1K+ 코어 테스트베드 구축
매니코어 OS 기초연구에서 중요한 이슈 중 하나는 매니코어 시스템(수백~수천코어 시스템)이 없는 상황에서 운영체제의 성능 및 확장성을 실험할 수 있는 매니코어 테스트베드를 어떻게 구축할 수 있는지 이다. 그 동안의 선행연구에서는 240코어 이내의 시스템을 사용하였다.(MIT의 corey 프로젝트: 48코어, sv6 : 80코어, 240코어의 HP CS900,…) 그러나, 비용 측면에서 240코어를 지원하는 HP CS900 시스템의 가격은 1M$이상이며, 80코어 Xeon 시스템도 40K$정도로 고가의 장비들이다. 이러한 시스템으로 수백~수천코어의 매니코어 시스템을 구축하는데 많은 비용이 필요하다. 따라서 현실적으로 어떻게 매니코어 테스트베드를 구축할 것인지 연구가 필요하다. 한편, 대안으로 애뮬레이터를 생각할 수 있지만, 속도 문제와 non-determinism 문제가 있다.
본 연구에서는 현재 존재하는 매니코어 시스템이 없기 때문에 운영체제의 성능 및 확장성 실험을 위해 연구 초기에는 제온 파이를 이용하여 매니코어 테스트베드를 구성하여 실험하였으며, 후기에는 다수의 제온 시스템을 Infiniband 상에서 NFS over RDMA로 구성하여 매니코어 테스트베드로 활용하여 실험하였다..
Intel Xeon Phi 기반 테스트베드
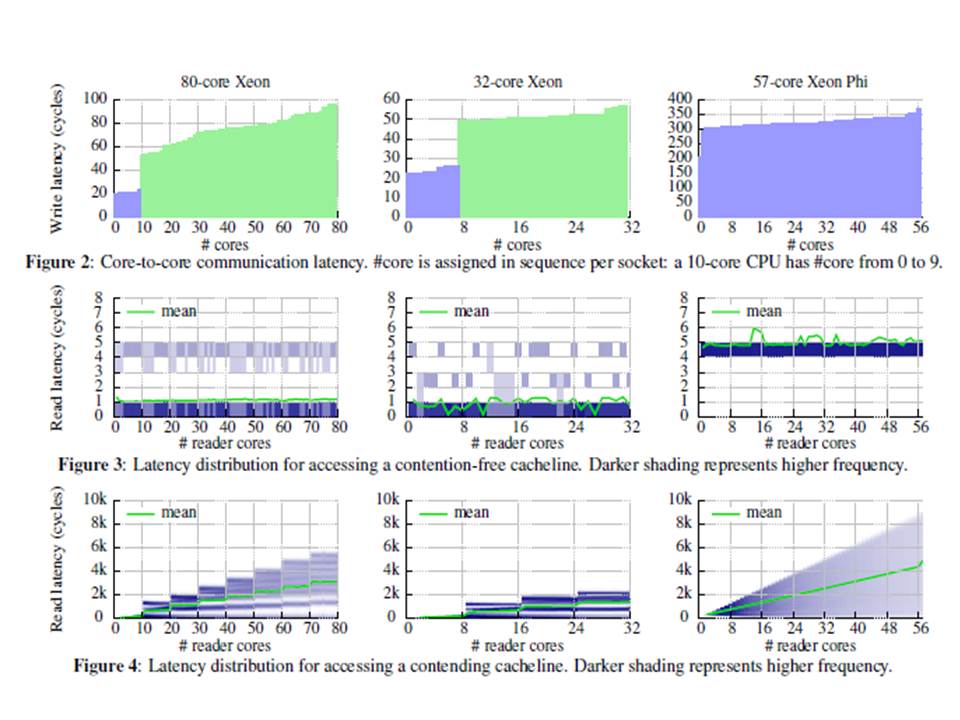
본 연구 초기에는 1K+ 코어 테스트베드를 구축하기 위한 현실적인 대안으로 Xeon Phi에 주목하고, Xeon 프로세서(80코어와 32코어)와 Xeon Phi 보조 프로세서(coprocessor)(57코어)의 성능 실험을 추진하였다. 코어간 통신 지연시간, 캐시 접근시간, 메모리 접근시간, splinlock 스케일러빌러티에 대한 성능 실험을 통하여 Xeon Phi 보조 프로세서가 Xeon 프로세서(SMP UMA 머신)와 유사하게 동작한다는 것을 알수 있었으며, Xeon phi 보조 프로세서를 사용하여, SMP, big.LITTLE, ccNUMA, non-ccNUMA, Cluster 등 다양한 테스트베드를 구축할 수 있음을 찾았다.
