스케일러블 blocking 동기화 기법
연구 배경
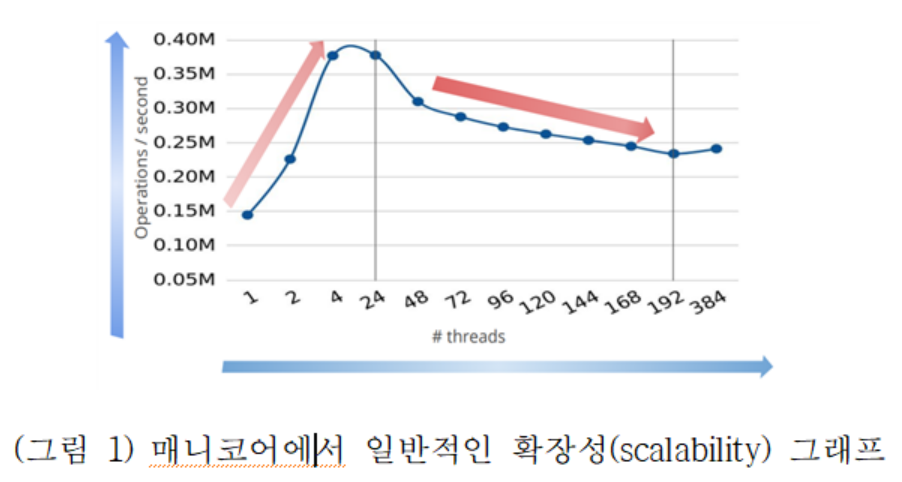
잠금 기법(Lock)은 멀티코어나 매니코어 시스템에서 고성능을 내기 위한 필수적인 요소로, 잠금 알고리즘에 따라서 (그림 1)과 같이 응용의 스케일러빌리티에 크게 영향을 준다. 이러한 잠금 알고리즘은 하드웨어의 아키텍쳐 특성을 고려하여 개발되어 왔다. 예를 들어, 가장 널리 사용되었던 티켓 스핀락(ticket spinlock)은 코어수가 많아지는 매니코어 환경에서 과도한 캐시 라인 트래픽을 발생시켜, 성능을 저하시키는 원인이 되었고 이를 해결하기 위한 MCS 잠금이 제안되었다. 또한 일반적으로 NUMA로 구성되는 매니코어 환경에서는 소켓 내의 메모리 접근이 소켓 간 메모리 접근보다 빠른 NUMA의 특성을 이용한 Cohort 잠금 기법 등이 제안되었다. 하지만 이렇게 개선된 잠금 기법들도 단일 쓰레드 성능은 고려하지 못하거나 메모리 사용량이 너무 많이지게 되는 단점을 가지고 있다. 본 연구에서는 NUMA와 같은 매니코어 환경에서 잠금 알고리즘의 성능에 영향을 미치는 요인인 서로 다른 캐시 간에 데이터 복사, 쓰레드 경합 정도, 코어의 초과 과입(over subscription), 메모리 사용량 측면에서 성능을 살펴보고, 기존 잠금 알고리즘의 문제점을 개선한 CST-Lock과 ShflLock을 제안한다.
