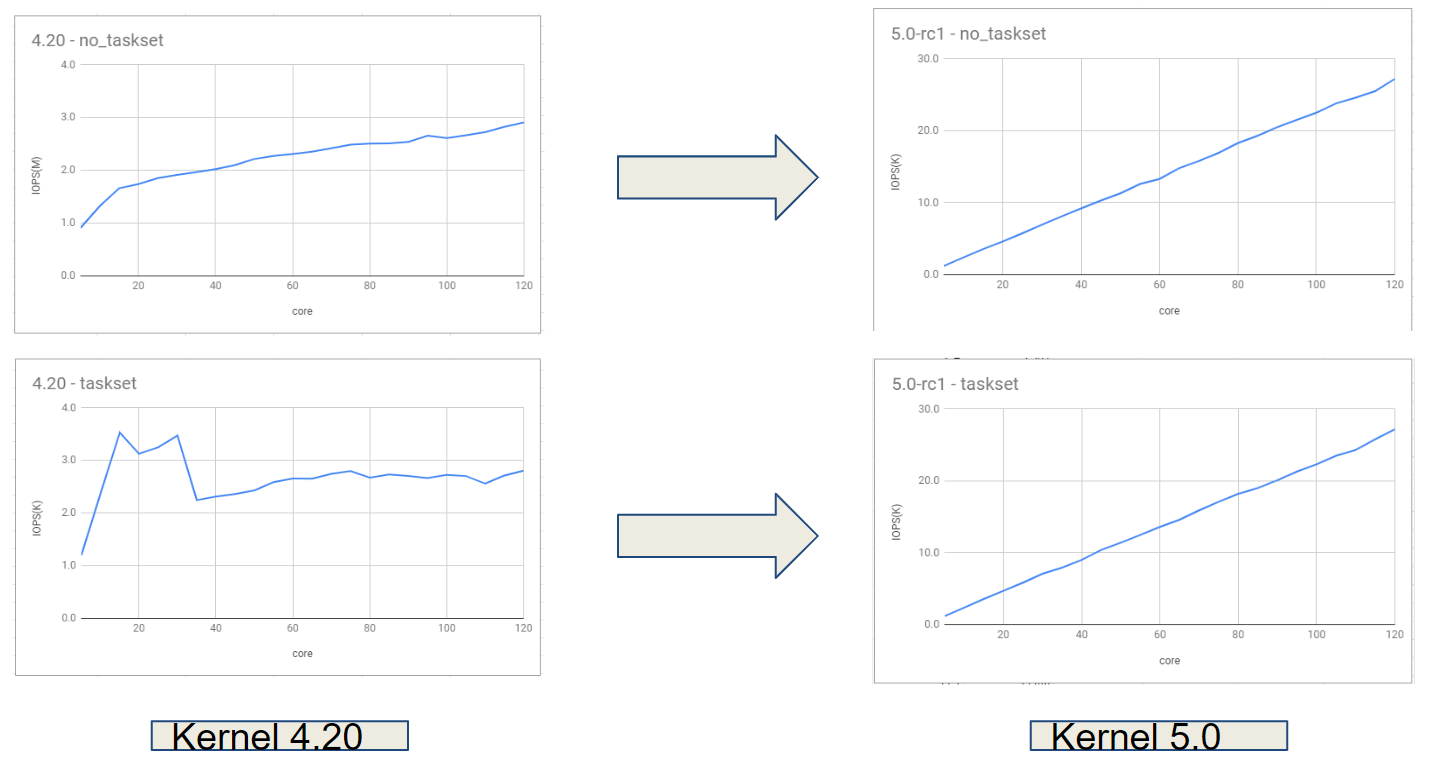
이후 커널 4.20 버전까지는 블록 계층의 코어 확장성이 NUMA Issue로 인해 보장되지 않았으나 커널 5.0 버전부터는 NUMA Issue가 제거되었고 확장성이 보장되나 하드웨어 큐의 갯수 및 크기의 제약 상황에서 확장성 성능 저하가 발생한다. 이에 따라 blk-mq 확장성에 대해 분석한다.
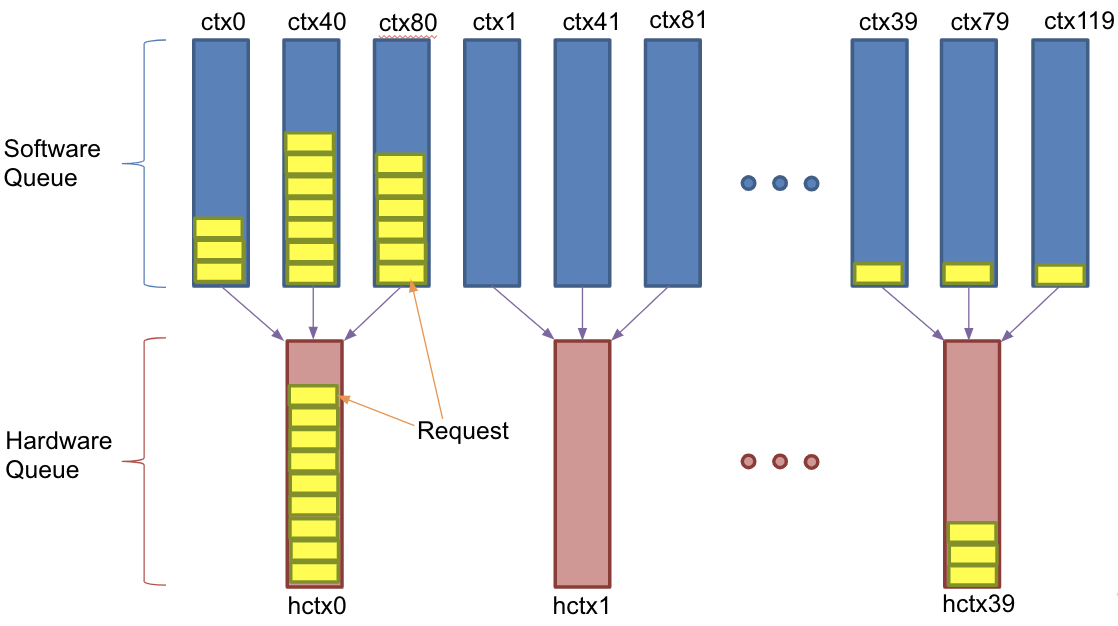
또한 블록 계층에서 소프트웨어큐 -> 하드웨어큐 간 매핑에서 I/O 요청 간 불균형이 있어 성능 하락이 있을 것으로 예상된다. 이에 대해 검증하며 실제 NVMe SSD에 파일 시스템을 올린 상황에서 블록 계층에 대해 확장성을 가지는지 검증한다.
관련 연구
- Linux Block IO : Introducing Multi-queue SSD Access on Multi-core System SYSTOR ‘13 - 해당 논문에서 blk-mq가 제안되었고 80코어까지 확장성 평가가 이루어졌다. 하지만 실제 데이터 입출력이 일어나지 않는 가상 블록 장치를 사용하여 제한적으로 평가된 바 있다.
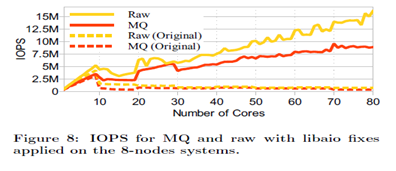
- Understanding Manycore Scalability of File Systems - 다른 논문으로는 위 논문이 있으며 다양한 워크로드를 이용하여 파일 시스템의 확장성을 검증하였다. 아래 그림에서 보듯이 파일 시스템은 대부분의 워크로드에서 확장성이 없음을 알 수 있다.
연구 내용
- Ramdisk_mq
매크로 벤치마크를 이용하여 blk-mq의 확장성 평가를 수행하기 위해서는 다음과 같은 조건을 만족하는 블록 디바이스가 필요하다.
- 블록 계층의 확장성 한계를 드러낼 수 있을 정도로 블록 디바이스의 입출력 성능이 충분히 높아야 한다.
- 블록 디바이스에 실제로 파일시스템을 생성하여 데이터 입출력을 수행할 수 있어야 한다.
하지만 현재 제품화되어있는 블록 디바이스 중 가장 고성능을 나타내는 제품은 플래시 메모리 등의 비휘발성 메모리 기반 SSD인데, 입출력 성능이 최대 1M IOPS 정도이기 때문에 최대 15M IOPS 이상까지 처리 가능한 blk-mq의 확장성을 평가하기에 적절하지 않다. 따라서 blk-mq 확장성 평가를 위해서는 실제로 존재하지 않는 가상의 고성능 블록 디바이스를 에뮬레이션해야 할 필요가 있다.
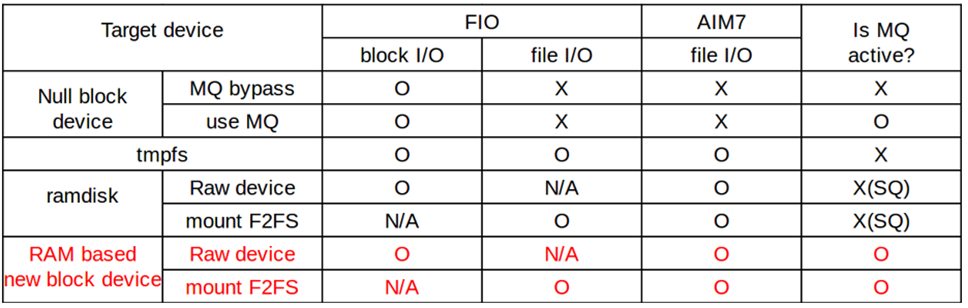
위 표의 첫 번째 열은 현재 리눅스 커널에서 지원하는 가상 블록 디바이스들을 나타내며, 두 번째 열부터는 매크로 벤치마크 기반의 blk-mq 확장성 평가를 위해 필요한 속성을 나타내는데, 어떤 가상 블록 디바이스도 모든 속성을 동시에 지원하지는 못함을 보여준다.