Intel KNC (KNight Corner) 기반 테스트베드
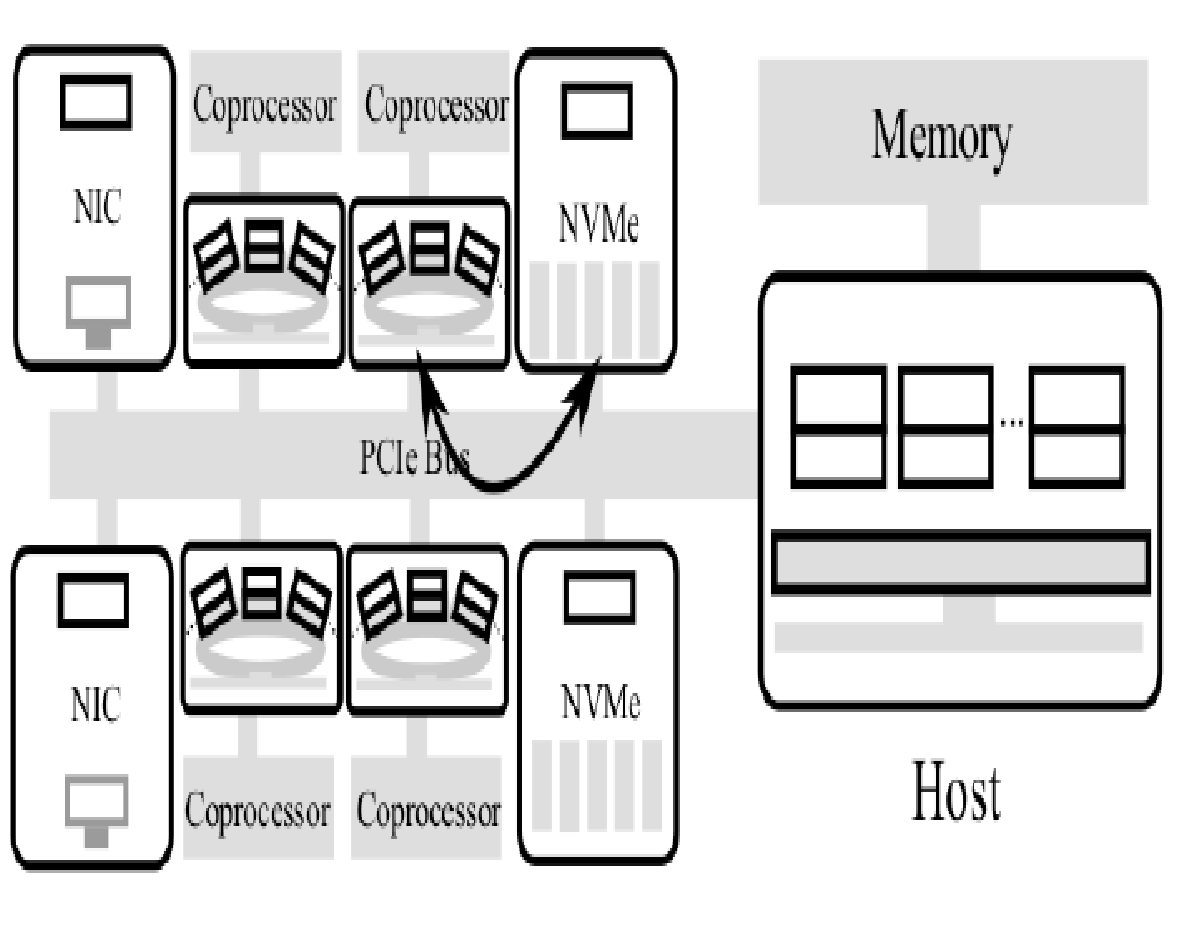
Xeon Phi 보조 프로세서인 KNC(KNight Corner)를 사용하여 1K+ 매니코어 테스트베드 구축하였다. 또한 NVMe 장치를 이용하여 대규모 빠른 저장장치 환경도 마련하였다. 다음 그림은 1K+ 매니코어 테스트베드이며, Rack Scale Architecture의 사례라고도 할 수 있다.
Intel KNL (KNight Landing) 기반 테스트베드
더 많은 노드의 확장을 위해 다음 세대 Xeon Phi 보조 프로세서인 KNL(KNight Landing)를 사용하여 1K+ 매니코어 테스트베드를 구축하였다.