CST-lock
연구 내용
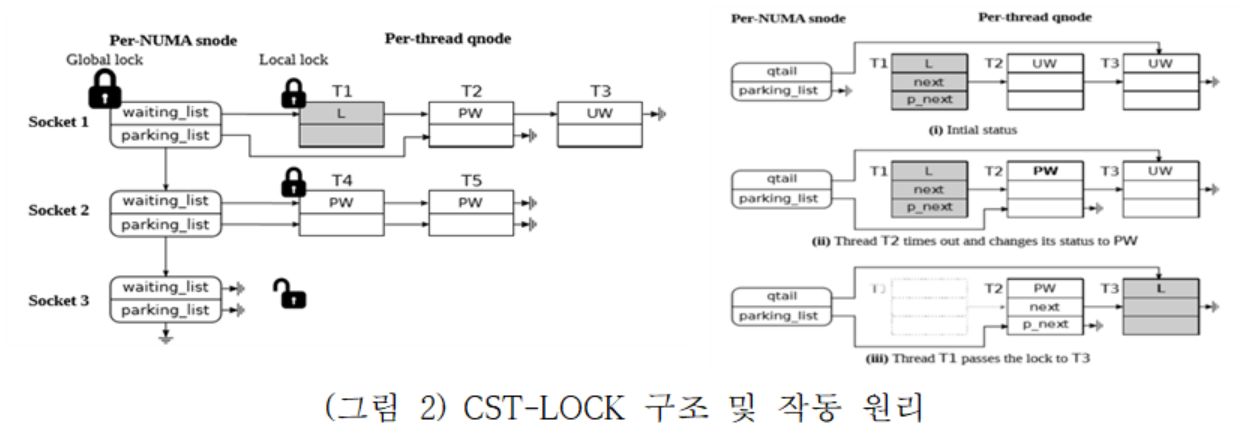
일반적으로 NUMA의 특성을 고려한 잠금 기법들은 계층적으로 구성되는데 이런 계층적 잠금 기법들은 메모리를 많이 사용하게 된다. 파일시스템과 같이 많은 락을 사용할 경우 시스템의 메모리 부족으로 인한 심각한 문제가 발생할 수 있으므로, 본 연구에서는 NUMA 단위 구조로 동적으로 할당하여 메모리 팽창문제를 해결하고자 하였다. 그리고 CPU 소켓 단위로 락 구조체를 구성하여 소켓간 캐시 테이터 복사를 줄였다. 또한 잠들어 있는 대기자를 깨우기 위한 오버헤드를 줄이기 위해서 시스템의 상태에 따라서 busy-waiting 하면서 대기(wait)할지 파킹(sleep)할지를 결정하도록 하는 spin-then-park 정책을 사용하고, 이미 잠들어 있는 대기자보다 현재 busy-waiting 하고 있는 대기자를 먼저 수행시키고 잠들어 있는 대기자를 깨워 busy-waiting하게 함으로써 스케줄러 간섭을 줄여 (그림 2)와 같이 오버헤드를 줄인다.
성능 실험
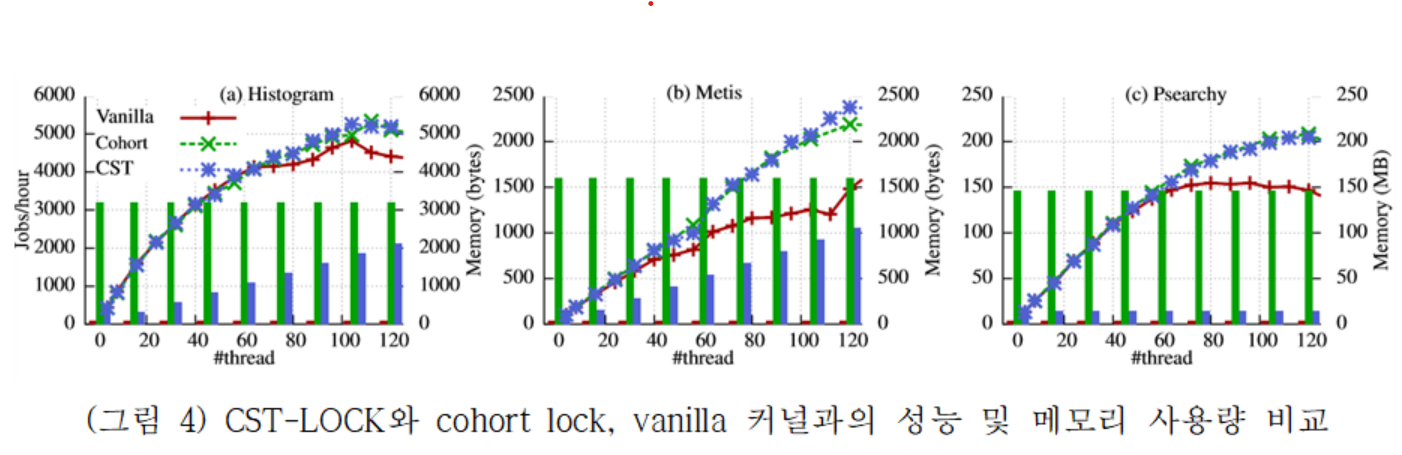
본 연구의 결과는 리눅스 4.6에 구현하였으며, 파일 시스템의 inode 관리에 사용되는 mmap_sem의 read-write lock에 적용하였다. 그리고 mosbench를 이용한 성능 분석은 (그림 4)와 같다. 120코어에서 기존 Cohort lock에 비해서 메모리 사용량은 1.5배에서 최대 9.1배까지 줄어들었으며, 성능은 10~60% 의 성능 향상을 보였다.
