메모리 접근 최소화로 딥러닝 최적화 연구
연구 배경
최근의 하드웨어 성능과 딥러닝 알고리즘의 발전으로 인해 DNN 은 다양한 분야에서 활발하게 사용되고 있으며, 그 중 CNN 은 텍스트, 이미지 및 비디오 등의 데이터에서 패턴을 추출하여 컨텐츠를 인식하는 분야에 광범위하게 적용되고 있다. CNN은 매우 많은 병렬적인 연산을 요구하기 때문에, 이를 에너지 효율적으로 수행하면서 빠른 추론 속도를 보장하기 위한 스크래치패드 메모리 (SPM) 기반 매니코어 아키텍처들이 활발히 연구되고 있다.
CNN 은 7개의 중첩된 반복문으로 구성되어 있다. 하지만 이러한 아키텍처에서 CNN 을 수행하기 위해서는 하위 메모리에서 상위 메모리로 데이터를 전송하는 스케줄과 (tiling) 각 코어에 어떠한 연산을 할당할 것인지를 (spatial ordering) 결정해야 하며, 반복문을 수행하는 순서를 바꿔 데이터의 재사용을 최대화하는 최적화 (loop reordering) 를 적용할 수도 있다. 이러한 결정에 따라 하나의 CNN 을 수행하는 데에는 수십억개의 수행 방법 (execution methods) 이 존재하며, 효율적인 수행방법과 비효율적인 수행방법 사이에는 수십배 이상의 성능 및 에너지 효율 차이가 존재한다.