- null block device는 실제로 데이터를 저장하지 않기 때문에 파일 시스템을 설치할 수 없어 파일 입출력 기반의 매크로 벤치마크를 수행할 수 없다.
- tmpfs는 데이터 입출력 작업 시 블록 계층을 거치지 않고 바로 RAM에 접근하기 때문에 blk-mq의 확장성을 평가할 수 없다.
- ramdisk는 데이터 입출력 작업 시 블록 계층을 거치기는 하지만 단일 큐 기반의 경로를 이용하고 있기 때문에 blk-mq의 확장성을 평가할 수 없다.
따라서 본 연구에서는 위의 모든 속성을 제공하는 새로운 RAM 기반의 블록 디바이스인 ramdisk_mq를 구현하였다.
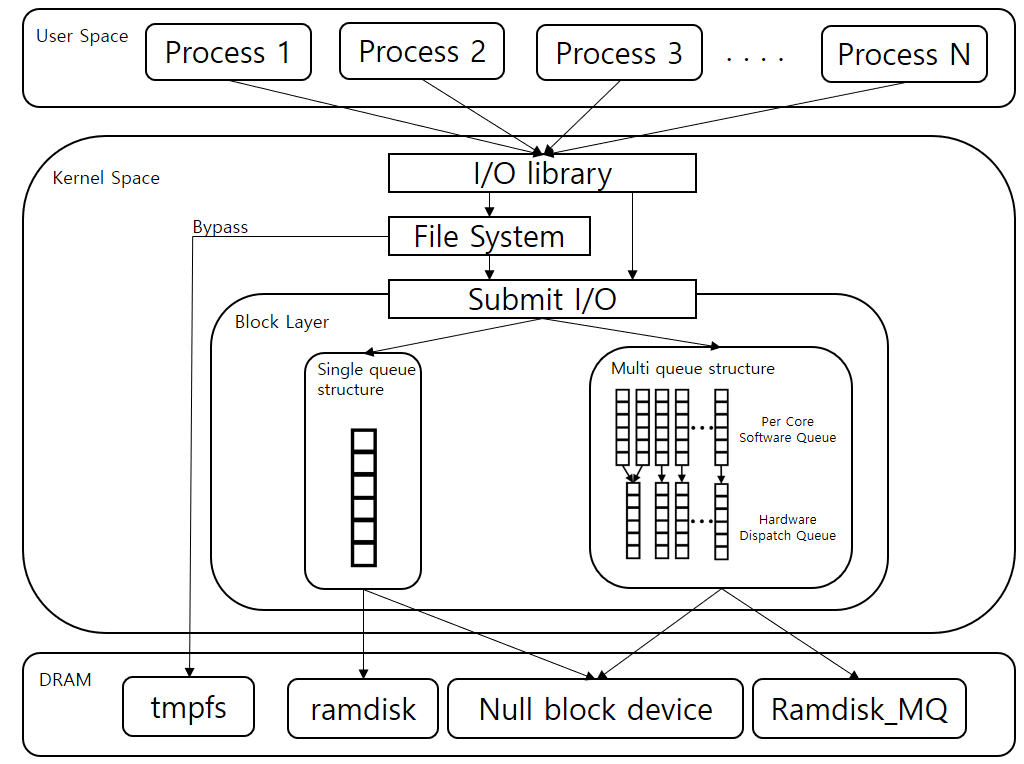
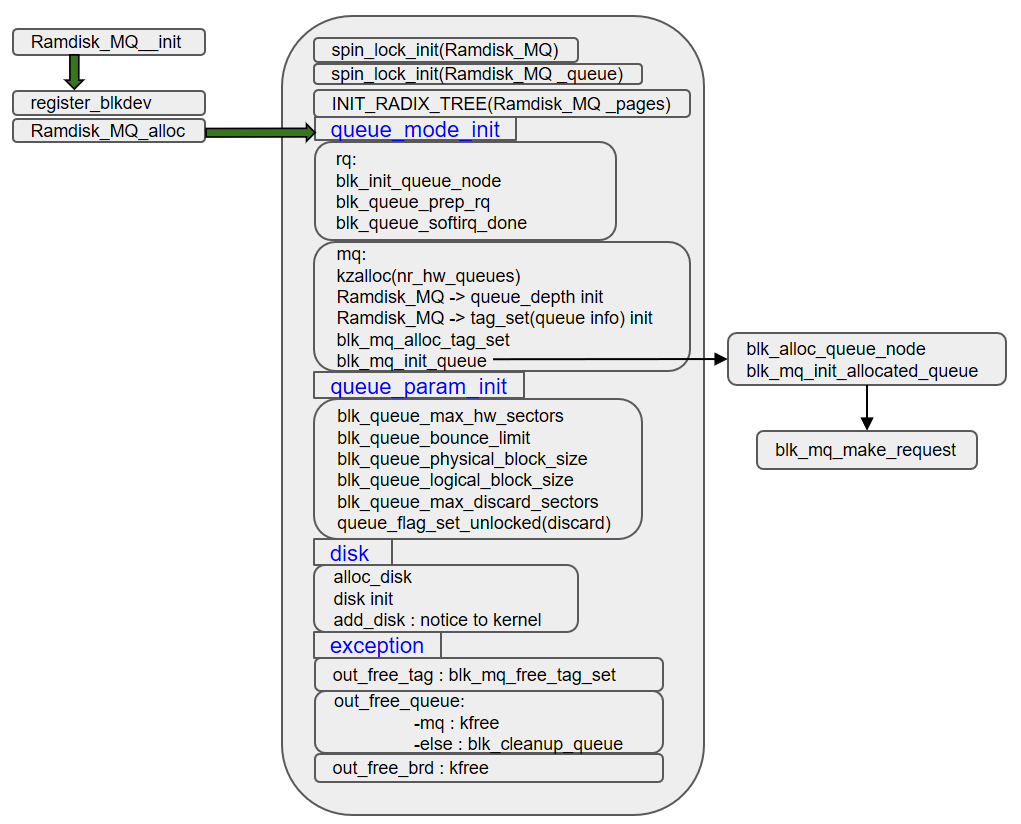
Ramdisk_MQ의 상세 코드 구조는 아래의 그림과 같고 기존 ramdisk 구조에 다중 큐 기반 블록 계층을 이용할 수 있도록 추가하였다. 다중 큐 기반 블록 계층을 이용하는 경우 Ramdisk_MQ가 데이터 입출력 요청을 받으면 blk_mq_init_queue() 함수를 호출하게 된다. 이 함수는 최종적으로 blk_mq_make_request() 함수를 호출하여 요청 받은 데이터 입출력 작업을 수행하게 된다.
-
Ramdisk_MQ 동작 검증
- F2FS file system 생성 , Ramdisk_MQ 디바이스 마운트 동작 실험
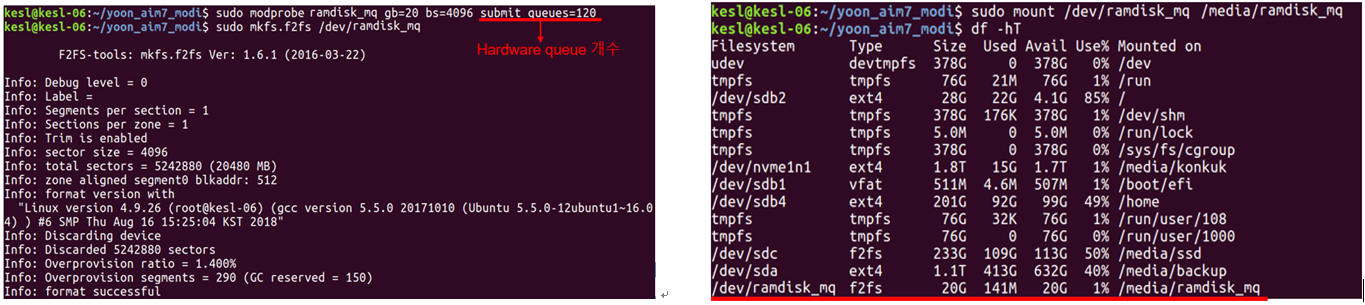
Ramdisk_MQ 모듈을 올릴 때의 옵션은 블록 크기=4K, 용량=20G, 하드웨어 큐 개수=120으로 설정하였다. 생성된 Ramdisk_MQ 블록 디바이스에 왼쪽 그림과 같이 mkfs.f2fs를 통해 F2FS 파일시스템을 생성하고, 오른쪽 그림과 같이 블록 디바이스 마운트 가능 하다.
- Write , Read 작업 확인 실험
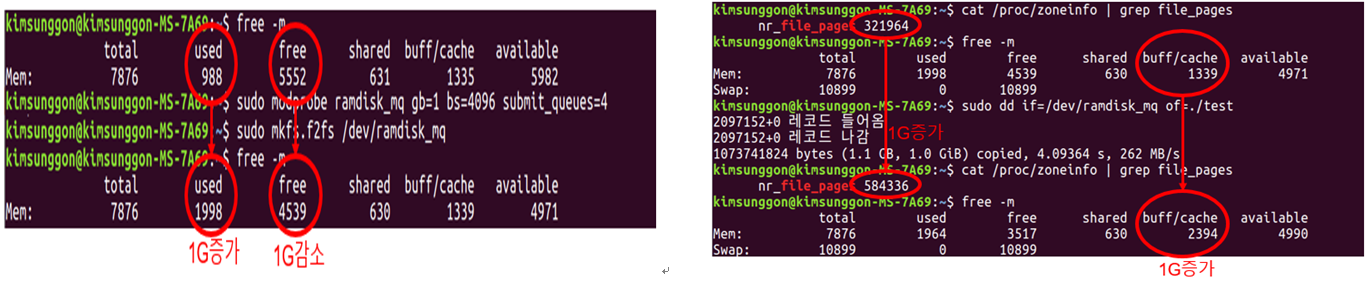
데이터 입출력을 발생시켜 정상적으로 RAM에 쓰기 및 읽기 작업이 수행되는지를 확인한다. 쓰기 작업은 왼쪽 그림과 같이 Ramdisk_MQ 모듈을 올리고 파일시스템을 생성하였을 때, RAM의 저장 공간 변화를 통해 확인하였다. 1GB 크기로 블록 디바이스를 생성하고 그 위에 파일 시스템을 생성하였기 때문에 RAM에서 1GB만큼의 저장 공간 변화가 일어나게 된다. 읽기 작업의 경우 오른쪽 그림과 같이 리눅스의 dd 명령어 수행을 통해 읽기 작업을 발생시켰다. 읽기 작업을 할 때 페이지 캐시에 데이터를 저장하므로 buff/cache의 크기가 1GB 증가한 것을 확인할 수 있다. 또한 page 개수가 약 32,000개에서 약 58,000개로 증가한 것을 확인할 수 있다. 한 개의 페이지 크기가 4K이므로 4K*26,000인 약 1GB가 증가한 것이다. 이를 통해 실제 RAM에서 읽기 및 쓰기 작업이 정상적으로 진행됨을 확인할 수 있다.
