온도, 전력 관리 및 에너지 절감 기술 연구
컴퓨터 시스템의 전력 소모를 조절하는 기술은 그 목적에 따라 크게 두가지로 구분할 수 있다. 한가지는 하드웨어를 과도한 전력 소모와 온도 증가로 부터 보호하기 위한 전력 관리 기술 (Power management technique)이고, 다른 하나는 연산 비용을 감소시키는 것을 목적으로 하는 에너지 효율적 컴퓨팅 (Energy-efficient computing) 이다. 두가지 기술은 서로 다른 목적을 가지고 있긴 하지만, 각 요소 기술이 적용되는 부분과 기술이 시스템에 미치는 영향이 매우 밀접하게 연관되어 있으므로 효율적 시스템을 구축하기 위해서는 서로 다른 기술들이 잘 이해되고 적절히 연결되어야 한다. 본 과제에서는 매니코어 시스템의 가용성 유지를 위한 온도, 전력 관리 기술과 에너지 절감 기술에 대한 연구를 진행하고 있다.
이 글에서는 온도, 전력 관리 및 에너지 절감 기술의 목적과 특징에 대해서 설명하고 본 과제를 통해 연구 개발된 기술에 대해 소개하고자 한다.
온도 및 전력 관리 기술
컴퓨터 시스템의 각 장치들이 소모하는 전력은 모두 열로 방출되는데 높은 온도와 전력 소모는 장치 고장의 원인이 될 수 있기 때문에 온도와 전력 소모를 일정 수준 이하로 유지하는것은 시스템 설계시 가장 우선적으로 고려되어야 할 요소이다. 반도체는 온도가 올라가면 저항도 함께 증가하여 전력 소모가 늘어나는 특징을 가지고 있기 때문에 온도와 전력 제어는 가용성 유지라는 동일한 목적을 가지고 있으며, 같은 기법을 통해 달성 될 수 있다. 따라서 온도와 전력 제어를 동일한 범주의 연구로 간주된다.
소프트웨어에서 전력 및 온도를 제어하는 기술이 필요하게 된 것은 예측할 수 없는 환경 변화와 다양한 워크로드 특성 때문이었다. 동적 전력 관리(Dynamic power management:DPM), 동적 온도 관리 (Dynamic thermal management: DTM) 등으로 소개 되는 Power-aware computing 기술은 실시간으로 소모되는 전력과 온도를 측정하여, 적정 기준 이상이 될 경우 동작 속도를 낮추거나 일시적으로 중단시키는것이 기본이다. 이 분야의 연구들은 아래의 목록과 같이 분류될 수 있다.
- 전력 제어 및 관리 (Power control & management)
- 전력을 적정 수준 이하로 제어하는 기법에 대해 연구한다. 기술에서 달성하고자 하는 목표는 시스템이 안전한 범위 내에서 동작하도록 제어하는 것이다. 불가피한 성능 저하나, 총 비용 증가 등의 부작용을 감수하기도 한다.
- 전력 소모를 줄이는 throttling 을 위해 동작 주파수 및 전압을 조절하는 DVFS(Dynamic voltage and frequency scaling)를 비롯하여 메모리 제한 (Memory throttling), 유휴 삽입 (Idle injection) 등의 기법을 활용한다. 공통적으로 자원 사용을 제한하여 전력 소비량을 조절하는 방식이다.
- 데이터 센터와 같은 대규모 시스템을 위한 power capping 도 전력 제어 기술을 바탕으로 한다. 이 연구는 가용성 유지를 위한 전력 제어 보다 더 적극적으로 전력 소모를 조절하는것이 특징이다. 전체 시스템을 고려하여 각 노드의 전력 소비를 동적으로 제어해야할 때, 혹은 요구된 서비스 비용에 맞추어 성능을 제공하고자 할 때 이와 같은 기술을 적용할 수 있다.