Intel x86 기반 테스트베드
Intel Xeon 기반 192 코어 테스트베드
Intel x86 시스템(192코어)에 멀티커널이 동작할 수 있도록 테스트베드를 구축하였다. 멀티커널에서 커널의 동작을 위한 멀티커널 매니저, 응용이 동작하는 유니커널, 리눅스API와의 호환성을 위한 풀커널 로 구성되어 동작한다. 실험환경은 인텔 x86 Xeon E7-8890 8소켓 (192 코어)을 사용하였으며 디스크는 SSD (ext4)를 사용하였다. 192 코어 시스템에서 본 연구에서 개발한 멀티커널 기반 분할형 운영체제인 아질리아의 성능 및 확장성 실험을 위해 AIM7 벤치마크를 이용하여 리눅스와의 성능을 비교하였다. 실험 결과 리눅스는 일정 코어에서 성능이 정체됨을 보였고 아질리아는 성능 확장성 지원함을 확인하였다. AIM7 성능실험 결과 아질리아는 리눅스 대비 69% 성능 개선이 있음을 보인다.

(그림) Lenovo System x3950 X6 (x86 Xeon E7-8890 8소켓 (192 코어))
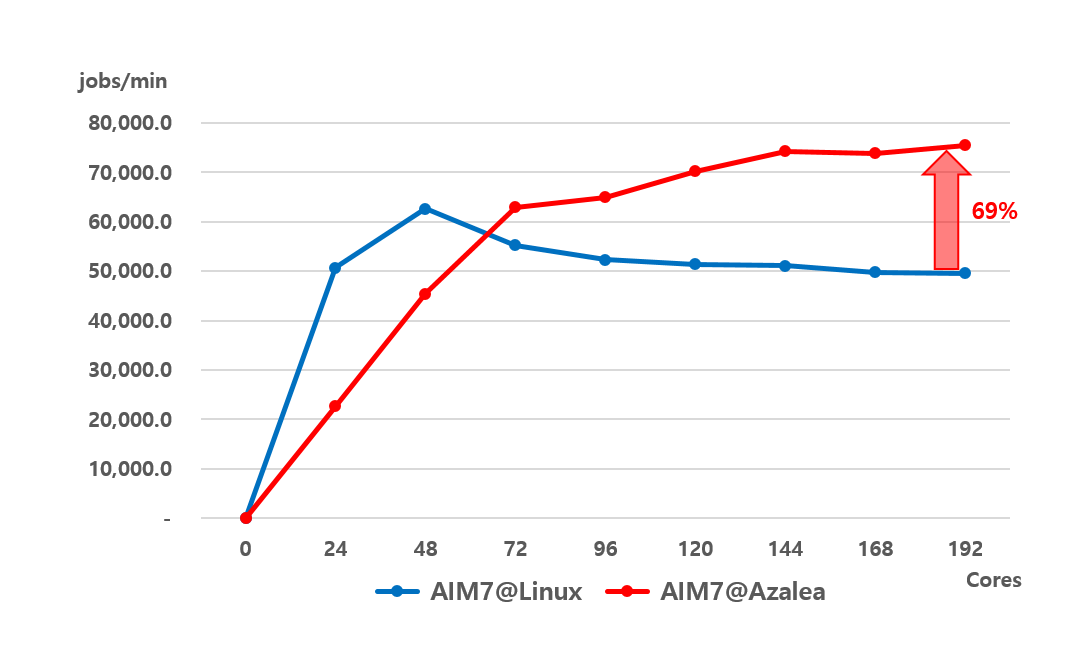
(그림) AIM7 벤치마크 성능실험 (@x86 192 코어)
Intel Xeon 기반 1K+ 테스트베드
현재 존재하는 1K+ 매니코어 시스템이 없기 때문에 다수의 제온 시스템을 Infiniband 상에서 NFS over RDMA로 구성하여 1K+ 테스트베드 시스템을 구성하였다. 1K+ 테스트베드 시스템(총 920 코어)을 구성하기 위하여 응용 프로그램 수행을 위해 인텔 x86 Xeon E7-8890 8소켓 (192 코어) 2대, 인텔 x86 Xeon E7-8870 8소켓 (120 코어) 4대, 그리고 풀커널을 수행하기 위해 인텔 x86 8176 2소켓 (56코어) 1대를 사용하였으며 풀커널의 디스크(SSD, ext4)에 대한 입출력은 Infiniband 상에서 NFS over RDMA를 사용하였다.