-
Ramdisk_MQ를 이용한 blk-mq 확장성 평가 실험
- FIO Benchmark , AIM7 Benchmark
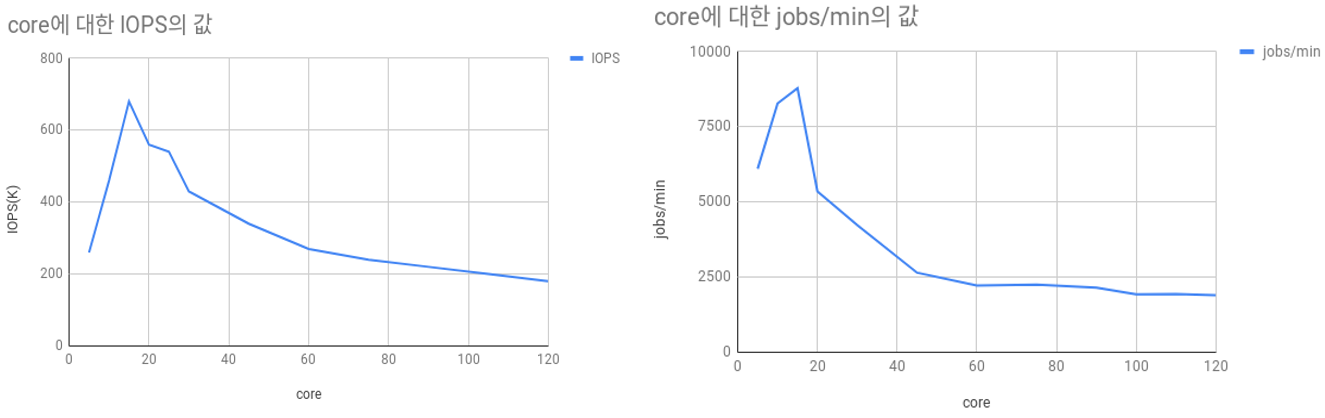
Ramdisk_mq에서 FIO와 AIM7 두 개의 벤치마크를 이용하여 코어 개수 증가에 따른 blk-mq의 확장성을 테스트하였다. 위 실험결과에 따르면 두 벤치마크에서 공통적으로 15코어 이후 성능이 감소하는 확장성의 한계를 확인할 수 있다.
- 하드웨어 큐 제약에 따른 확장성
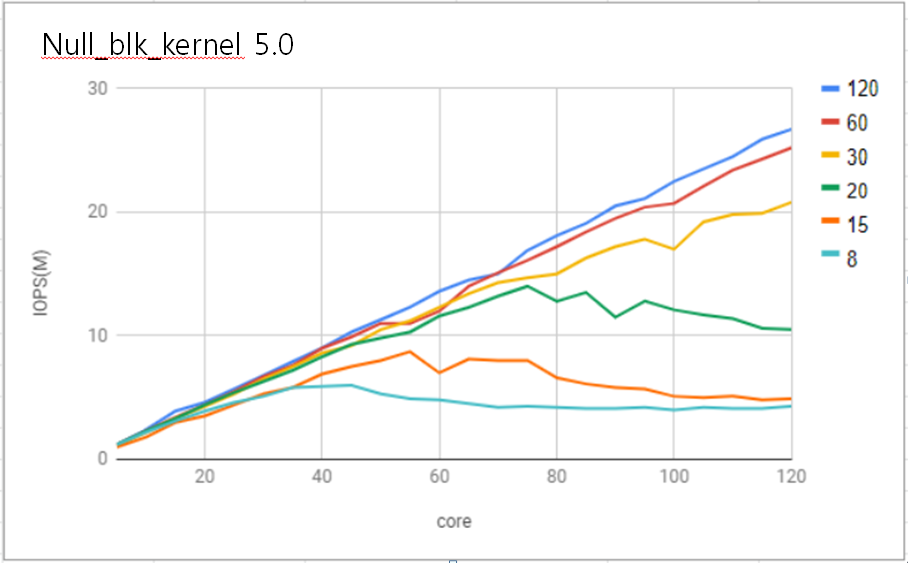
리눅스 블록레이어 스케일러빌리티는 실제 NVMe SSD 디바이스의 IO queue의 개수와 맞게 생성되는 블록레이어의 하드웨어 큐 개수에 제약을 받는다. 충분히 빠른 가상 장치인 null_blk을 이용하여 fio(Flexible IO) 벤치마크에서 성능 평가를 한 결과 120코어 머신에서 하드웨어 큐 개수가 약 20개부터 확장성이 사라지는 것을 확인하였다. 하드웨어 큐 개수가 20개일 때 약 75코어까지는 확장성을 보이지만 이후에는 오히려 성능 저하 현상이 발생하였다.
- Multi queue 병목점 분석
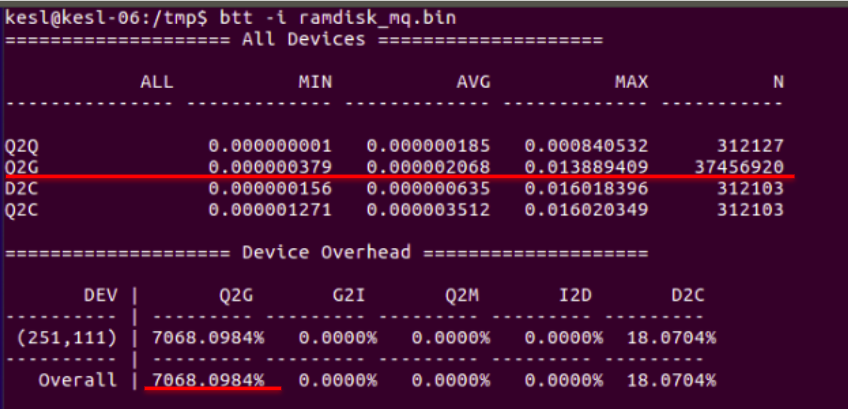
Blktrace의 매니코어 시각화 도구인 BTT(Blktrace timeline)를 이용해 병목 지점을 발견하였다. Q는 queue의 약자로 make_request_fn이 실행되어 bio의 처리가 시작되었음을 뜻한다. G는 get_request의 약자로 request 구조체가 하나 할당되었음을 뜻한다. I는 insert의 약자로 앞서 생성(되고 merge)된 request가 I/O 스케줄러에게 전달되었음을 뜻한다. M은 merge의 약자로 요청된 bio가 (앞선) request와 통합되었음을 뜻한다. D는 dispatch의 약자로 드라이버에게 I/O 연산의 실행을 시작하라고 요청하였음을 뜻한다. C는 complete의 약자로 dispatch된 request의 처리가 완료되었음을 뜻하는 것이다. 확인한 결과 blktrace의 플래그 중 Q(queued)와 G(get_request)사이인 Q2G구간에서 병목 현상이 생기는 것을 확인하였다.
- nr_requests와 확장성
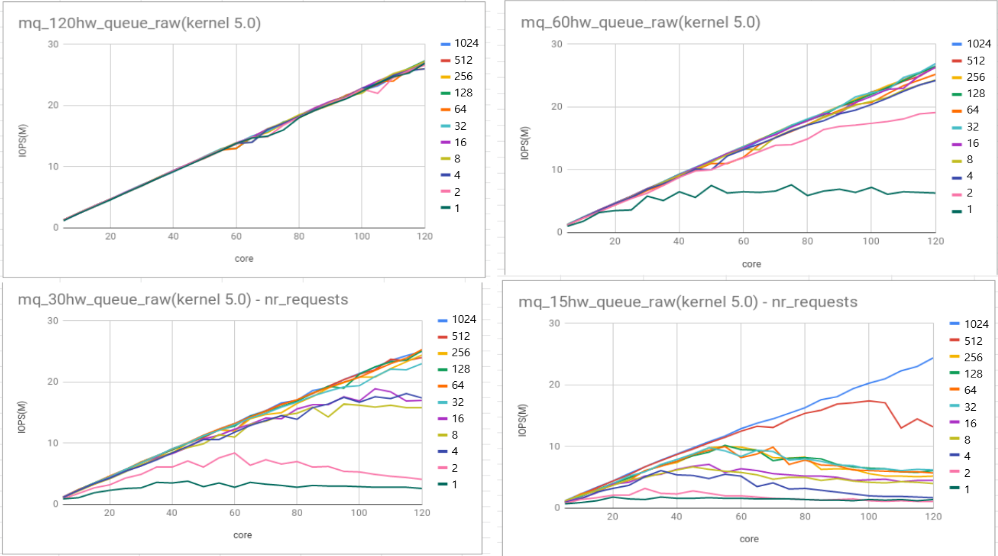
get_request()함수에서 최대 request를 제어하는 변수인 nr_requests보다 많은 request가 생성되면 커널이 쓰레드를 sleep시키고 waitqueue로 보낸다는 것을 확인하였다. null_blk의 default nr_requests값이 64인 것을 확인하였으며 nvme에서는 1024인 것을 확인하였다. 또 이는 하드웨어 큐 깊이와 동일하게 초기화하는 것을 확인하였다. 하드웨어 큐 개수와 nr_requests에 따른 성능 평가를 하였고 nr_requests 블록레이어 확장성과 관련된 중요한 요소임을 확인하였다.