- 온도 제어 및 관리 (Thermal control & management)
- 온도를 적정 수준 이하로 제어하는 기법이다. 온도를 낮추려면 소모 전력을 줄여야 하기 때문에 power throttling을 통해 구현된다. 다만, 온도의 경우 전력 보다 증가하는 속도가 느리고 주변 환경의 영향을 크게 받기 때문에, 두가지 원인에 의한 throttling이 동시에 일어나는 일은 드물고, 전력이나 온도 제어 중 한가지 기능 만으로 두가지 문제를 모두 해결하는 것은 불가능 하다.
프로세서의 전력 제어 기법
전력 상한제한에서는 실시간으로 소모되는 전력을 측정하여, 적정 기준 이상이 될 경우, 프로세서의 동작 속도를 낮추거나 일시적으로 중단하는 기법 등을 통해 전력소모를 줄이는 것이 기본이다. 전력 제어 기법에도 다양한 방식이 존재하며 방식 마다 장점과 단점이 있기 때문에 이를 잘 이해하고 적용하는 것이 중요하다.
- DVFS
DVFS는 싱글 코어 프로세서 (Single core processor)로 부터 사용된 온도 및 전력 제어 기술로써 대부분의 프로세서에서 활용되고 있다. 프로세서를 구성하는 CMOS 게이트가 스위칭 동작을 수행할 때 전력 소모량 P = C·V2·f로 계산 되며, 이때 C는 스위치의 정전 용량, V는 동작 전압, f는 동작 주파수 이다. CMOS gate는 전압이 높을 수록 더 빠르게 충전될 수 있기 때문에 동작 주파수는 전압에 비례하여 결정되므로 전력 소모량은 동작 주파수의 세제곱에 비례하게된다. CMOS 게이트의 비중이 높은 과거의 프로세서 에서는 줄어드는 성능 보다 더 많은 전력을 절감하는 것이 가능했다.
- Clock gating
사용되지 않는 부분의 소모 전력을 줄이기 위해 사용되는 가장 기본적인 방법은 클록 게이팅(Clock gating) 이다. 클록 게이팅은 사용되지 않는 회로에 클럭이 인가되지 않게 하여 동적 전력 소모를 없애는 방법이다. 이 방식은 유휴(Idle) 상태의 프로세서의 소모전력을 획기적으로 줄일 수 있는 반면 클럭을 다시 인가시키는데 시간이 걸리기 때문에 프로세서가 사용되는 도중에 수시로 사용될 수는 없는 방법이다. 사용되지 않는 프로세서의 전력 소모를 줄이는 방법에는 클록 게이팅외에도 인가되는 전압을 낮추고 캐시를 비우는 등의 방법도 포함되어 있으며, 더 많은 전력을 아낄 수 있게 될 수록 동작 가능한 상태로 돌아오는데 필요한 지연시간이 길어진다.
- Idle injection
유휴 상태는 HLT 명령을 통해 연산을 수행하지 않는 슬립 상태와 클록 게이팅을 통해 전력 소모를 최대한으로 줄인 딥 슬립(Deep sleep) 상태가 있다. 워크로드가 실행되는 동안에는 상태가 변경되는 동안 지연시간이 긴 딥 슬립은 상태가 되는 것은 어렵지만, 코어가 슬립과 실행을 짧은 주기로 반복하게 하여 전력 소모를 조절하는것이 가능하다. 이러한 기법을 아이들 인젝션(Idle injection)이라고 한다.
매니코어를 위한 전력 제어
과거 Power-aware Computing은 전력 관리와 에너지 효율성 개선 문제를 정확하게 구분하지 않고 다루고 있었다. 이러한 연구는 대부분 DVFS 기술을 활용하고 있는데, 연구가 진행된 시기의 프로세서는 대부분 동작 주파수를 낮추었을때 감수해야하는 성능 저하보다, 전력 소모 감소 비율이 더 큰 특징을 가지고 있었다. 프로세서를 구성하고 있는 CMOS들이 스위칭될때 소모하는 전력은 주파수의 세제곱에 비례하여 증가하는데, 이러한 특징이 프로세서에서 그대로 드러나고, 주파수는 낮춘다는 것만으로도 에너지를 쉽게 아낄수 있었다.