결과물
Shfllock
연구 내용
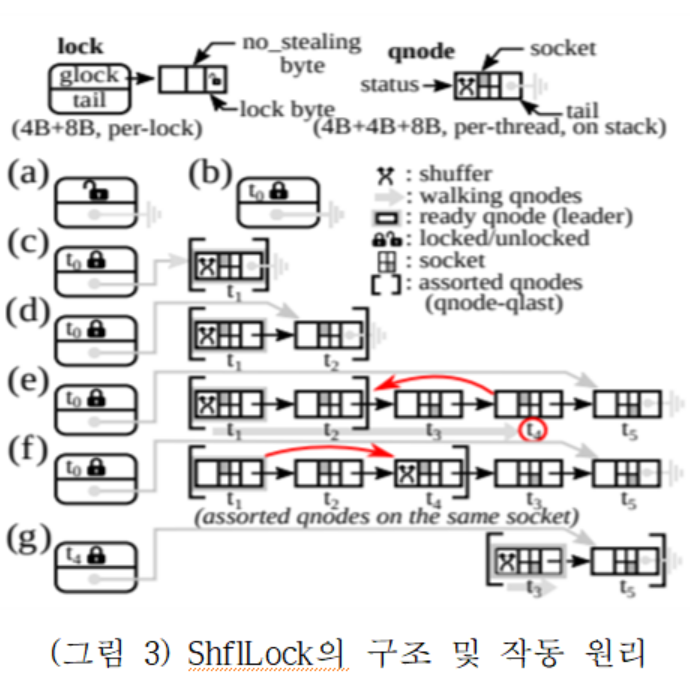
CST-Lock은 기존 계층적 잠금 기법의 문제점인 메모리 문제와 성능 문제를 어느 정도 해결하였으나, 구조적인 문제점으로 인하여 추가 메모리를 필요로 한다. 본 연구에서는 메모리 오버헤드를 가지지 않으며, 락 홀더와 대기자의 순서를 재정렬할 수 있는 Shuffling 기법에 대해 연구하였다. Shuffling이란 락을 기다리는 대기자가 단순히 busy-waiting을 하는게 아니라 다양한 정책에 따라 대기자의 순서를 바꿀 수 있도록 하는 것을 의미한다. 이러한 정책은 NUMA의 특성을 고려하거나, 락의 특성에 따라서 wakeup/parking시에 다양하게 적용할 수 있다. 예를 들어 블록킹 잠금(blocking lock)인 경우 락 홀더와 제일 가까이 있는 대기자를 깨우면 되고, rwlock 의 경우 다수의 reader가 같이 수행될 수 있도록 writer만 이동시키면 된다. 이러한 정책들은 크리티컬 패스 밖에서 수행되기 때문에 락을 획득하거나 해제할 때 추가적인 오버헤드를 발생시키지 않는다. (그림 3)는 NUMA 특성을 고려하여 Shuffling 기법을 도입한 ShflLock의 예제를 나타낸다. 먼저 잠금을 획득하려고 시도한 t0는 잠금을 획득한다(a)(b). t0가 크리티컬 섹션에서 작업을 수행 중에 새로운 쓰레드인 t1 ~ t5 가 잠금을 획득하려고 하는 경우 t1이 Shuffler가 되어서 같은 소켓에 있는 쓰레드들이 먼저 우선순위를 가지도록 리스트를 재정렬한다(c)(d)(e)(f). t0가 작업을 끝내고 잠금을 해제하면 같은 소켓에 있는 t1, t2, t4가 먼저 순서대로 실행되고, 다른 소켓에 있는 t3, t5는 나중에 실행된다(g).
