응용과 커널 수행 분리를 위한 코어 파티셔닝 기법(Syscalib) 연구
연구 배경
기존까지 진행되어 왔던 코어 파티셔닝 연구는 많은 한계와 개선해야 할 점을 보이고 있었다. 그중 네트워크 I/O에 대한 코어 파티셔닝을 지원하지 않는다는 것과, 시스템 호출과 입출력 인터럽트를 동작시킬 코어의 개수가 코어 파티셔닝 모듈을 적용할 때 주어진 값으로 결정되고 그 이후 필요에 의하여 변경할 수 없다는 것이 가장 큰 개선해야 할 점이다. 또한 응용이 필요로 하는 자원과 워크로드마다의 다른 패턴들을 하나의 코어 파티셔닝 정책으로 지원하고 있었다. 따라서 본 연구에서는 네트워크 I/O의 시스템 호출과 인터럽트에 대한 코어 파티셔닝도 지원하고, 시스템 호출과 인터럽트를 동작시키는 코어의 개수를 시스템의 상황에 맞추어 코어 파티셔닝 모듈이 알고리즘에 의하여 판단하고 직접 변경할 수 있도록 한다. 또한 3가지의 코어 파티셔닝 정책을 제안하고 비교한다.
연구 내용
동적 코어 파티셔닝
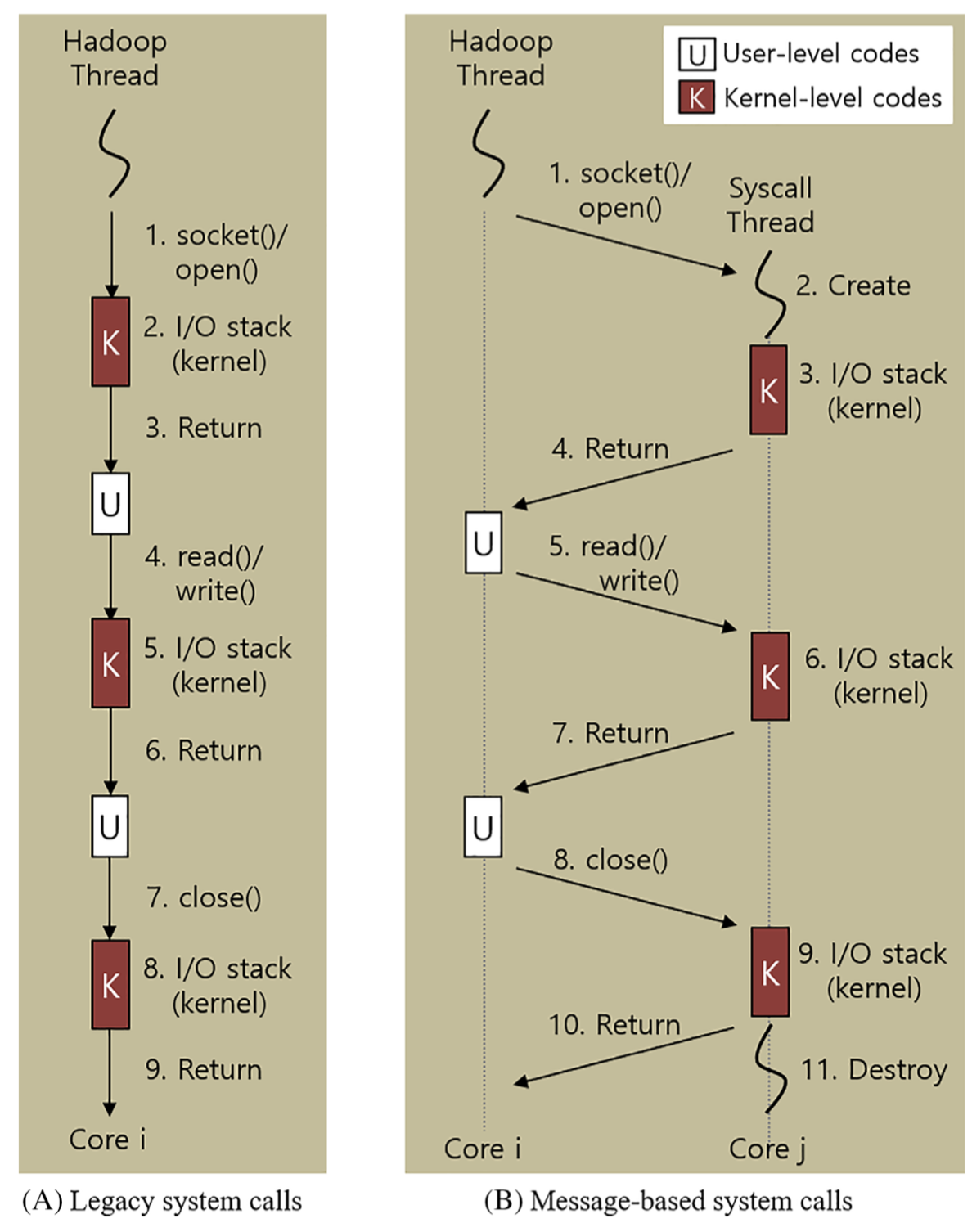
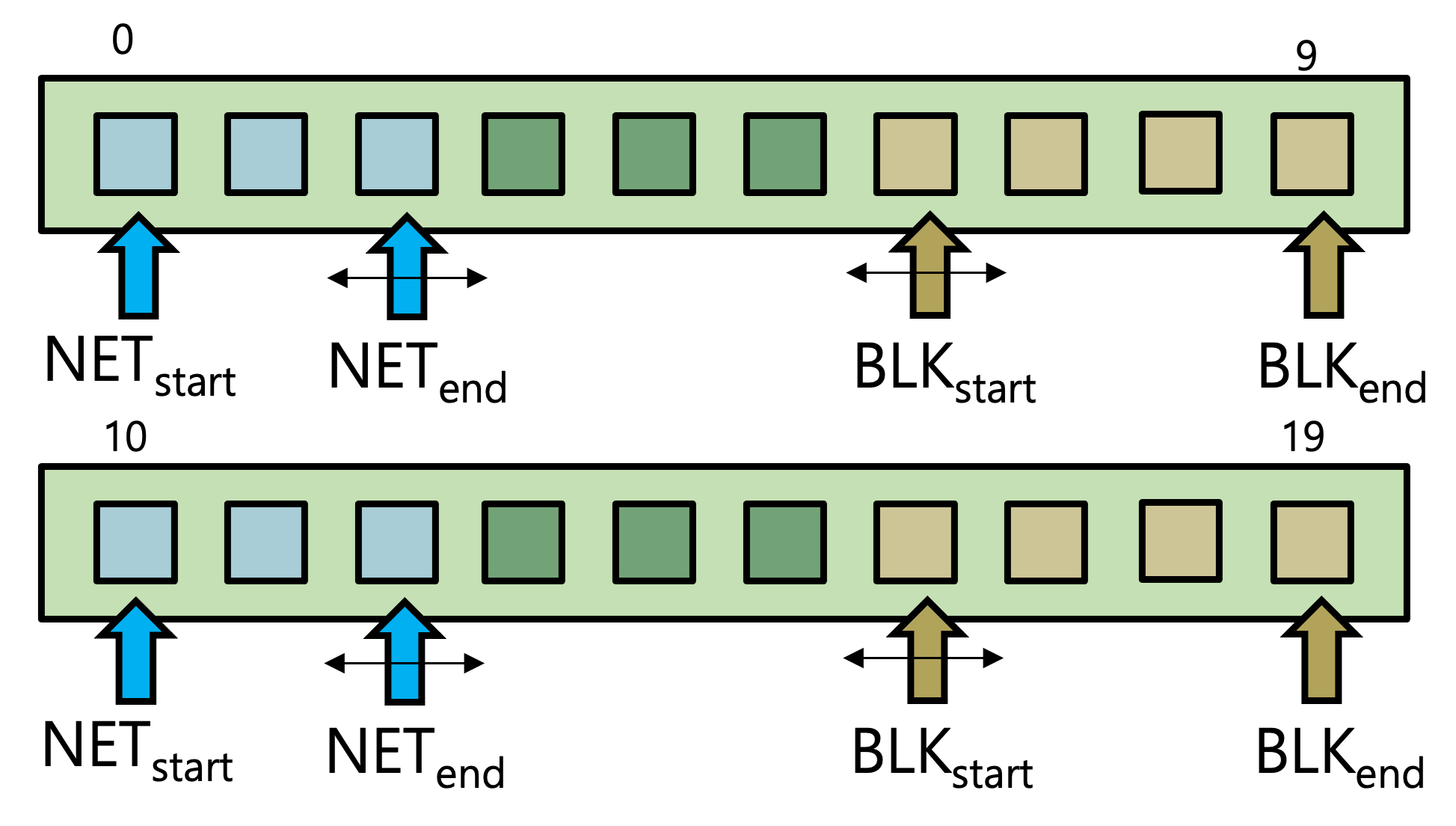
기존의 코어 파티셔닝과 같이 공유 메모리를 이용하여 Syscall 쓰레드가 시스템 호출 요청을 받고, 처리하고, 결과값을 다시 공유 메모리에 저장하는 형태로 되어있다. 