하지만, DVFS는 더이상 마법과 같이 에너지 소모를 줄여주는 수단이 아니다. 컴퓨터 시스템에서 전력 및 에너지 효율이 중요하게 다루어지면서, 최신의 프로세서들은 최적의 에너지 효율을 제공할 수 있도록 동작 주파수 구간을 설계한다. 이러한 프로세서의 전력 소모에 비례하여 성능이 결정된다.
또한 Static power의 비중이 늘어난 것도 DVFS의 효용을 감소시키는 원인 중에 하나이다. 멀티 코어의 시대로 넘어 오면서 프로세서는 인터커넥트, 캐시 등을 위해 많은 면적을 할애하고 있으며 이 소자들은 전원이 켜지면 지속적으로 전력을 소모하는 특징을 가진다. 앞서 소개한 대기상태의 전력 관리를 통해 static power를 줄일 수 있게 되면서, 적절한 속도로 천천히 실행하는것과 빨리 실행시켜버리고 더 많이 쉬도록 하는 경우에서 어느쪽이 더 에너지 효율적인지를 단정할 수 없게 되었다.
뿐만 아니라, 터보(Turbo) 기술을 활용할 경우 운영체제 수준에서 명시적 주파수 조절이 불가능해진다. 따라서 매니코어 환경에서는 유휴 삽입(idle injection)을 통한 전력 조절이 위한 거의 유일한 방법이 되었다.
또한, DVFS에 의한 전력을 조절하게 되면 하드웨어적으로 조절 단계와 범위가 정해지지만, 유휴 삽입은 별도의 단계나 범위가 존재하지 않아, 필요한 만큼만 성능을 저하시킬 수 있으므로 전력 소모 감소로 인한 성능 저하를 최소화할 수 있다.
온도 관리 기술
반도체는 온도가 올라갈 때 저항을 증가시키는 성질을 가지고 있기 때문에 온도가 증가하면 소모되는 전력도 함께 증가한다. 온도로 인해 추가적으로 발생하는 전력을 Power dissipation 이라고 하고, 온도 증가가 소모 전력으로 이어지고 다시 온도가 증가하는 문제를 Thermal Runaway 라고 한다. 프로세서의 온도가 높이 올라가면 신뢰성이 감소되고, 내구성이 저하 될 수 있으며, 심각한 고장을 일으키기도 한다. 프로세서를 위한 온도 관리는 이러한 위험 요소들로 부터 프로세서를 보호하는것을 목적으로 한다.
매니코어 시스템에서는 사용되는 DVFS 와 사용 코어 수와 같이 자원 사용량 조절을 위한 선택의 폭이 넓어지며, 고려해야 하는 상항도 복잡해지게 된다. 그렇기 때문에 그 중 가장 적합한 방법을 하드웨어 수준에서 선택하는 것에는 한계가 있다. 우리는 달라진 매니코어 환경을 고려하여 적합한 전력 및 온도 관리 기법에 대해 연구하였다.