성능 실험
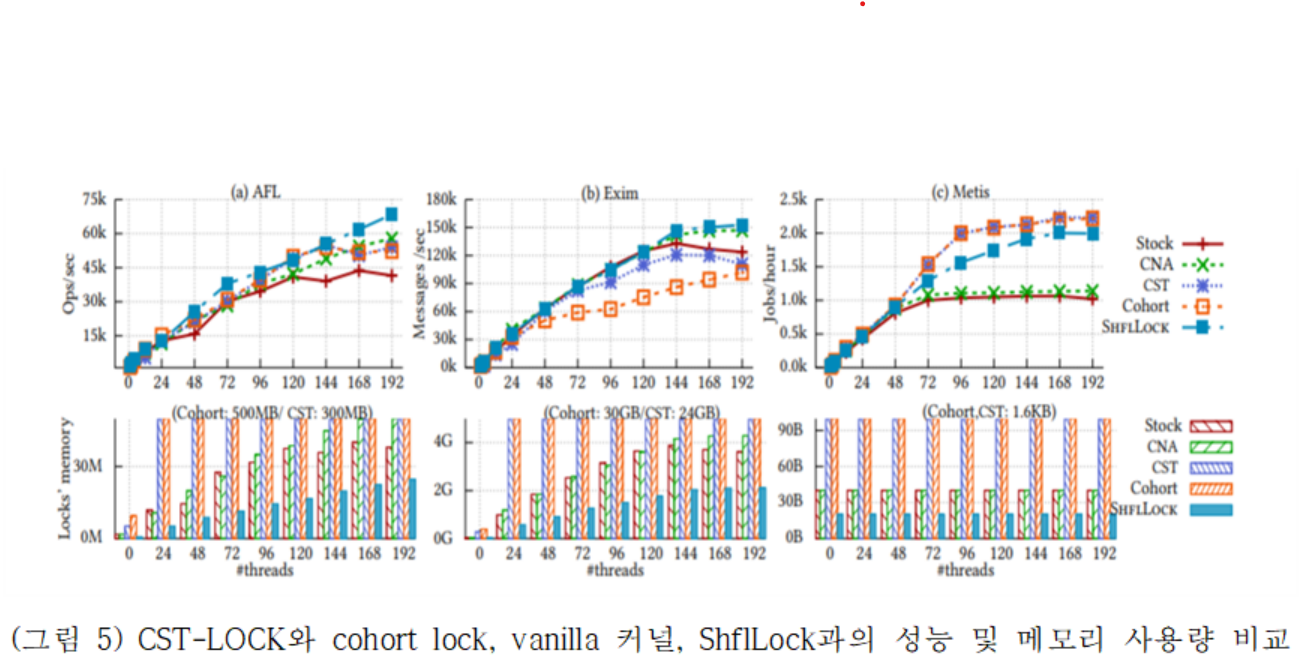
리눅스 커널 4.19에 구현하였고 mosbench를 수행한 결과는 (그림 5)와 같다. 각각의 응용들에서 192코어에서 ShflLock은 약 1.6배의 성능 향상과 35.4% 메모리 절약 효과를 보였다.