- Multi queue 확장성의 한계
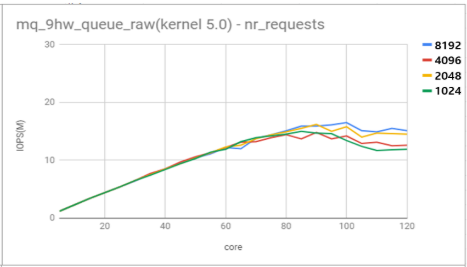
하지만 여전히 120코어 머신에서 하드웨어 큐가 약 9개 이하일 때 nr_requests를 높여도 확장성이 사라지는 것을 확인하였다.
즉, 리눅스 블록레이어 스케일러빌리티는 하드웨어 큐 개수에 의존적이다. 하드웨어 큐 개수가 적으면 확장성이 사라지지만 최대 request 개수를 제어하는 변수인 nr_requests를 높여 하드웨어 큐 개수가 적을 때에도 확장성을 향상시킬 수 있다. 하지만 nr_requests보다 하드웨어 큐 개수가 스케일러빌리티에 우선순위 요소라 볼 수 있으며 120코어 머신에서 하드웨어 큐 개수가 9개일 때 nr_requests를 높여도 약 80코어부터 확장성이 사라진다.
- 폴링 사용 시 확장성
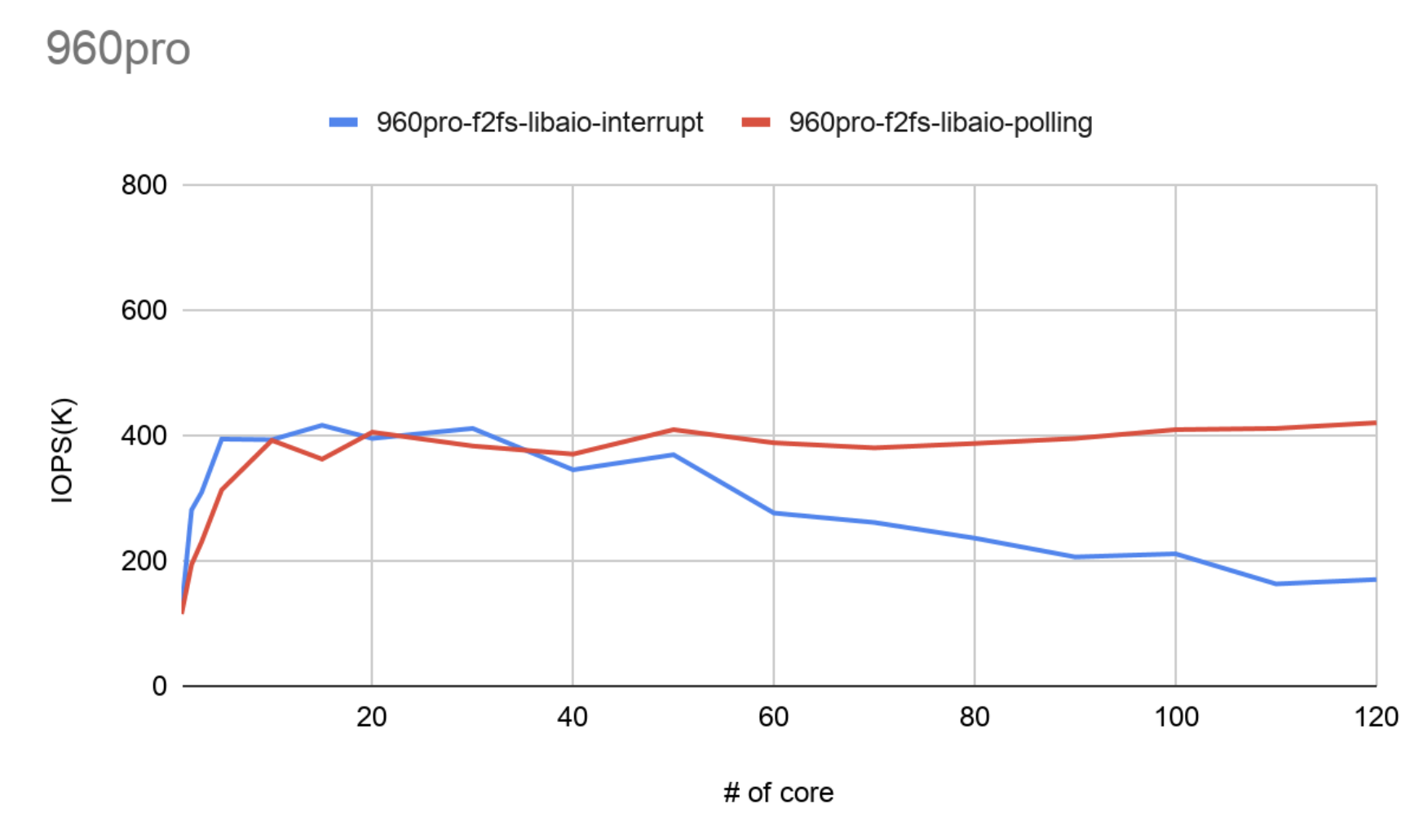
nvme 드라이버를 인터럽트로 설정하였을 때와 폴링으로 설정하였을 때 성능을 비교한 그래프이다. 초반에는 인터럽트의 우위를 확인할 수 있지만 인터럽트는 확장성이 없는 모습을 보이고, 코어가 많아질수록 성능이 떨어지는 모습을 확인할 수 있다. 폴링을 사용하는 경우 성능이 떨어지지않고 끝까지 유지되며 확장성이 있는 모습이 확인된다.
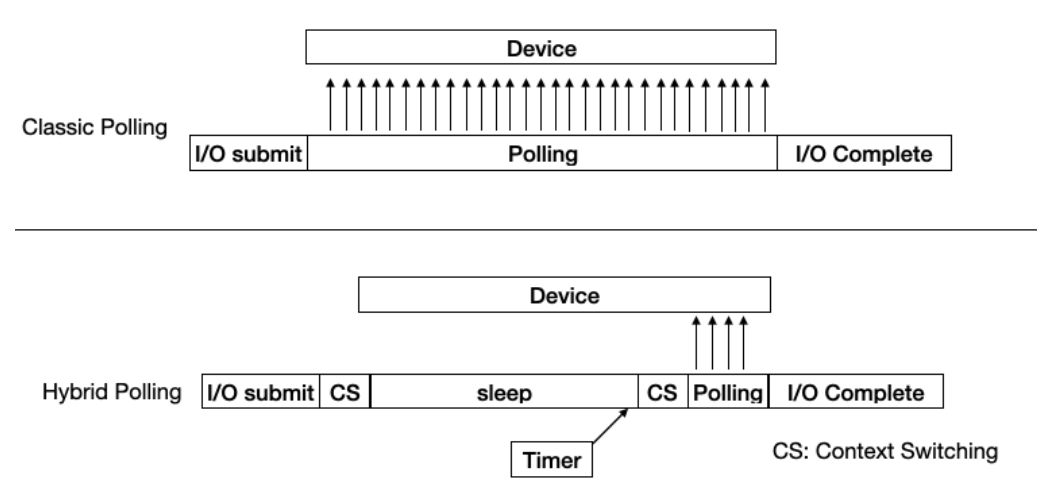
- 하이브리드 폴링
기존 폴링의 경우는 I/O 요청을 보내는 즉시 완료되었는지 확인하는 작업을 시작한다. 이로 인해 CPU를 과도하게 사용하는 문제가 있고 이 문제를 해결하기 위해서 하이브리드 폴링 방법이 제시되었다. 하이브리드 폴링은 요청을 보내고 일정 시간 sleep 한 후 I/O가 완료되었는지 확인하는 작업을 시작한다. sleep 시간을 동적으로 동작하도록 설정할 경우 최근 I/O 완료 시간의 평균으로 동작하게 되며 고정값으로 설정할 수도 있다. 각각의 동작 방식은 아래 그림과 같다.
각 방식의 성능을 측정한 결과는 아래와 같다.