효율적인 수행 방법을 찾기 위하여 많은 연구가 진행되었다. 대표적인 방법으로는 필터의 재사용을 극대화하는 Weight Stationary, partial sum 의 재사용을 최대화하기 위한 Output stationary, 그리고 각 코어가 하나의 row 를 처리함으로써 다양한 재사용을 발생시키는 row stationary 등이 있다. 그러나 이러한 기법들은 모든 가능한 수행 방법을 비교하여 최적의 방법을 찾는 것이 아니라 휴리스틱에 기반한 알고리즘이라는 한계점을 가지고 있다.
연구 내용
본 연구는 주어진 perfectly nested loop (중첩 루프의 맨 안쪽에만 연산이 있는 루프를 말하며 대표적으로 CNN 이 존재) 을 SPM 기반 매니코어 가속기 환경에서 수행할 때, 최적의 수행 방법을 찾는 것을 목표로 한다. 본 연구의 결과로 개발한 dMazeRunner 프레임워크는 다음과 같은 흐름을 통해 응용 실행을 최적화한다.
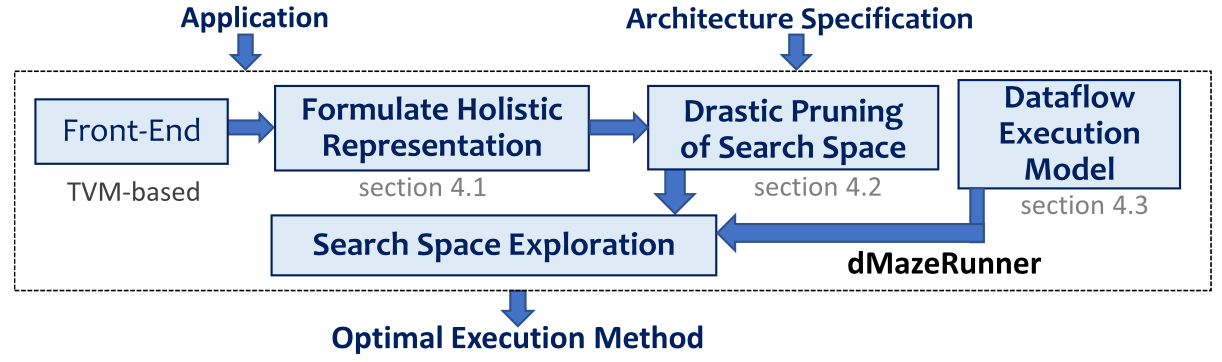
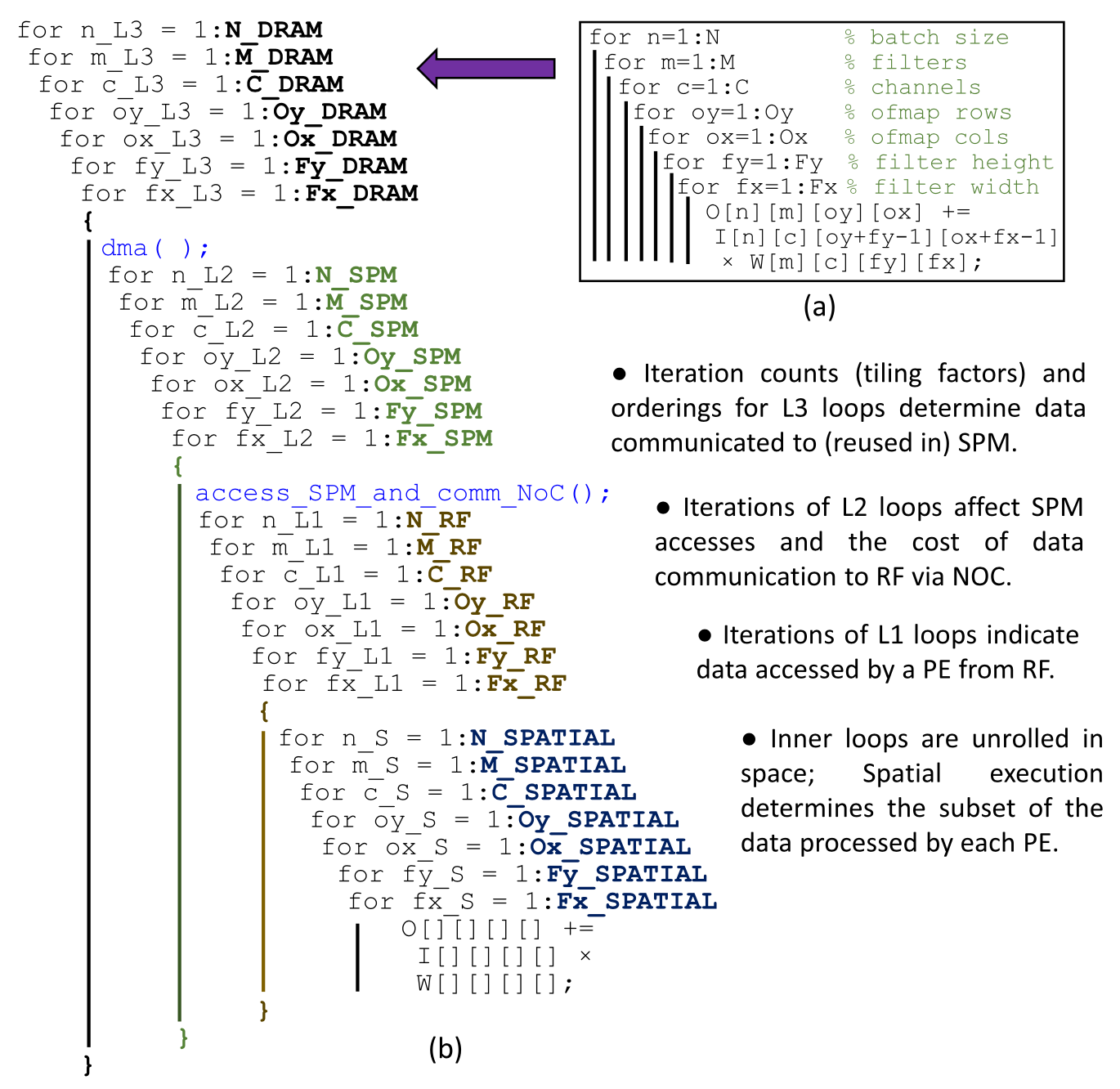
CNN 의 다양한 수행 방법을 표현할 수 있는 표현 개발
CNN 은 7개의 중첩된 반복문으로 표현될 수 있다 (그림 a). 그러나 이를 SPM 기반 매니코어 환경에서 수행할 때에는 데이터 이동의 단위나 루프 수행 순서에 따라 매우 많은 방법으로 수행할 수 있으며, 이를 수행 방법 (Execution Method) 라고 한다. 구체적으로 다음과 같은 세 가지 요소에 의해 CNN 의 수행 방법이 결정되며, 그림은 최종적인 representation 을 설명하고 있다.