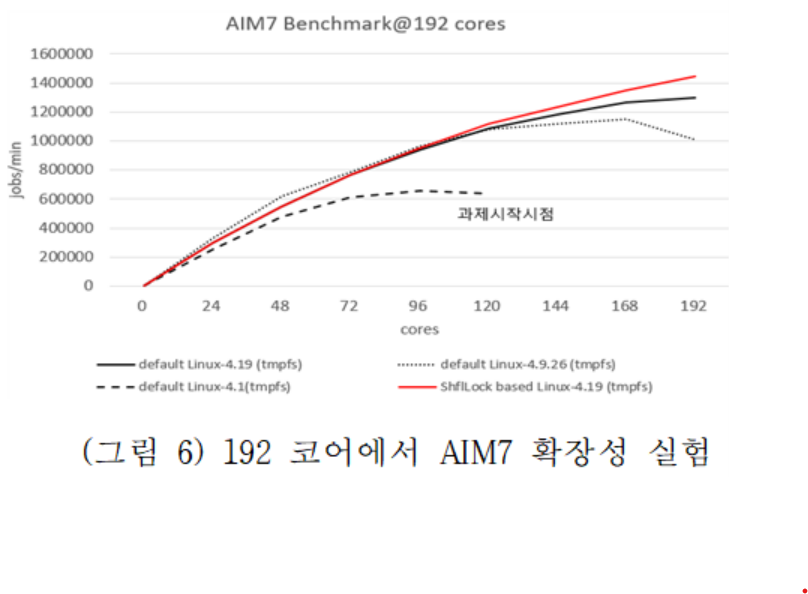
(그림 6)은 8소켓 192코어를 가진 매니코어에서 AIM7을 수행한 결과이다. ShflLock의 경우 코어수에 비례하여 리눅스보다 더욱 나은 확장성을 보임을 알 수 있다
결과물
- 논문
- 공개 소프트웨어
- Github: Shfllock
동적 잠금 기법 연구 (Dynamic Lock)
연구 배경
본 연구에서는 지금까지 사용자가 전혀 관여할 수 없었던 커널의 락 알고리즘 영역을 필요에 따라 수정한다는 새로운 패러다임을 제안한다. Dynamic Lock을 통해 응용 프로그램 개발자는 커널 락의 매개변수들을 조정하거나, 동작 알고리즘을 변경하거나, 원하는 알고리즘을 직접 추가할 수 있다. 이를 통해, 사용자는 락의 사용 패턴을 보다 정밀하게 분석할 수 있으며, 워크로드에 유리한 락 구현을 동적으로 선택해 사용할 수 있다. 또한, 사용자가 변경하거나 추가하고자 하는 락 알고리즘이 커널 영역에서 상호 배제를 깨트리거나 데드락을 유발하지 않고 안정적으로 실행될 수 있는프레임워크를 제공한다.
연구 내용
사용자가 목적에 맞게 커널 락의 기능을 변경 및 추가하면서, 동시에 커널의 안정성을 깨트리지 않도록 하기 위해 Dynamic Lock의 프레임워크는 사용자 API를 제공한다. Dynamic Lock에서 제공하는 API들은 커널 락의 핵심 알고리즘들을 변경할 수 있으면서, 사용자가 잘못된 정책을 구현하더라도 커널 내부에서 상호 배제를 깨트리거나 데드락을 유발하지 않는 것을 보장한다. 예를 들어, 사용자는 락을 획득하는 우선 순위를 결정하는 알고리즘을 직접 프로그래밍할 수 있으며, 대기 큐에 들어가기 전 스핀을 수행할 지 여부를 원하는 대로 변경할 수 있다. 또는 락을 획득하거나 놓는 과정의 전후에 원하는 알고리즘을 직접 삽입할 수 있다. 따라서, Dynamic Lock을 활용하면 각 응용 프로그램은 워크로드에 맞게 락의 성능을 최적화하거나, 락을 획득하는 순서를 재정의함으로서 공정성이나 지연시간을 최적화할 수 있다. 뿐만 아니라, 락을 분석하거나 통계를 얻기 위해 쓰이던 기존의 lockstat 툴은 전체 시스템을 동시에 추적하기 때문에 성능을 매우 악화시켰다. 반면, Dynamic Lock의 프레임워크를 사용하면 사용자가 분석을 위한 코드를 직접 추가함으로서 락과 관련된 정보들을 원하는 범위에 한정하여 프로파일링할 수 있다.