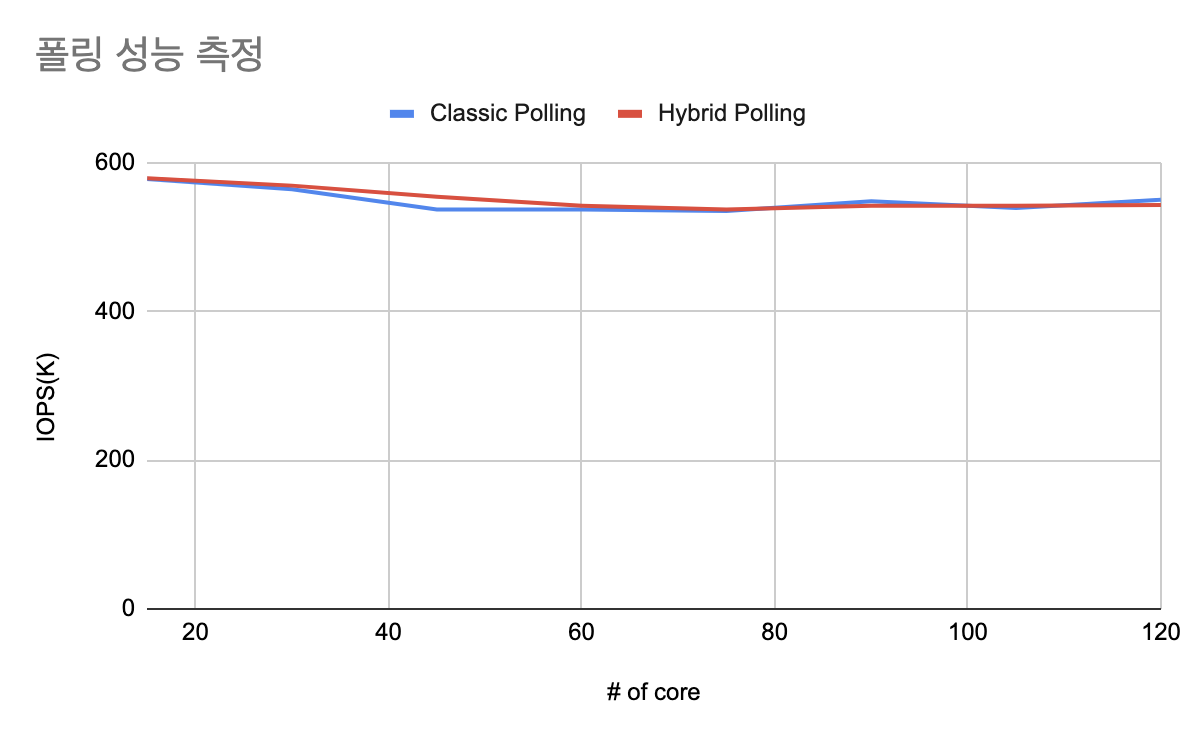
기존 폴링과 하이브리드 폴링의 성능 차이는 거의 없는 것을 확인할 수 있다. 두 방식 모두 SSD의 한계 성능을 확보하는데 문제가 없는 것 또한 확인되었다.
하지만 CPU 점유율 관점에서는 큰 차이를 확인할 수 있다.
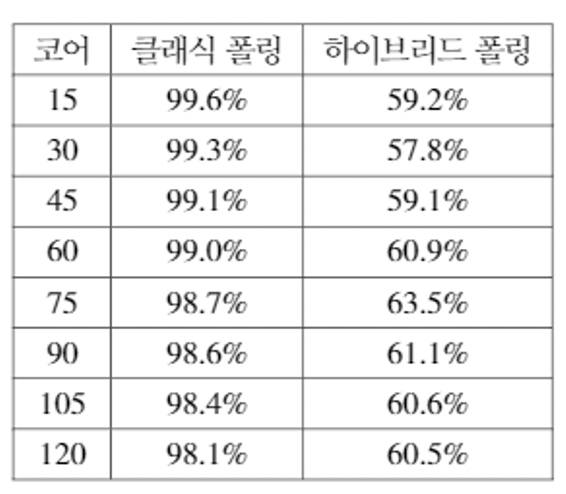
기존 폴링의 경우 100%에 가까운 점유율을 보이지만 하이브리드 폴링의 경우 60% 정도의 CPU 점유율을 보이며 성능 상에 이득을 볼 수 있음을 확인할 수 있다.
- 멀티 큐 밸런스 체크
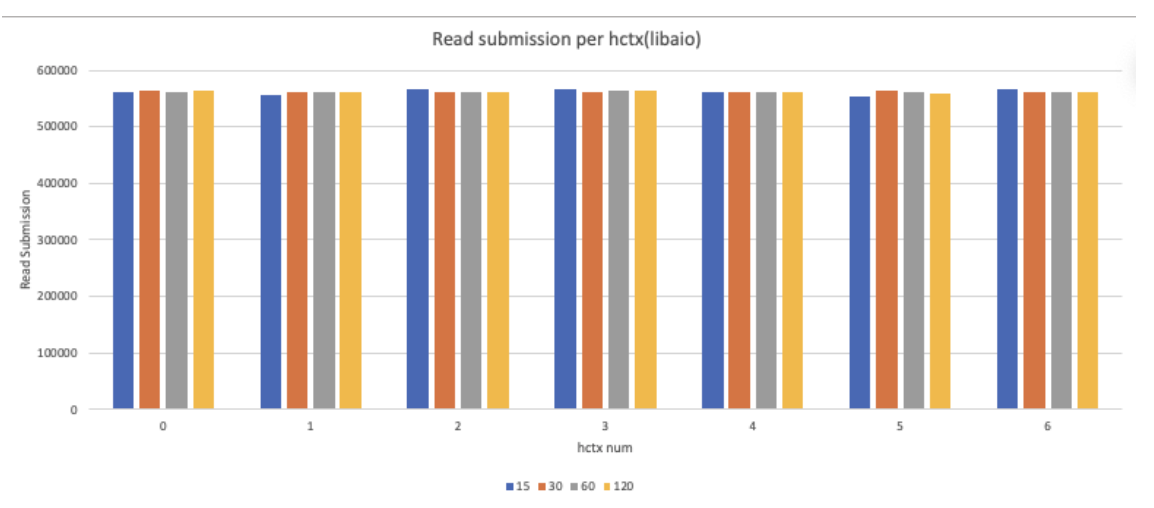
blktrace와 blkparse를 이용하여 데이터 수집 환경을 마련하고 fio를 실행하였다. 그 후 확보한 데이터를 이용하여 하드웨어큐 밸런스가 맞는지 확인해보았다. fio의 job 개수를 변화시키면서 확인해 본 결과 job 개수와 상관 없이 각 하드웨어큐에 들어가는 read 개수는 비슷한 것으로 확인되었다.
- 파일 시스템 확장성
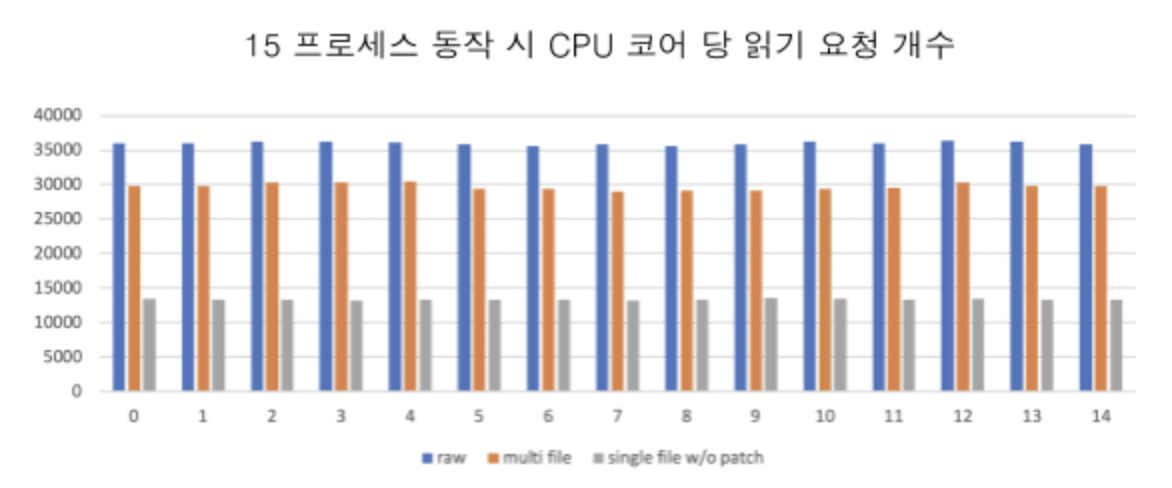
위의 멀티 큐 밸런스 체크 작업을 하던 도중, F2FS 파일 시스템에서 단일 파일에 대해 읽기 작업을 하는 경우 성능이 낮은 문제를 확인하였다. 원인 분석 작업을 진행하였고 읽기 작업 시에도 잠금이 걸려 확장성이 없는 것으로 확인되었다.
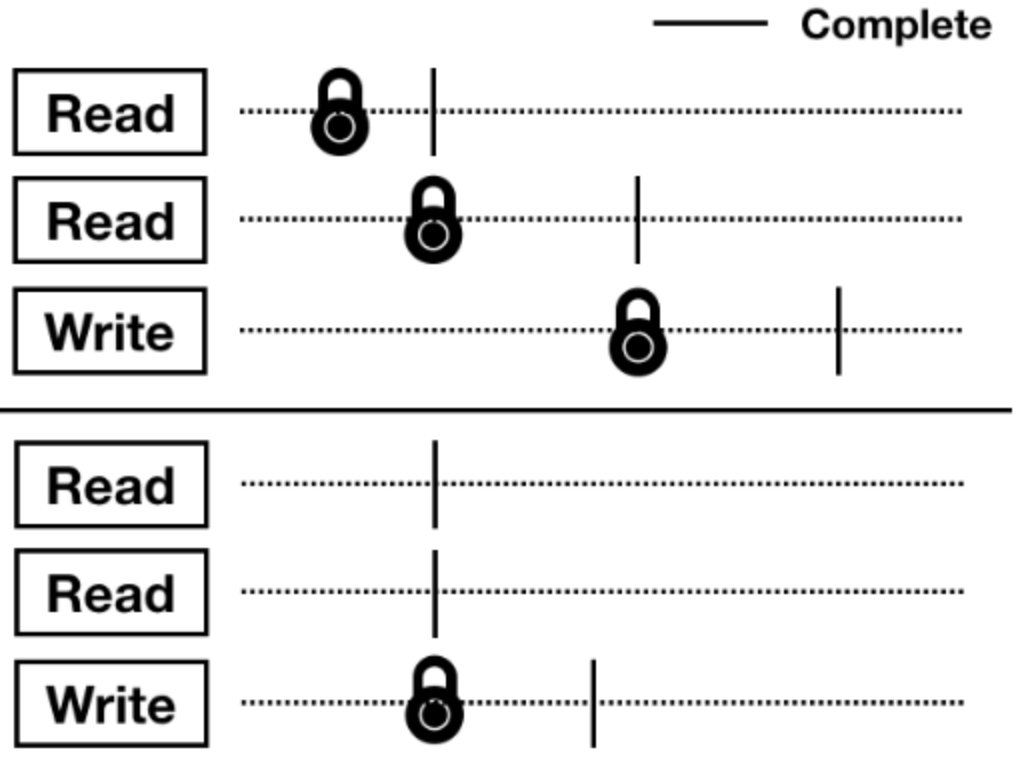
따라서 읽기 작업 시에는 위와 같이 잠금이 걸리지 않도록 수정하는 커널 패치를 진행하였고 수정 후 추가 실험을 진행하였다.