파일 I/O의 경우 open()등의 파일 식별자를 반환하고 해당 식별자에 계속 입출력을 시도하는 시스템 호출에 Syscall 쓰레드를 생성하고 close()와 같이 식별자를 닫을 때 소멸시키도록 되어있다. 네트워크 I/O는 socket() 함수의 호출시 Syscall 쓰레드를 만들고 shutdown(), close()등의 함수에 소멸시키도록 되어있다.
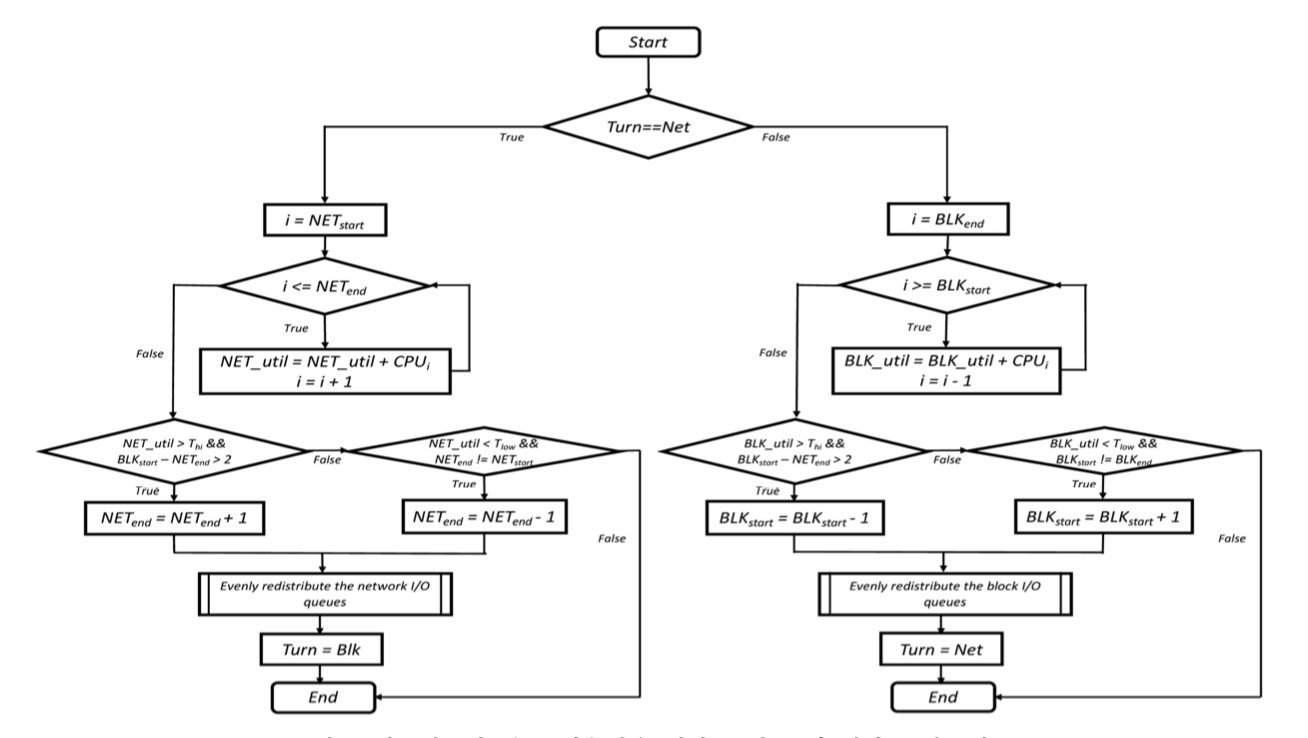
파일과 네트워크, 시스템 호출과 인터럽트에 사용되는 코어의 개수를 결정하는 알고리즘은 아래 그림과 같다. 각 항목은 CPU사용량의 임계값을 가지고 코어 수를 늘리거나 줄이는 것을 반복하도록 되어있고, 이는 주기적으로 모니터링하고 사용량을 계산하는 커널 모듈에 의하여 동작된다.