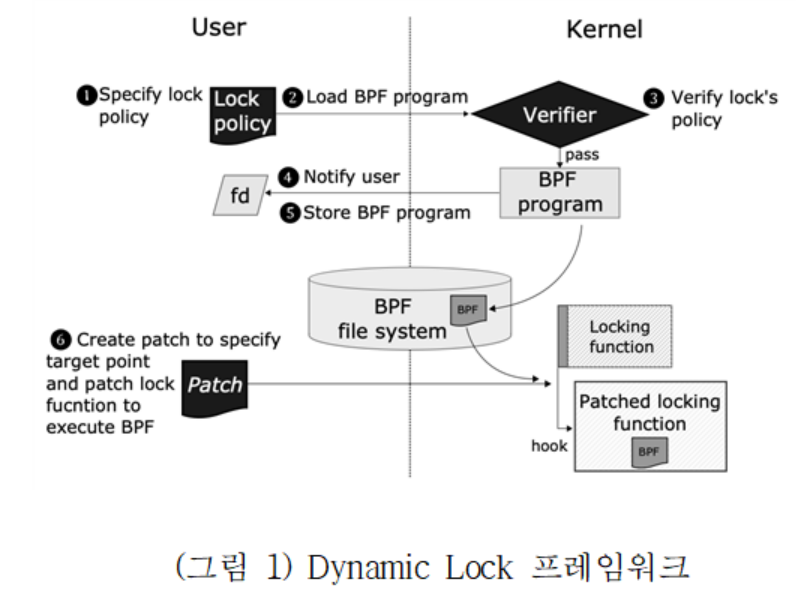
(그림 1)은 Dynamic Lock의 프레임워크 구조를 나타낸다. 먼저, 사용자는 프레임워크가 제공하는 API를 사용하여 eBPF 프로그램의 형식으로 락 알고리즘의 정책을 구현한다(❶). 사용자의 정책이 커널로 로드될 때(❷), 커널은 해당 eBPPF 프로그램의 안정성을 검증하며(❸), 안정성이 보장될 경우에만 해당 정책을 파일시스템에 저장하고 사용자에게 결과를 알린다(❹,❺). 마지막으로, 라이브패치 모듈을 사용하여, 원하는 락의 호출과정에 사용자의 정책을 추가한다.