- 실시간 온도 예측
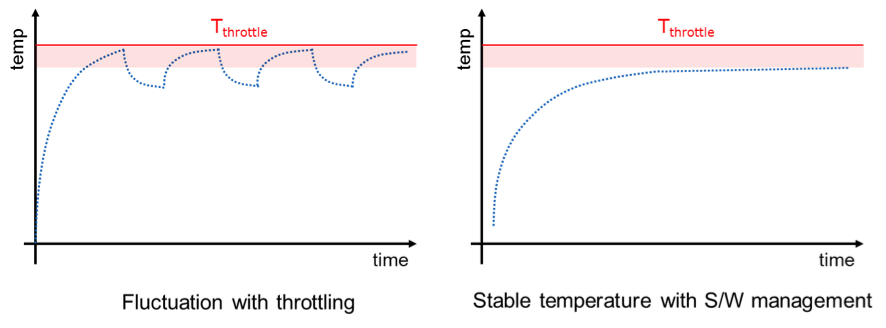
프로세서에서 제공하는 동적 온도 관리 기법은 기본적으로 온도 센서를 통해 측정되는 현재 온도를 바탕으로 대응하는 방식이다. 이러한 사후 온도 조절 방식에서는 프로세서가 온도를 낮추기 위해서 전력제한을 걸었다가 다시 원상복귀 시키는 과정을 반복하면서 아래의 왼쪽 그림과 같이 정상 온도와 이상 고온을 반복적으로 오르내리게 될 가능성이 있다. 이러한 온도 불안정한 변화는 시스템의 성능을 예측하기 어렵게 만들고, 성능을 변경하기 위한 오버헤드를 발생시키며 반복적으로 프로세서를 고온에 노출시켜 신뢰도를 떨어뜨릴 수 있다. 이러한 동적 온도 관리 기법의 한계는 소프트웨어를 통해 예측에 기반하여 온도를 관리를 하는 것으로 극복될 수 있다. 이 연구에서는 주변 환경의 급격한 변화, 다양한 워크로드의 실행에도 관계없이 최고 온도를 일정하게 유지할 수 있도록 하는 기술을 연구하였다.
- 냉각 효율 기반 온도 예측 모델
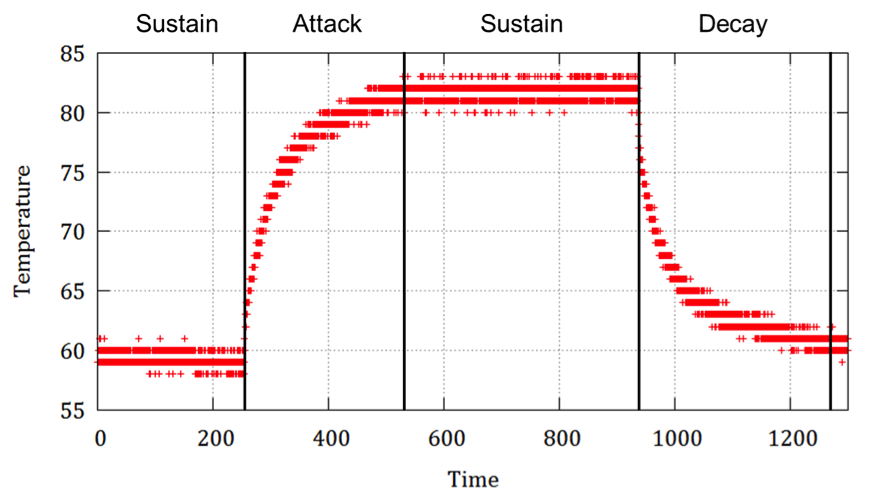
프로세서가 워크로드를 실행할 때 관측되는 온도 변화에 따라 위 그림과 같이 유지(Sustain), 상승(Attack), 하강(Decay)의 세가지 상태로 구분할 수 있다. 각 상태별 열적 상태는 아래 그림과 같이 설명될 수 있다. 상승 상태에서는 프로세서에서 냉각 가능한 열량 보다 더 많은 열을 방출하는 경우, 유지 단계에서는 동일한 양의 열을, 하강 단계에서는 적을 열을 방출한다.