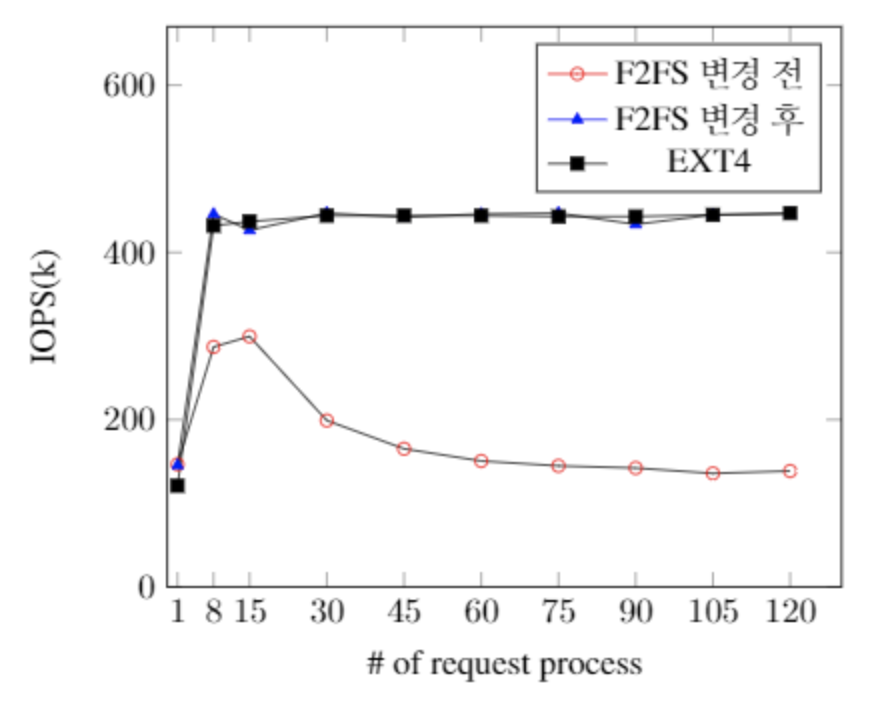
F2FS의 확장성 문제가 해결되어 EXT4 파일시스템과 비슷한 성능을 보이는 것을 확인할 수 있다. 위 패치는 리눅스 커널 5.7버전에 통합되었다.
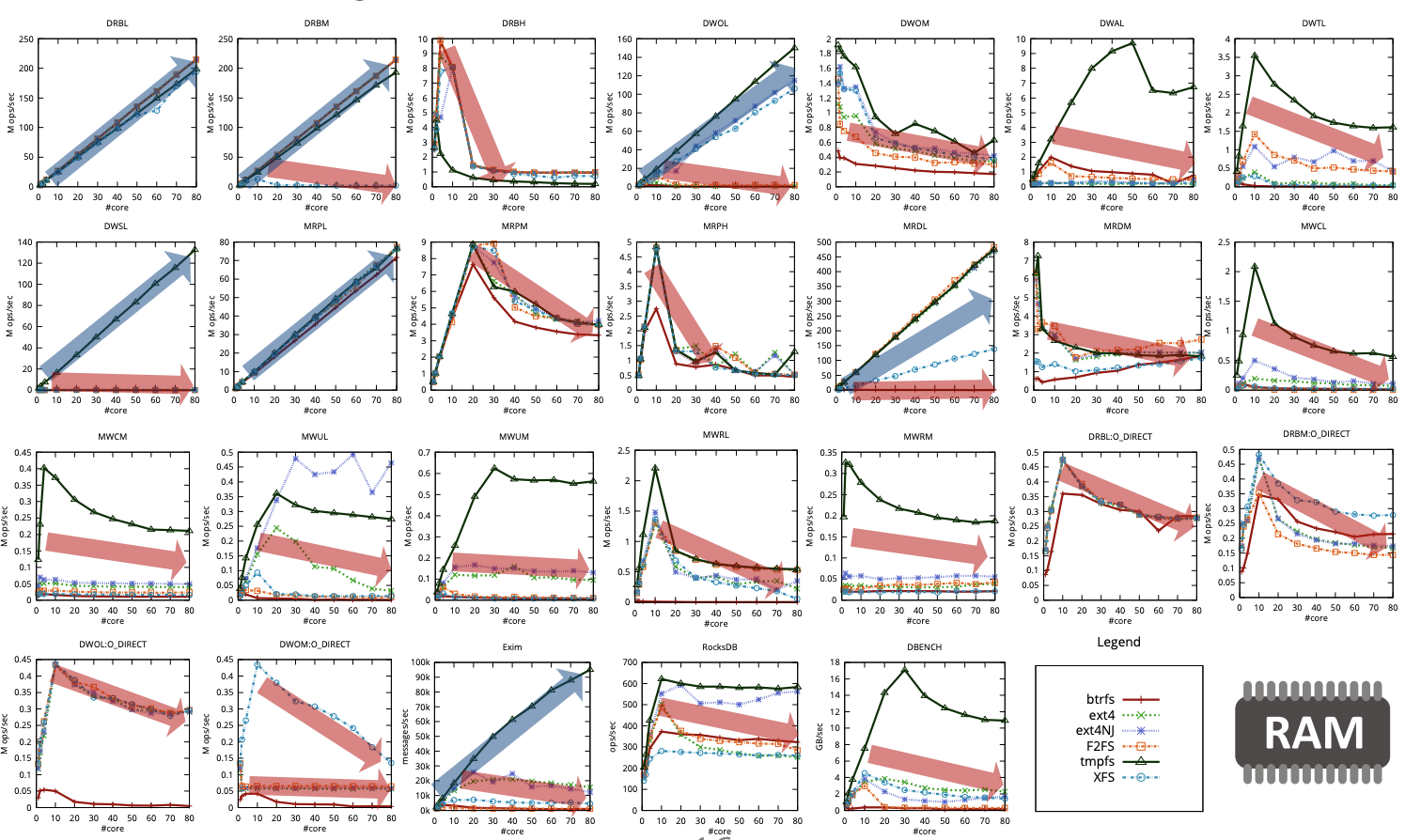
Btrfs의 확장성에 대한 분석도 진행하였으며 Btrfs 또한 아래 그래프와 같이 확장성이 없음을 확인할 수 있다.
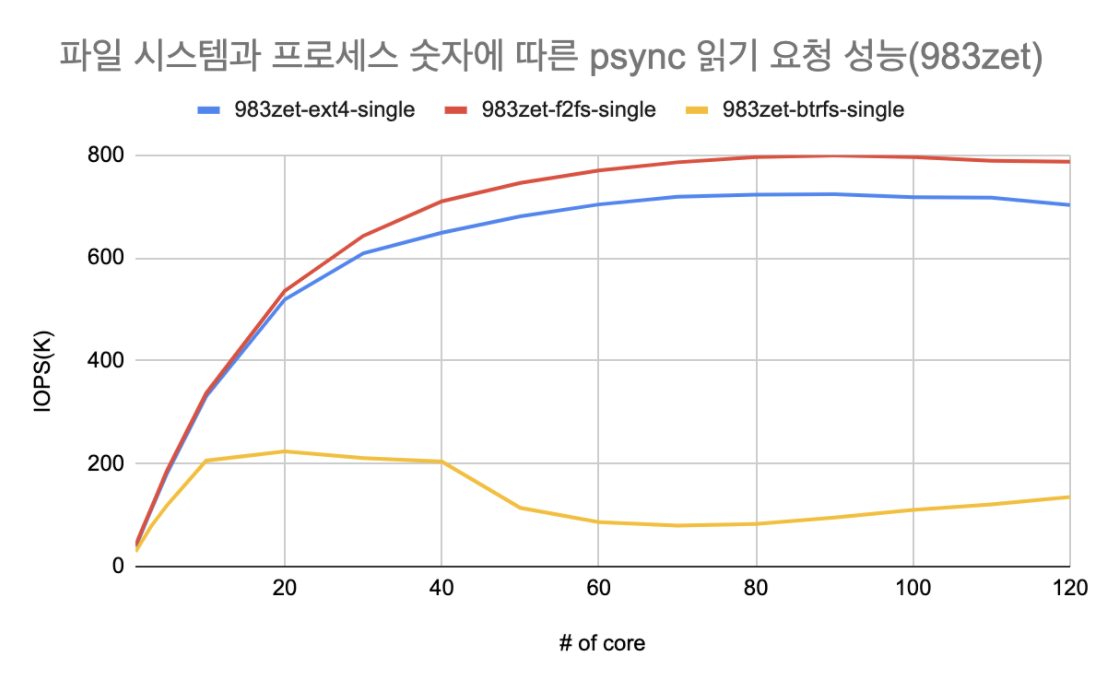
위 그래프는 fio의 pvsync2엔진을 이용하여 실험한 데이터이며 타 파일 시스템은 120코어까지 확장성이 있음을 확인하였다. 하지만 Btrfs의 경우 20코어 지점까지는 성능이 어느정도 상승하지만 그 이후로는 확장성이 없으며 성능이 떨어지는 모습을 확인할 수 있었다.