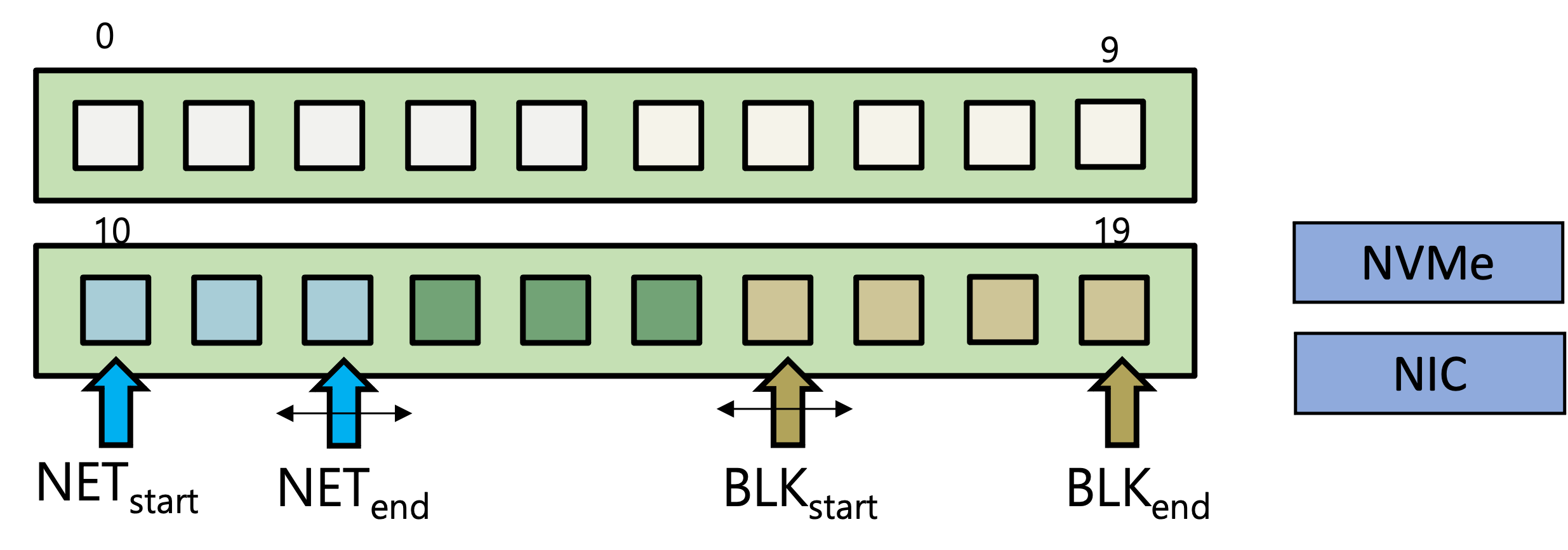
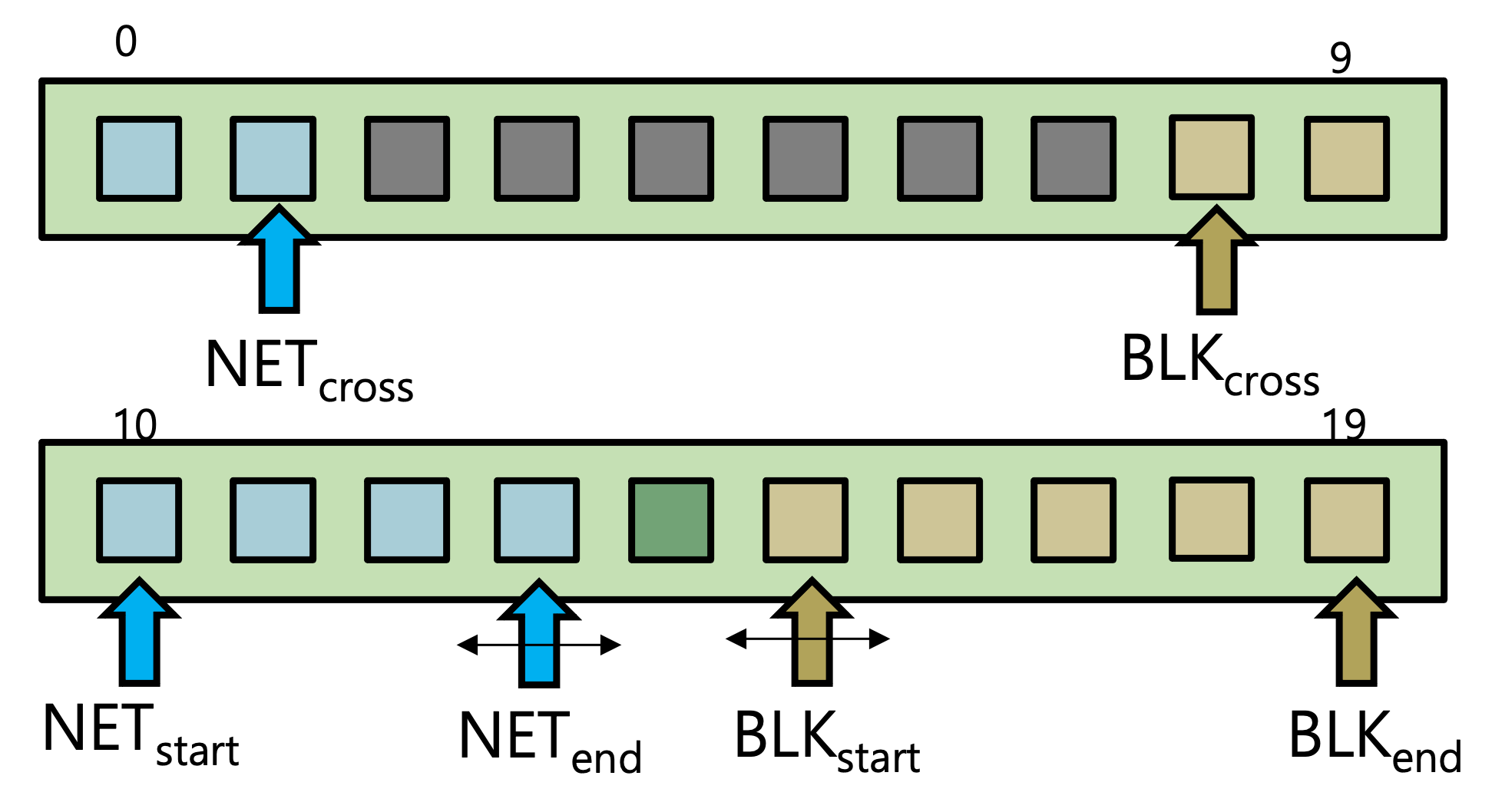
코어 파티셔닝의 3가지 정책은 각각 Single-socket, Per-socket, Cross-socket이라는 이름을 가지고 있고, 이들은 코어 파티셔닝이 CPU소켓을 사용하는 방식에 차이가 있다. Single-socket 정책은 시스템 호출 문맥을 하나의 NUMA 노드에 속한 코어에만 친화도를 갖도록 한다. 이를 통해서 I/O 스택의 지역성을 높이는 것을 목적으로 한다. 대상이 되는 NUMA 노드는 I/O 장치와 가까운 (1-hop) 거리를 갖도록 결정한다. Per-socket 정책은 시스템 호출을 요청한 쓰레드가 수행되고 있는 NUMA 노드 내에서 시스템 호출 문맥이 코어 친화도를 갖도록 한다. 이 정책은 I/O 스택의 지역성을 분산시키지만, 사용자 수준 I/O 버퍼에 대한 지역성을 높일 수 있다. Cross-socket 정책은 Single-socket 정책과 유사하지만, I/O 장치와 가까운 NUMA 노드의 코어로만 I/O 대역폭을 충분히 활용하기 어려울 경우에 다른 NUMA 노드의 코어에 추가적으로 친화도 설정이 가능하도록 한다. 따라서 Single-socket 정책 보다 I/O 스택의 지역성을 낮출 수 있는 반면 병렬성을 높일 수 있다.