- Tiling: 메모리 계층 간 데이터를 전송할 때 어떤 크기로 데이터를 분할하여 전송할 것인지를 나타낸다. DRAM -> SPM, SPM -> RF (Register File) 의 순서로 데이터를 분할하여 전송해야 하며 이에 따라 다양한 스케줄이 존재하게 된다. 그림에서는
N_DRAM,N_SPM,N_RF로 루프를 분할한 것을 볼 수 있으며 각 단계가 지날 때마다dma(),access_SPM_and_comm_NoC()함수를 통해 데이터를 상위 메모리로 전달하는 것을 볼 수 있다. - Spatial Ordering: SPM 에 적재되어 있는 데이터를 어떤 방식으로 여러 코어에 할당하는지를 의미한다. 그림에서는
N_SPATIAL,...루프로 표현되어 있으며 각 코어에 분배된 코드는 동시에 병렬적으로 수행되게 된다. - Loop Reordering: CNN 과 같은 응용은 루프의 수행 순서를 임의로 바꾸어도 동일한 계산 결과를 얻을 수 있는데, 루프의 수행 순서는 수행 시간과 에너지에는 큰 영향을 미친다. 효율적으로 루프의 순서를 설정할 경우 데이터를 여러 번 재사용하여 많은 에너지를 절약할 수 있다. 그림에서는 각 단계의 루프 순서를 임의로 변경할 수 있다.
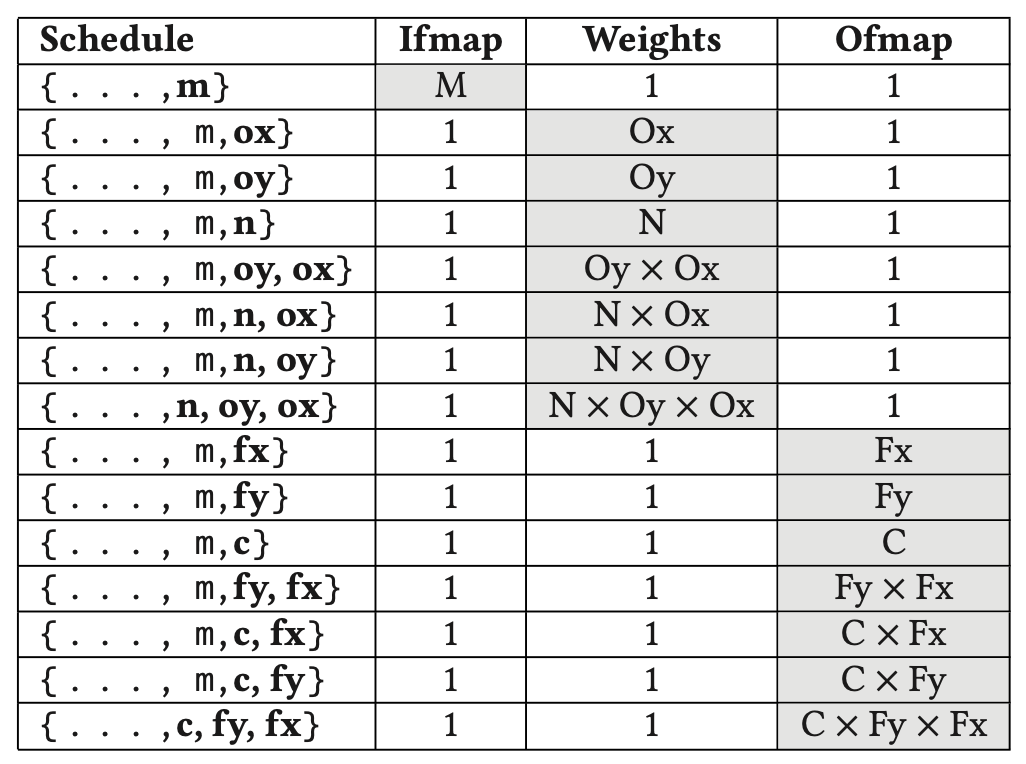
Pruning 을 통한 탐색 공간 압축
위와 같은 방법으로 하나의 CNN 응용의 수행 방법을 찾게 되면 탐색 공간은 수십억 개 이상의 넓은 공간이 된다. 따라서 최적의 수행 방법을 찾기 위해서는 이러한 탐색 공간을 급격하게 줄일 수 있는 방법이 필요한데, 본 연구에서는 휴리스틱을 포함한 다양한 pruning 기법을 제안하여 탐색 공간을 압축하였다.