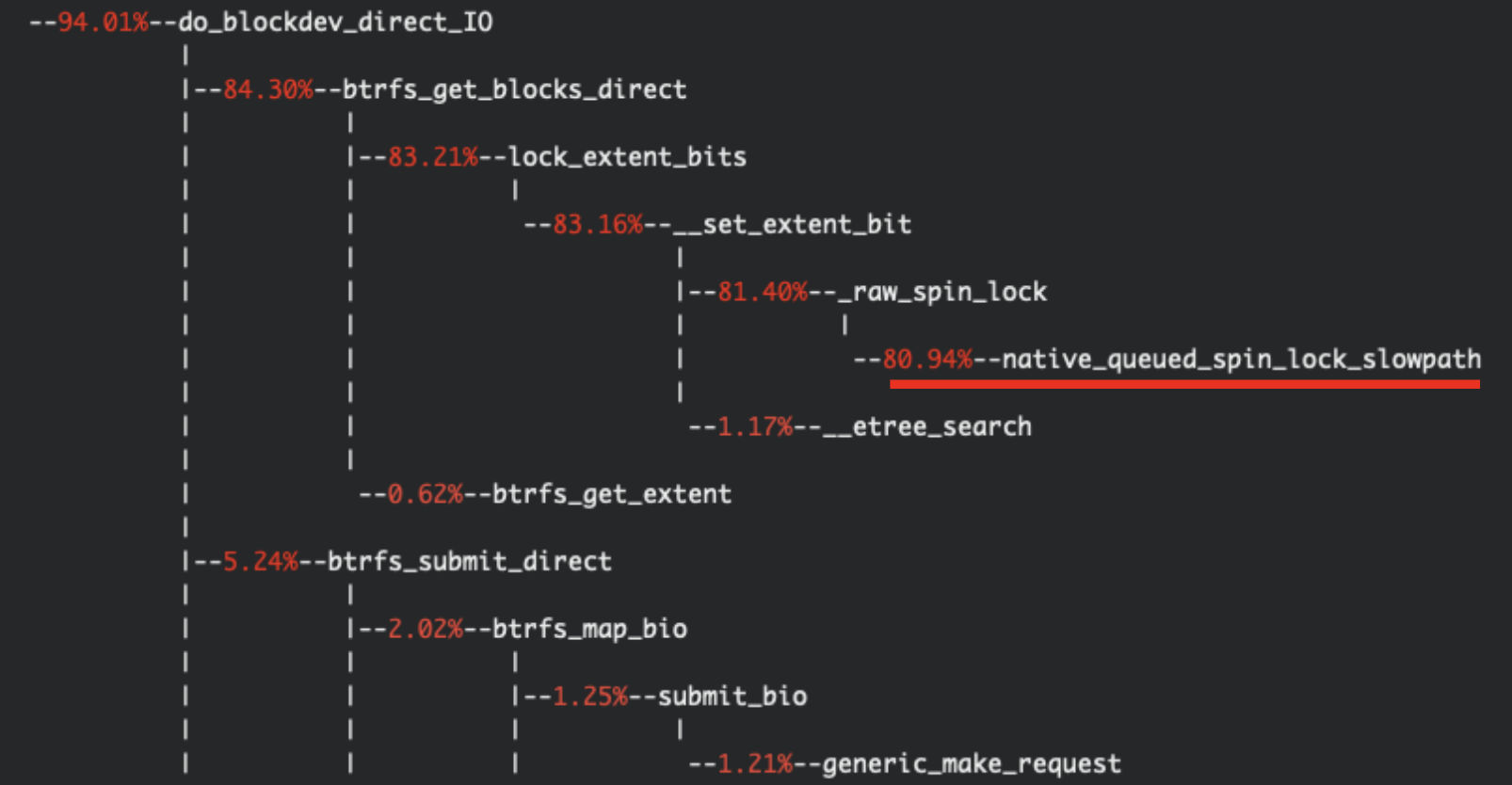
성능이 올라오지 않는 원인을 분석한 결과 위 그림과 같이 과도한 spinlock에 의해 성능이 제대로 나오지 않는 모습을 확인하였다. 이를 해결하기 위한 수정 사항을 확보하여 추가 실험을 진행하였다.
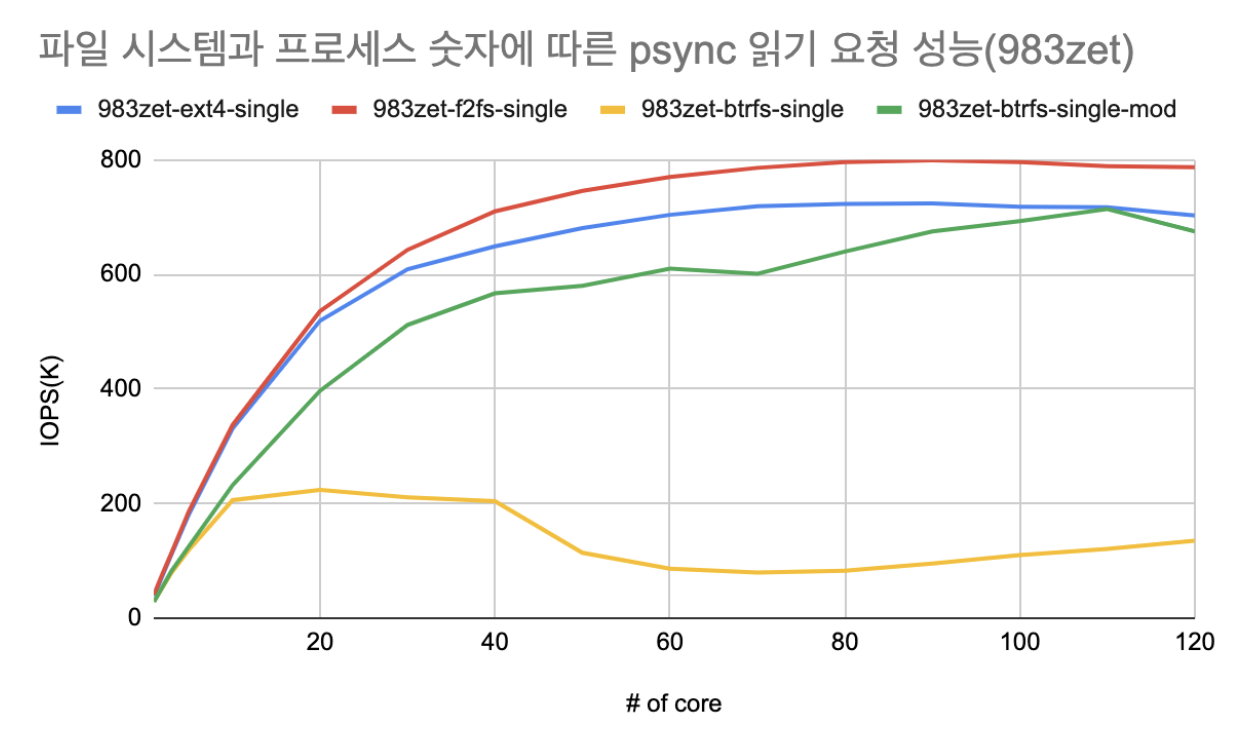
확장성이 어느정도 해결되어 성능이 올라와서 유지되는 모습을 확인할 수 있다.
- 하이브리드 폴링 기법 개선 연구
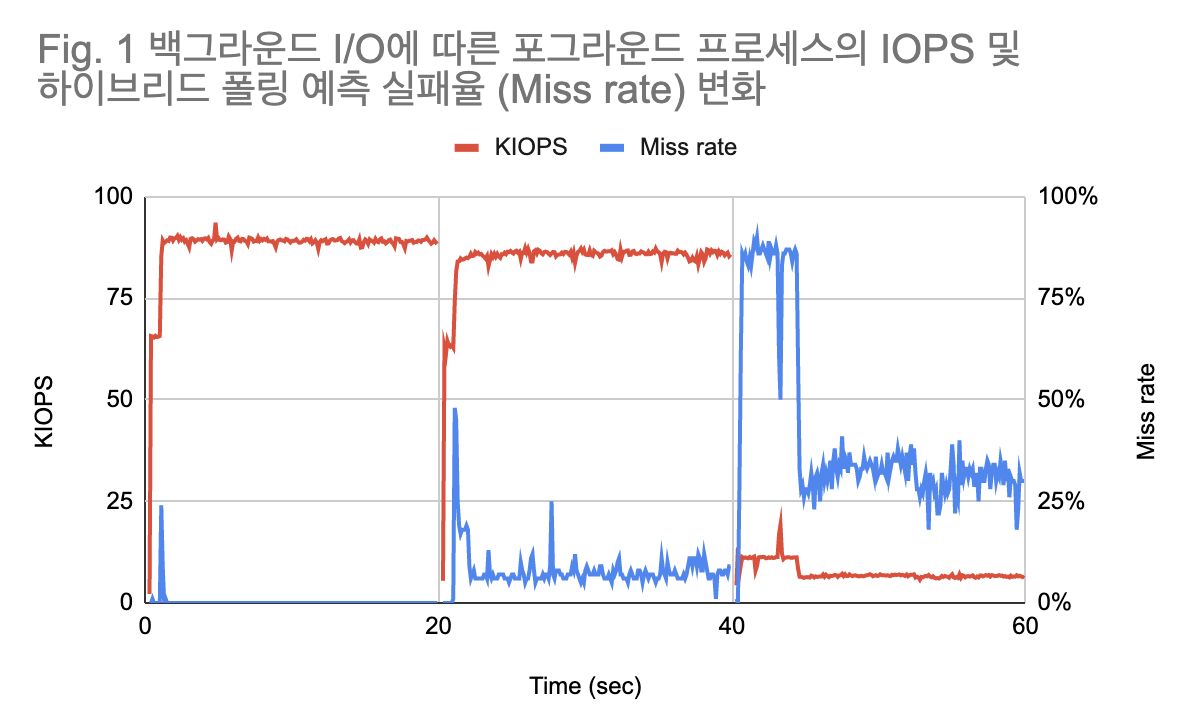
위 그래프는 기존의 하이브리드 폴링로 포그라운드 프로세스 1개와 백그라운드 프로세스 4개를 동시에 실행시킴으로써 40~60초 구간에서 하이브리드 폴링의 예측 실패율이 급격하게 올라가는 상황이다. 기존의 슬립 시간 결정 알고리즘은 최근에 발생한 I/O 응답 시간 평균값의 50%를 슬립 시간으로 사용한다. 이러한 방식의 약점은 일시적으로 긴 응답시간을 가진 I/O가 발생했을 경우 최근 응답 시간의 평균을 과도하게 올려 예측 실패율이 올라가는 것이다. 이를 개선하기 위한 방안 중 하나로 I/O 슬립 시간에 평균값 대신 최솟값을 적용하는 것을 고려할 수 있다. 또한 현재 50% 및 100ms로 고정되어 있는 슬립 시간 비율 및 업데이트 주기에 대해서도 설정 공간 탐색을 통해 최적값을 구할 필요가 있다.