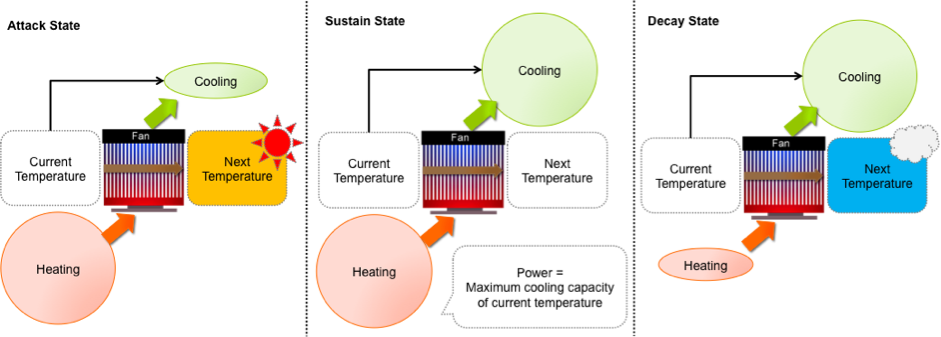
이때 냉각 가능 열량은 프로세서의 온도와 주변 온도와의 차이에 비례한다. 이 냉각 가능 열량 유지 단계에서의 전력과 온도 측정 데이터를 수집하여 계산할 수 있다. 어떤 시점에서 온도와 전력을 안다면 해당 온도에 대한 냉각 용량을 알 수 있으며, 이 값을 소모 전력에서 빼면 온도 상승에 영향을 주는 열량을 파악할 수 있다. 온도 변화에 영향을 주는 열량과 온도 변화 사이의 관계를 관측하면 온도-전력 비례 계수 또한 계산 할 수 있다. 이 두가지 정보를 활용하면 다음 시점의 온도를 예측하는것이 가능해진다.
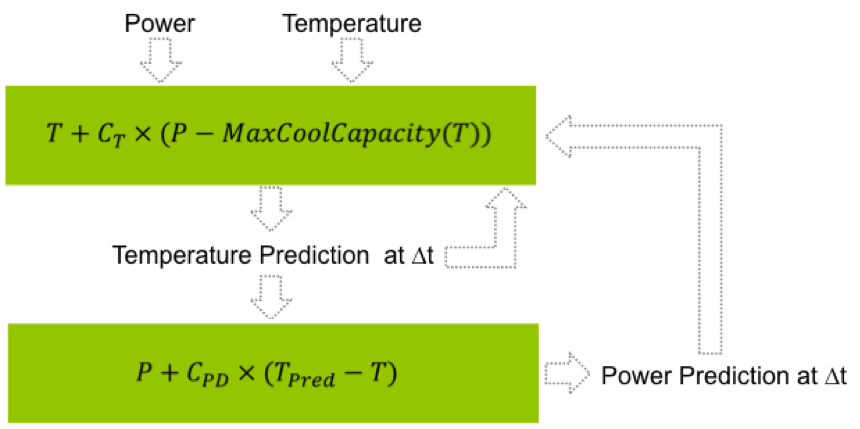
위 그림은 냉각 가능 용량과 온도-전력 비례 계수를 사용하여 온도 예측이 어떻게 이루어질 수 있는지 보여주는 그림이다. 두 값을 통해 짧은 시간 이후의 온도를 예측하고 예측된 온도 값을 이용하여 그 이후의 값을 예측하는 방식이다. 이때 워크로드가 소모하는 전력 소모 특징은 변하지 않는 다고 가정하고, 온도 증가에 따른 누수 전력의 변화를 고려하여 해당 시점의 전력 소모량을 예측한다.
이러한 온도 예측 기술을 활용하면 매우 낮은 오버헤드만으로 실시간으로 온도 변화를 예측하고, 급격한 온도 변화에 대비하는 것이 가능하다
- Thermal Margin Preservation: QoS 보장을 위한 온도 관리
프로세서의 온도 관리는 프로세서가 고온에서 동작하면서 발생할 수 있는 고장과 신뢰성 저하로 부터 프로세서를 보호하는 것을 최우선으로 고려하기 때문에 실행중이 워크로드에 대한 고려 없이 온도가 정해진 값 이상으로 올라갈 경우 강제적으로 소모 전력과 성능을 줄인다. 이러한 강제적 온도 관리는 다양한 우선 순위의 태스크가 동시에 실행되는 시스템에서 우선 순위가 높은 워크로드가 우선 순위가 낮은 워크로드로 인해 성능에 영향을 받는 문제가 생길 수 있다.