아래의 표는 Loop Reordering 을 통하여 만들 수 있는 5040 개의 수행 방법이 가장 안쪽에 있는 루프 변수 (innermost loop variable) 에 따라 15개의 class 중 하나에 포함됨을 나타내고 있다. 매 iteration 이 끝날 때마다 어떤 데이터는 재사용이 가능하고 어떤 데이터는 새로 하위 메모리에서 가져와야 하는데, 본 연구에서는 이 데이터 재사용 패턴이 innermost loop variable 에 의존하며 그 재사용 횟수는 얼마나 되는지를 밝혔다.
이 외에도 Resource Utilization 에 따른 pruning, 지나치게 많은 메모리, DMA access 를 요구하는 수행 방법 제외, 자주 사용되는 데이터를 캐싱하고 병렬화를 구현하는 등 소프트웨어 구현 최적화를 통하여 탐색에 걸리는 시간을 감소시켰다.
Execution Model 을 통한 성능 예측
Pruning 기법을 통해 탐색 공간을 압축한 후, 남은 수행 방법들을 평가하기 위하여 Execution Model 을 개발하였다. 이 모델은 수행 방법을 결정하는 세 가지 요소 (tiling, spatial ordering and loop reordering) 을 입력으로 받아 에너지와 수행 시간을 예측하는 모델로써 빠른 속도로 수행될 뿐만 아니라 다양한 corner-case 를 고려한 정확한 수치를 제공한다.
성능 평가
기존 유명한 dataflow 알고리즘과 EDP 를 비교하는 방식으로 성능을 평가하였다. 응용으로는 ImageNet 분류를 위해 학습된 ResNet 이 사용되었다. 아래 그래프는 Output stationary (Oy / Ox), Weight Stationary (Fy / Fx), Row Stationary (Oy / Fy) 및 TPU style (M / C) 과의 EDP 및 수행시간 차이를 나타내고 있다.
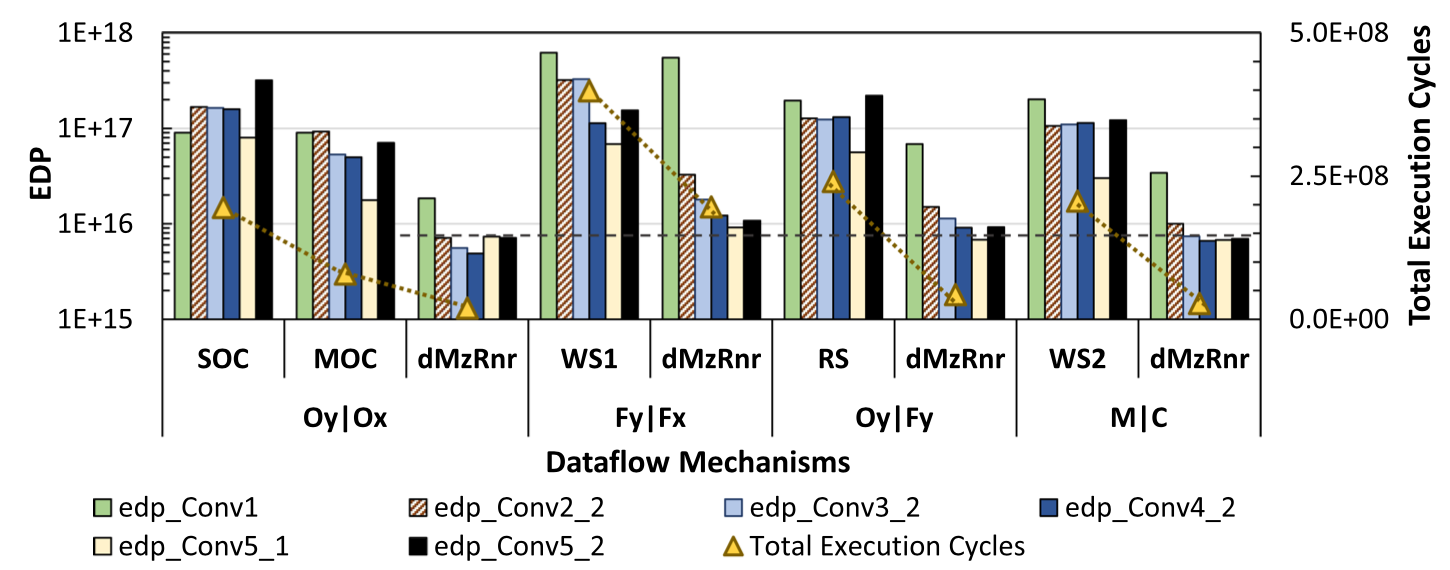
본 기법은 휴리스틱에 의존하지 않고 대부분의 탐색 공간을 확인함으로써 평균 9.16 배의 EDP 향상 및 5.83 배의 수행시간 향상을 달성하였다.