본 연구에서는 다양한 슬립 시간 결정 알고리즘에 대한 신속한 프로토타이핑 및 설정 공간 탐색을 지원하는 하이브리드 폴링 시뮬레이터를 개발했다. 시뮬레이터의 동작 방식은 다음과 같다.
- 입력: 커널에서 각 I/O에 대한 처리 시간을 수집하며, 이 데이터는 시뮬레이터의 입력값으로 들어가게 된다.
- 설정: 첫째, 시뮬레이터에서 실행하고자 하는 슬립 결정 알고리즘을 선택한다. 현재는 최솟값과 평균값 중 하나를 선택할 수 있으며 간편하게 다른 규칙을 추가할 수 있다. 둘째, 테스트하고자 하는 슬립 시간 비율 및 업데이트 주기의 범위를 설정한다.
- 실행: 시뮬레이터는 입력한 설정치 조합 및 입력 I/O 패턴 데이터에 대해 (1) 하이브리드 폴링의 예상 I/O 성능, (2) CPU 점유율, 그리고 (3) CPU 코어 당 IOPS, 즉 동일 IOPS를 확보하기 위해 CPU 자원을 얼마나 효율적으로 사용했는지에 대한 평가지표를 계산한다.
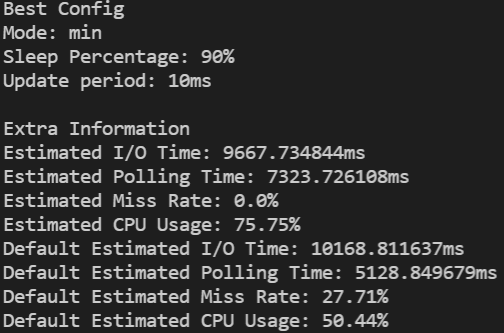
- 분석: 시뮬레이터는 다수의 설정치 조합 중 입력된 I/O 패턴 데이터에 대해 최선의 결과를 보이는 설정치 조합을 찾아 (그림 3)과 같이 보고한다. 또한 성능 개선 수치의 비교를 위해 기본 하이브리드 폴링 알고리즘의 실행결과도 제공한다.
- 활용: 시뮬레이터를 이용하여 찾은 설정치 조합을 커널에 적용할 수 있으며 이를 통해 성능이 개선된 하이브리드 폴링 알고리즘을 사용할 수 있다.
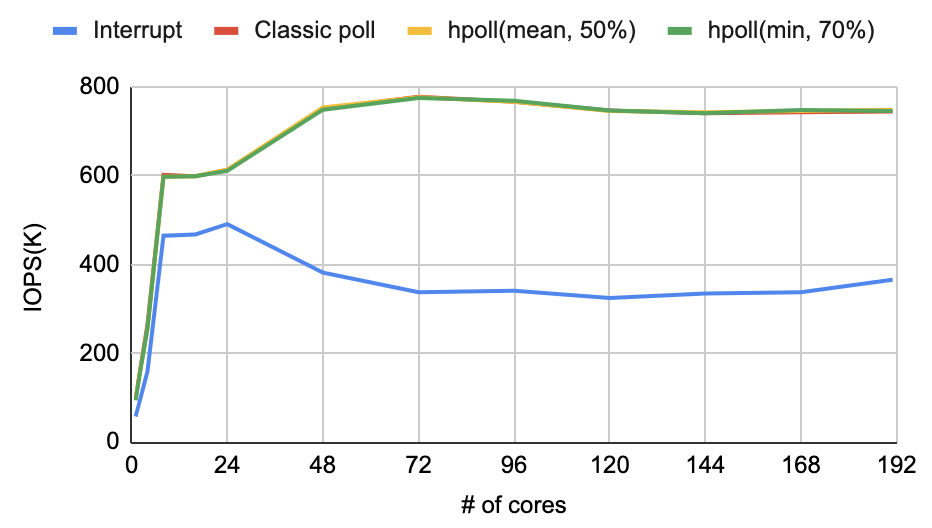
다양한 I/O 패턴에 대해 시뮬레이션을 수행한 결과 최솟값 모드 및 70%~90%의 슬립 시간 비율이 평균적으로 우수한 성능을 보여주었다. 그리고 시뮬레이터로 확보한 설정값을 실제 커널에 적용하고 매니코어 시스템에서 검증을 수행하였다. 실험에는 최솟값 설정, 70% 슬립 비율, 업데이트 주기 10ms를 사용하였으며 32KB 임의 읽기 작업 하나를 백그라운드 I/O로 지정하고 나머지 191코어에 대해 4KB 임의 읽기 작업을 수행하며 성능을 측정하였다. 실험 결과 클래식 폴링 및 기본 하이브리드 폴링과 같은 성능을 확보할 수 있는 것을 확인했다.
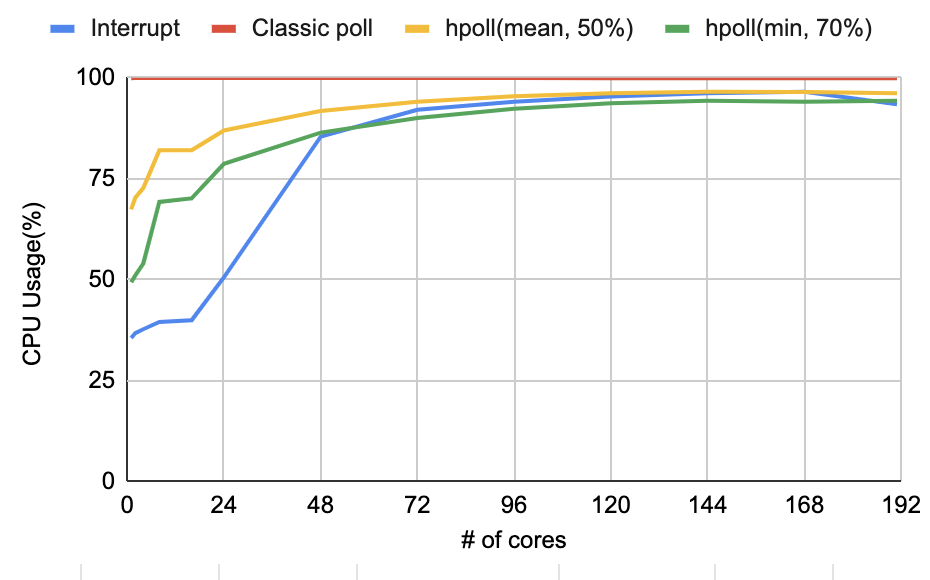
CPU 사용률 관점에서는 기존 하이브리드 폴링 대비 4코어까지는 20%p, 8-24코어에서는 평균 11%p의 추가 절감을 확보하였다. 하지만 48코어부터는 절감 폭이 3%p로 줄어들었다.
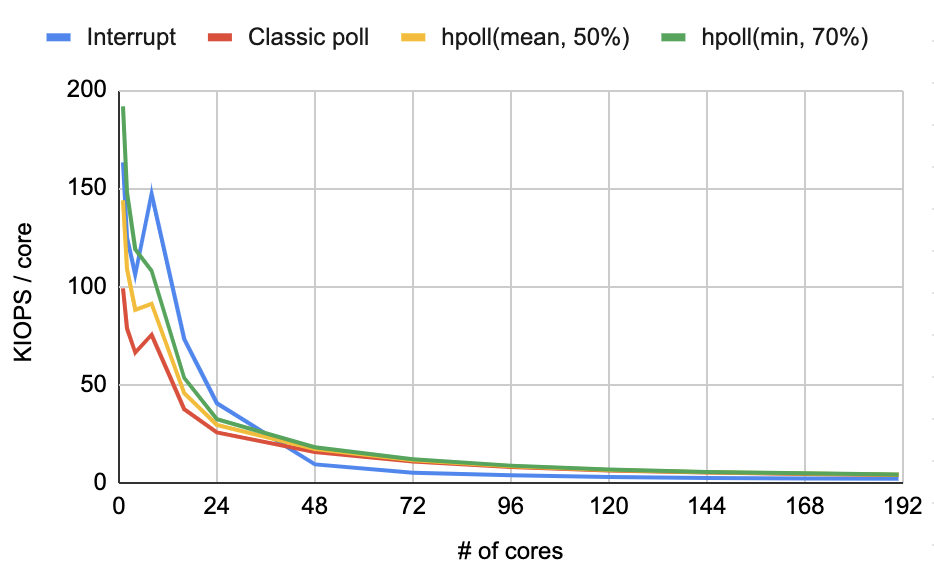
CPU 자원 사용 대비 I/O 성능을 확인할 수 있는 지표인 KIOPS/core에 대한 비교 결과이다. 24코어까지는 인터럽트의 CPU 자원 활용 효율이 가장 높은 것을 볼 수 있다. 하지만 인터럽트는 IOPS 값이 다른 방법 대비 제일 낮은 한계가 있다. 인터럽트를 제외하고 폴링 기법 간에 비교한 결과 본 연구에서 제안한 신규 설정치 (min, 70%, 10ms)가 KIOPS/core 관점에서도 가장 우수한 결과를 보여주었다.
결과물
- 논문
- 공개 소프트웨어
- Github: ramdisk_mq
- Github: blk-mq-analyzer
- Github: conf-hpoll