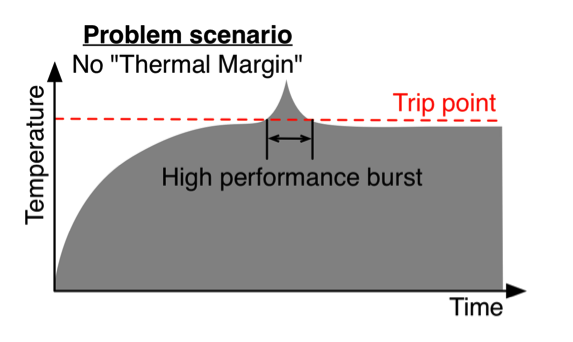
위 그림은 온도로 인해 우선순위가 높은 태스크가 영향을 받는 상황을 설명하는 그림이다. 우선 순위가 높지 않은 워크로드가 온도 상한(Trip point)를 넘지 않도록 프로세서를 사용하는 상황에서 높은 성능을 요구하며, 자원 사용 밀도가 높은 워크로드가 새롭게 시작하였을 때 시간의 흐름에 따라 프로세서의 온도의 변화를 나타내었다. High performance burst란 자원을 밀도있게 사용하며 높은 성능을 요구하는 워크로드가 실행된 상황을 의미한다. 새롭게 시작된 워크로드는 프로세서의 온도가 상한점 이상으로 상승 시킬 수 있다. 온도가 올라가면 프로세서는 강제적으로 성능을 저하시키게 되므로 높은 우선 순위의 워크로드는 낮은 성능에서 실행되게 된다.
이러한 문제를 해결하기 위해서 본 과제에서는 우선 순위 따라 온도 상한을 다르게 주는 Thermal Margin Preservation(TMP) 기법을 제안하였다. Thermal Margin은 프로세서의 온도 상한점 보다 낮은 온도로 유지하여 갑자기 시작된 다른 워크로드가 온도를 상승 시킬 여지를 남겨 둔다는 의미로 결정된 명칭이다.
아래 그림은 우선 순위에 따라 상한온도를 다르게 설정할 경우 위에서 설명된 문제가 어떻게 해결되는 지를 보여준다. 시스템은 우선순위가 낮은 응용을 실행하는 동안은 하드웨어적 온도 상한점에서 정해진 마진을 남겨둔 온도를 새로운 온도 상한으로 설정하게된다. 이때 우선순위가 높은 응용이 새롭게 시작되면, 온도 상한을 재설정하여 온도를 더 높일 수 있는 여지를 제공한다. 따라서 워크로드는 요구되는 높은 성능을 보장받으면서 실행될 수 있게 된다.
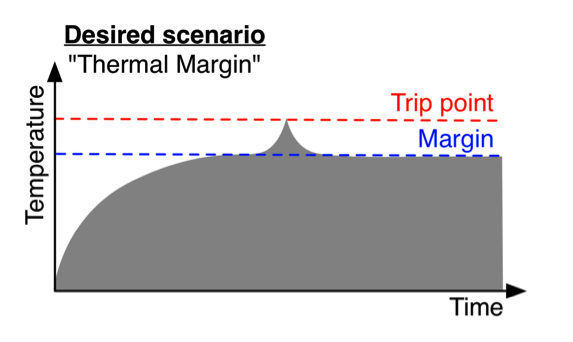
우선 순위가 낮은 워크로드의 경우 자유롭게 온도를 높일 수 있던 기존의 방법 보다는 더 느리게 실행될 수 있지만, 우선 순위가 높은 워크로드의 성능이 보장하는 것이 가능하다. 또한 우선 순위별로 제공가능한 최대 성능이 차등화 되고 워크로드간 불필요한 성능 간섭을 줄일 수 있기 때문에 성능 예측과 서비스 품질 보장이 요구되는 시스템에 필요한 기술이다.