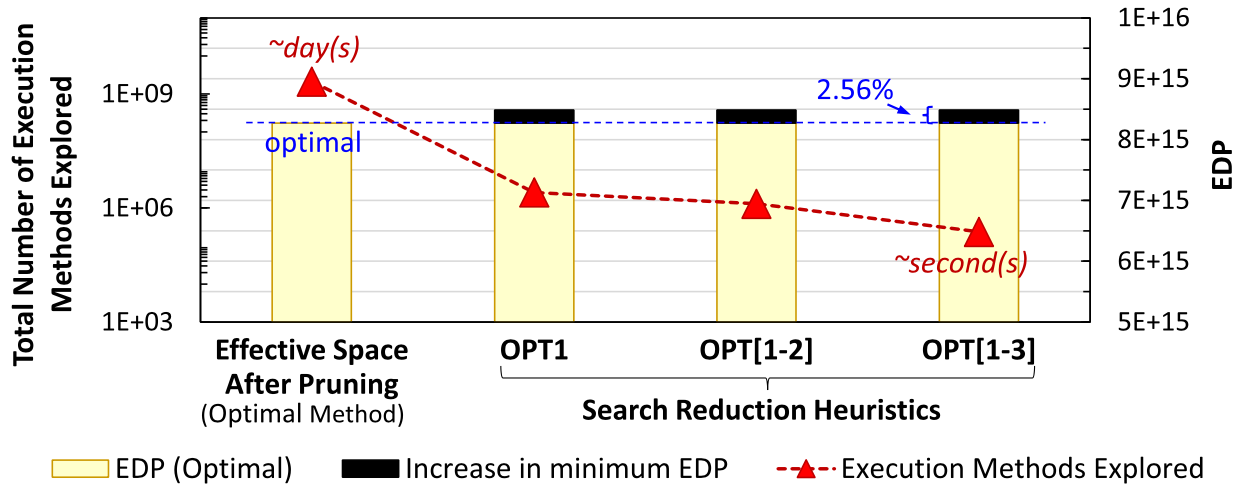
아래 그래프의 경우 본 연구의 pruning 성능을 나타낸 것이다. 그래프에서 확인할 수 있듯이, 아무런 pruning 을 적용하지 않았을 때에는 수 일의 시간이 걸리는 탐색을 2.56% 의 성능 loss 만으로 초 단위로 감소시킨 것을 볼 수 있다 (9020 배 감소).
향후 계획
향후 계획으로 본 연구에 사용된 Execution Model 을 시뮬레이터로 발전시켜 더욱 다양한 최적화 기법을 적용하고 정밀한 성능 측정을 하려고 한다. 정확한 timing 을 평가할 수 있는 시뮬레이터를 기반으로 최적에 수행 방법을 찾는 것 뿐만 아니라 이 수행 방법에 적용할 수 있는 다양한 최적화 기법을 개발하려고 한다.
연구 결과물
- 논문
- 공개 소프트웨어
- Github: dMazerunner
- Github: DiRAC
- 시연 동영상