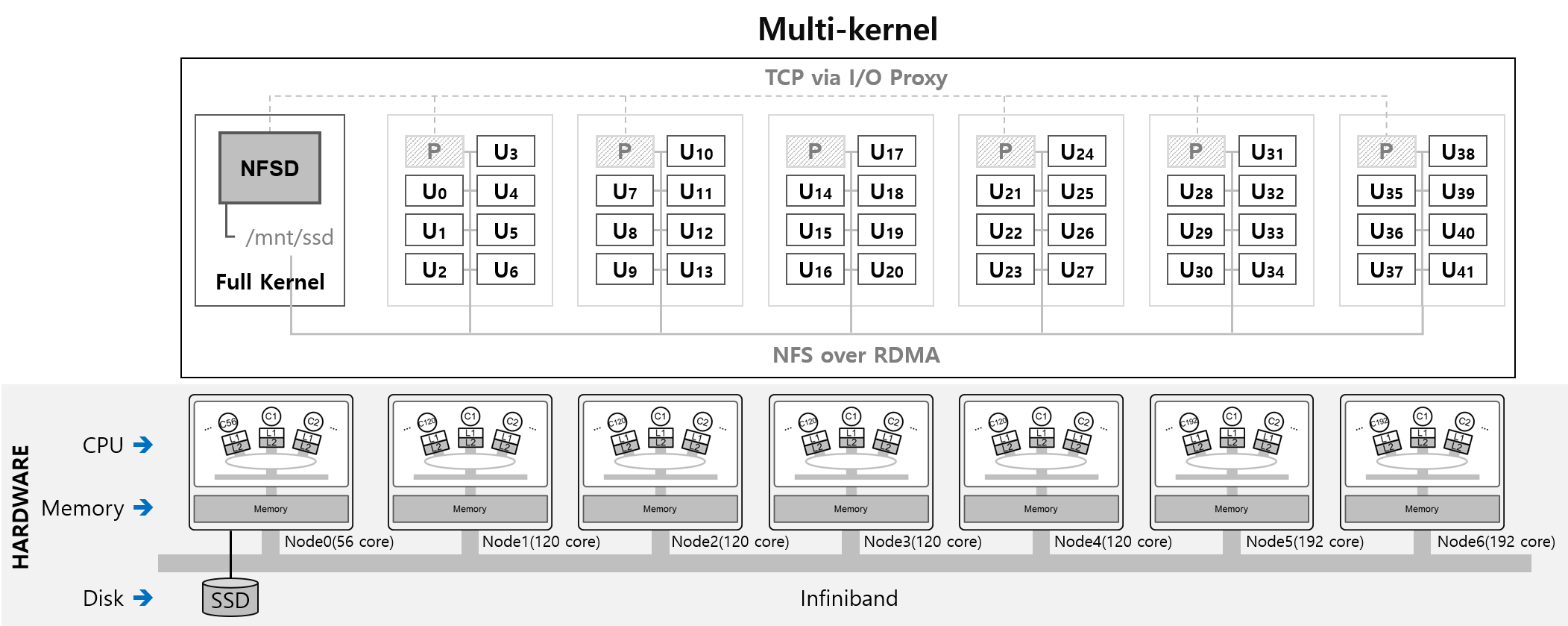
(그림) 1K+ 테스트베드(920코어: 7 노드), 풀커널: 노드 0(x86 56코어), 유니커널: 노드 1~4(x86 120코어) & 노드 5~6(x86 192코어)
구축된 1K+ 테스트베드 시스템에서 멀티커널 기반 분할형 운영체제인 아질리아와 리눅스의 성능 및 확장성을 비교하는 실험을 수행하였다. 아질리아와 리눅스의 성능 및 확장성을 측정하기 위한 벤치마크 프로그램으로 AIM7 벤치마크를 이용하으며, AIM7 벤치마크는 단일 시스템에서 성능을 측정하는 프로그램이기 때문에 다수의 시스템으로 구성된 1K+ 테스트 베드 시스템에서 수행될 수 있도록 수정되었다. 수정된 AIM7 벤치마크는 AIM7 벤치마크의 구조를 벤치마크 수행단위인 태스크(task)를 관리하는 부분과 실제 태스크를 수행하는 부분으로 나누어 구성하였다. 태스크를 관리하는 부분은 풀커널에서 수행되며 각 유니커널에 태스크들을 할당하고 태스크 시작과 종료에 대한 동기화를 담당한다. 태스크를 수행하는 부분은 유니커널에서 수행되며 태스크의 작업(job)이라고 하는 하위 테스트 세트를 무작위 순서로 실행한다. 1K+ 테스트 베드 시스템에서 실험 결과, 리눅스는 일정 코어에서 성능이 정체됨을 보였고 아질리아는 코어가 증가함에 따라 성능 확장성을 나타내었다. 아질리아는 리눅스 대비 AIM7 성능실험 결과 350% 성능 개선을 보였다. 그리고, 풀커널에 대한 디스크 입출력 방식 개선(NFS(인텔 Xeon E5-2697 (36 코어)) 1대 및 SSD 2개 추가)을 통해 리눅스 대비 625% 성능 개선이 가능함을 보였다.