성능 실험
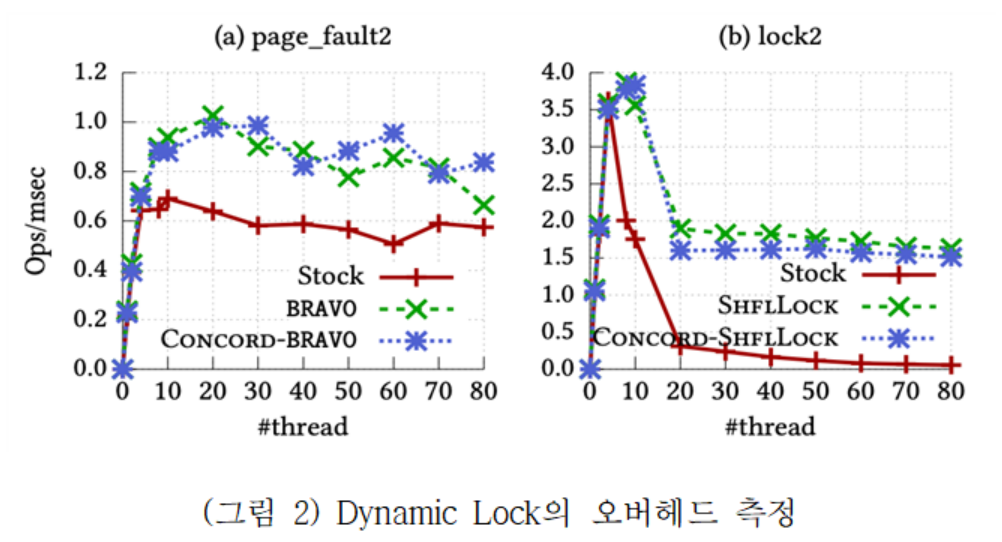
(그림 2) 는 BRAVO 락과 SHFLLOCK의 기법을 Dynamic Lock 프레임워크를 이용해 적용한 결과를 나타낸다. 커널을 수정하지 않고 두 기법을 동적으로 적용하였음에도, 커널에 정적으로 미리 구현을 추가한 것과 비교했을 때 거의 비슷한 성능을 나타내는 것을 볼 수 있다.
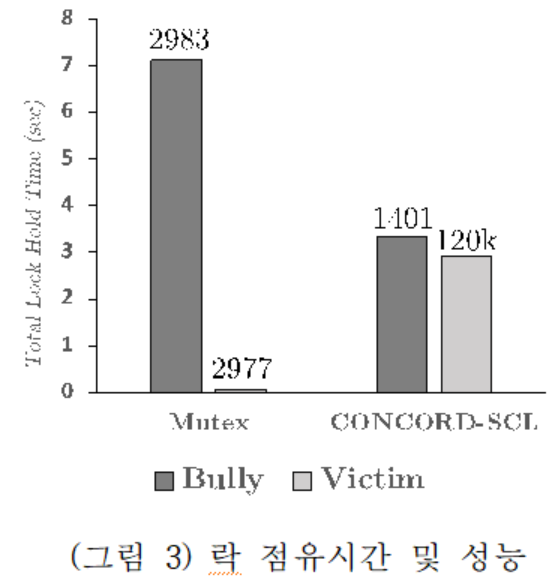
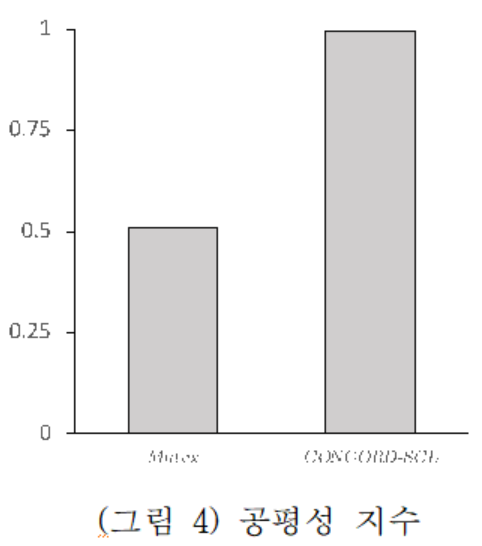
(그림 3)은 기본 리눅스 커널의 Mutex 락에 SCL 응용을 동적으로 적용하였을 때 쓰레드별 락 점유 시간과 성능을 비교한 것이다. SCL 응용을 적용한 후, 락 점유시간이 짧은 쓰레드가 기존보다 약 40배 더 자주 락을 획득하여 두 쓰레드간의 총 락 점유시간의 차이가 크게 줄어들었다. (그림 4)는 락의 공평성이 1에 매우 근접한 수준으로 최적화되었음을 보여준다.
결과물
- 논문
- 공개 소프트웨어
- Github: Dynamic Lock
- 시연 동영상
- Youtube: Linux with Dynamic Policy Changes