Single-socket Core Partitioning
시스템 호출 문맥을 하나의 소켓에 속한 코어들에 친화도를 가지도록 하여 I/O 스택의 지역성을 향상시킨다.
Cross-socket Core Partitioning
Single-socket Core Partitioning과 유사한 정책이지만, 하나의 소켓을 이용하여 I/O 작업을 충분히 동작시킬 수 없을 때 다른 소켓의 코어에 추가적으로 친화도를 설정하는 방법이다. 친화도가 분산되어 지역성이 다소 낮아질 수 있으나 병렬성을 높일 수 있다.
Per-socket Core Partitioning
시스템 호출을 요청한 스레드가 동작하고 있는 소켓내에서 친화도를 가지도록 한다. 이 정책은 유저 영역 I/O 버퍼의 지역성을 향상시킨다.
실험 결과
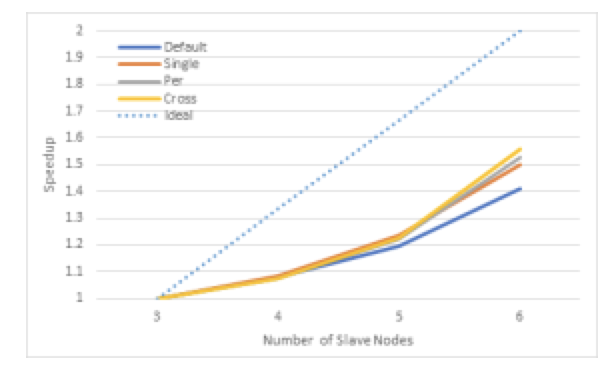
100GB데이터를 이용한 하둡 맵 리듀스 응용(WordCount)을 슬레이브 노드의 개수를 3개에서 6개까지 조절하며 수행한다. 이상적인 성능 향상은 노드의 수에 비례하여 성능이 향상되는 것 이지만 현실적으로 확장성 문제로 인하여 그러한 성능 향상은 보이지 못한다. 하지만 코어 파티셔닝을 적용하여 최대 1.56배의 속도 향상을 관찰 할 수 있었고, Cross-socket 정책을 사용할 때 가장 큰 속도 향상을 보였다.
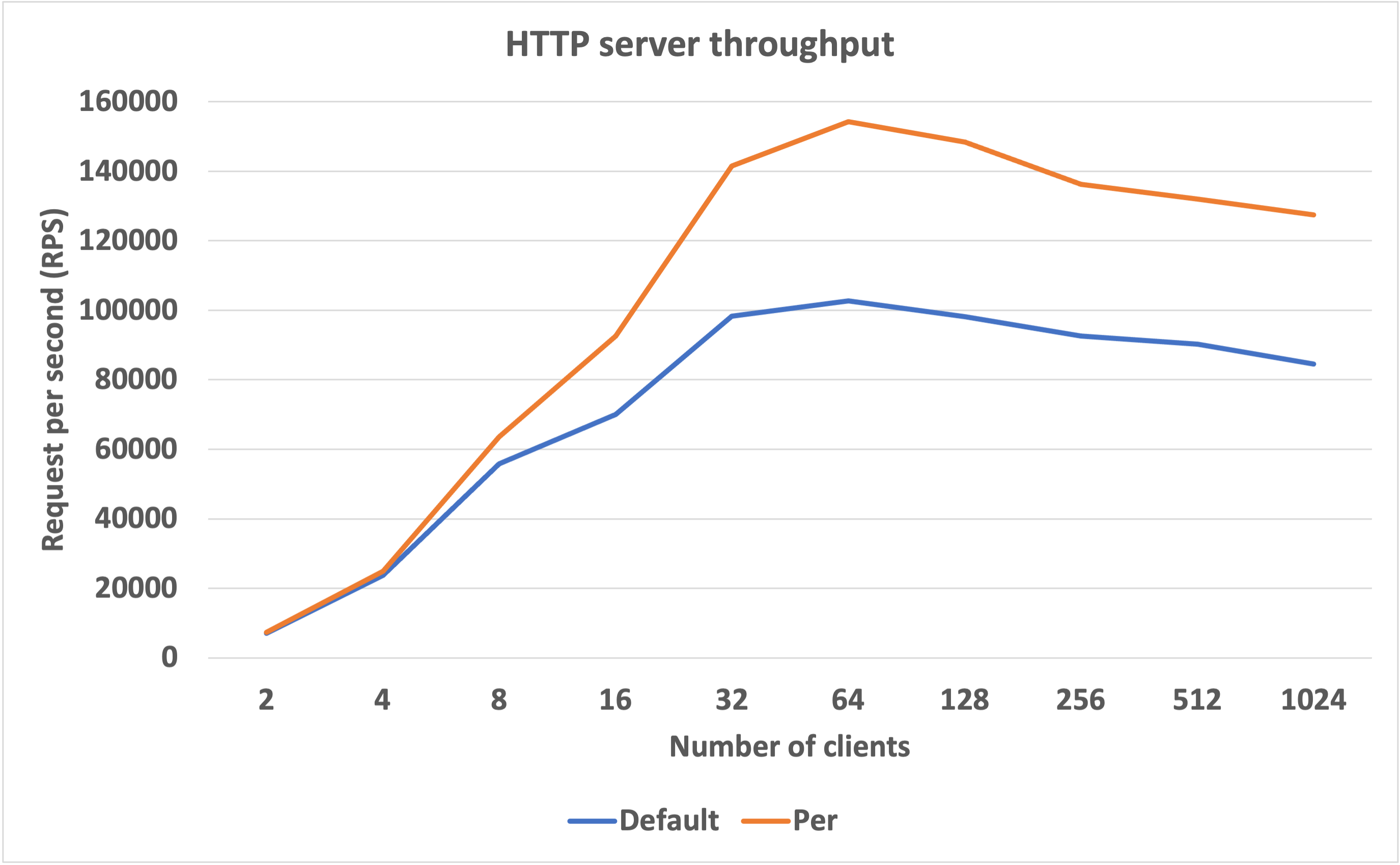
또한 아파치 웹 서버에 Jmeter를 이용한 부하 테스트를 통하여 Http web server throughput을 측정하는 실험을 통해 I/O의 성능 향상 정도를 측정했다. 이때 사용된 코어 파티셔닝은 Per-socket Core Partitioning 이고, 최대 51%의 throughput 향상이 있었다.
연구 결과물
- 논문
- Chan-Gyu Lee, Hyun-Wook Jin, "NUMA-aware I/O System Call Steering", Proceedings of 2021 IEEE International Conference on Cluster Computing (Cluster 2021), pp. 805-806, Poster, Portland, OR, USA, September 2021.
- 이찬규, 진현욱, "매니코어 파티셔닝의 수평적 확장성 분석", 한국정보과학회 2021 한국소프트웨어종합학술대회논문집, 2021년 12월.
- Chan-Gyu Lee, Joong-Yeon-Cho, Hyun-Wook Jin, "Transparent Many-core Partitioning for High-performance Big Data I/O", Concurrency and Computation: Practice and Experience, Vol. 33, No. 18, August 2021.
- 이찬규, 조중연, 진현욱, "매니코어 파티셔닝을 위한 동적 코어 친화도", .정보과학회논문지,제47권, 제12호, pp. 1111-1119, 2020년 12월.
- 이찬규, 진현욱, "매니코어 환경에서 시스템 호출과 고성능 입출력 장치를 위한 동적 코어 친화도", 한국정보과학회 2019 한국소프트웨어종합학술대회논문집, 2019년 12월.
- 공개 소프트웨어
- Github: Syscalib
- 시연 영상