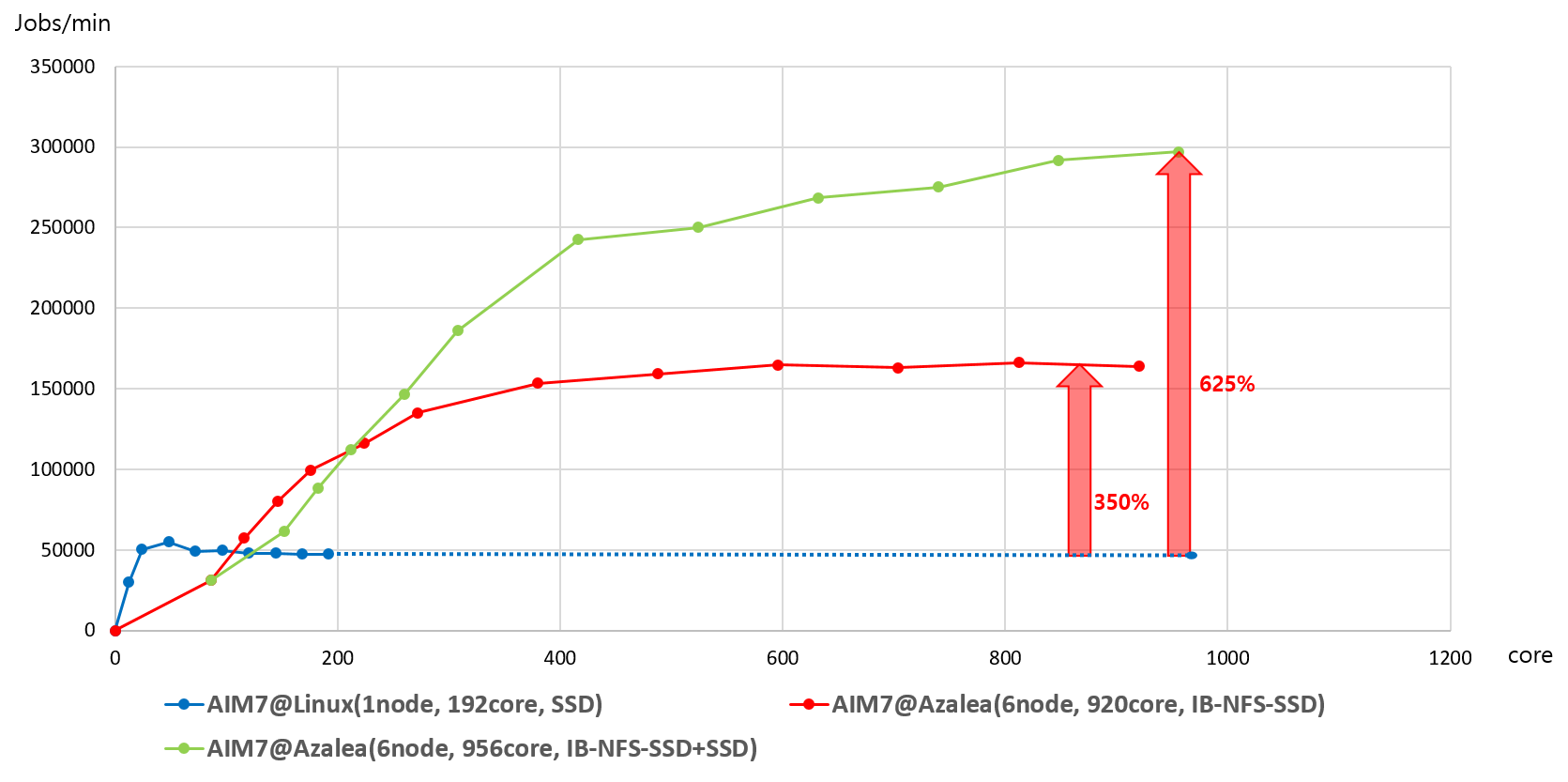
(그림) AIM7 벤치마크 성능실험 (@x86 920 코어, 956 코어)