결과물
- 논문
- [A Thermal Margin Preservation Scheme for Interactive Multimedia Consumer Electronics](/Data/papers/02/02-13-01 A Thermal Margin Preservation Scheme for Interactive Multimedia Consumer Electronics.pdf]
- 특허
- 반도체 장치를 위한 실시간 온도 예측 장치 및 방법, 등록 10-1621655 (출원 10-2015-0059150)
- Thermal management apparatus and method using dynamic thermal margin, and semiconductor processor device, non-volatile data storage device and access control method using the same, 미국 특허 출원 15/221,909
에너지 효율성 개선
대규모 컴퓨팅 시스템을 구성하고 운영할 때 비용 및 환경적 측면에서 에너지 소모를 줄이는 것은 매우 중요한 과제이다. 컴퓨터를 운영하기 위해 소모하는 에너지 비용을 줄이는것을 목적으로 하는 기술은 모두 enegy-efficient computing으로 구분할 수 있다. 시스템의 비용 효율을 높이는 것을 목적으로 하기 때문에 전력 소모를 줄이기 위해 과도한 성능 저하를 유발하거나, 전체 비용이 증가하는 것을 허용하지 않으며, 시스템은 늘 안전한 상황에 있다고 가정하고 있으므로, 위에서 설명한 전력 관리 기술과는 그 맥을 달리한다.
최근 에너지 효율성을 개선하기 위한 연구는 워크로드가 실행과 관련된 에너지 소비를 줄이는 기술과, 여러 단계로 구분된 Idle 상태를 활용하는 기술로 구분할 수 있다.
- Static Energy 효율 개선
- Static energy는 프로세서의 사용 여부와는 관계없이 장치를 켜두기 위해 소모하는 에너지를 의미한다. 프로세서를 사용하지 않을 때 Clock gating 등의 기법을 통해 이 에너지를 줄이는 것이 가능하다.
- 대기 상태의 전력관리 : 인텔의 경우 C-state를 통해 코어가 사용되지 않을 때 대기전력을 줄이는것을 지원한다. 이러한 대기 전력 관리는 클록 게이팅과 전압 낮추기, 캐시 비우기 등을 포함하고 있다. 클록 게이팅은 사용되지 않는 회로에 클럭이 인가되지 않게 하여 전력 소모를 줄이는 기법이다. 이 방식은 대기 상태 (Idle state)의 프로세서의 소모전력을 획기적으로 줄일 수 있는 반면, 클럭을 다시 인가시키는데 시간이 걸리기 때문에 프로세서가 사용되는 도중에 수시로 사용될 수는 없는 방법이다. 더 많은 전력을 아낄 수 있게 될 수록 동작 가능한 상태로 돌아오는데 필요한 지연시간이 길어진다.
- Dynamic Energy 효율 개선
- Dynamic energy는 프로세서에서 실제로 연산을 수행하기 위해 소모하는 에너지를 의미한다. DVFS, Idle injection 등의 방법으로 소모 전력을 조절 할 수 있다.
- 과거에는 DVFS를 통해 전력 소모를 조절할 경우 발생하는 성능 변화와 비용 증가 사이에서 가장 효율적인 지점을 찾는 연구를 주로 수행하였으며, 최근에는 비 효율적인 구조나 동작을 개선하여 불필요한 전력 소모를 줄이는 방향으로 연구 방향이 바뀌고 있다.
커널 스핀락의 에너지 효율성을 개선한 Catnap 스핀락
다수의 코어를 활용하여 병렬로 작업을 수행할 때 투입된 코어 수가 많아질수록 오버헤드가 커지면서 성능 증가의 폭도 줄어든다. 이 오버헤드를 발생시키는 주 원인은 동기화에서 찾아볼 수 있다. 그런데 동기화로 인해 직렬화된 구간은 전체 성능을 감소시키는 것 뿐만 아니라 에너지 낭비를 증가시키는 원인이 되기도 한다.
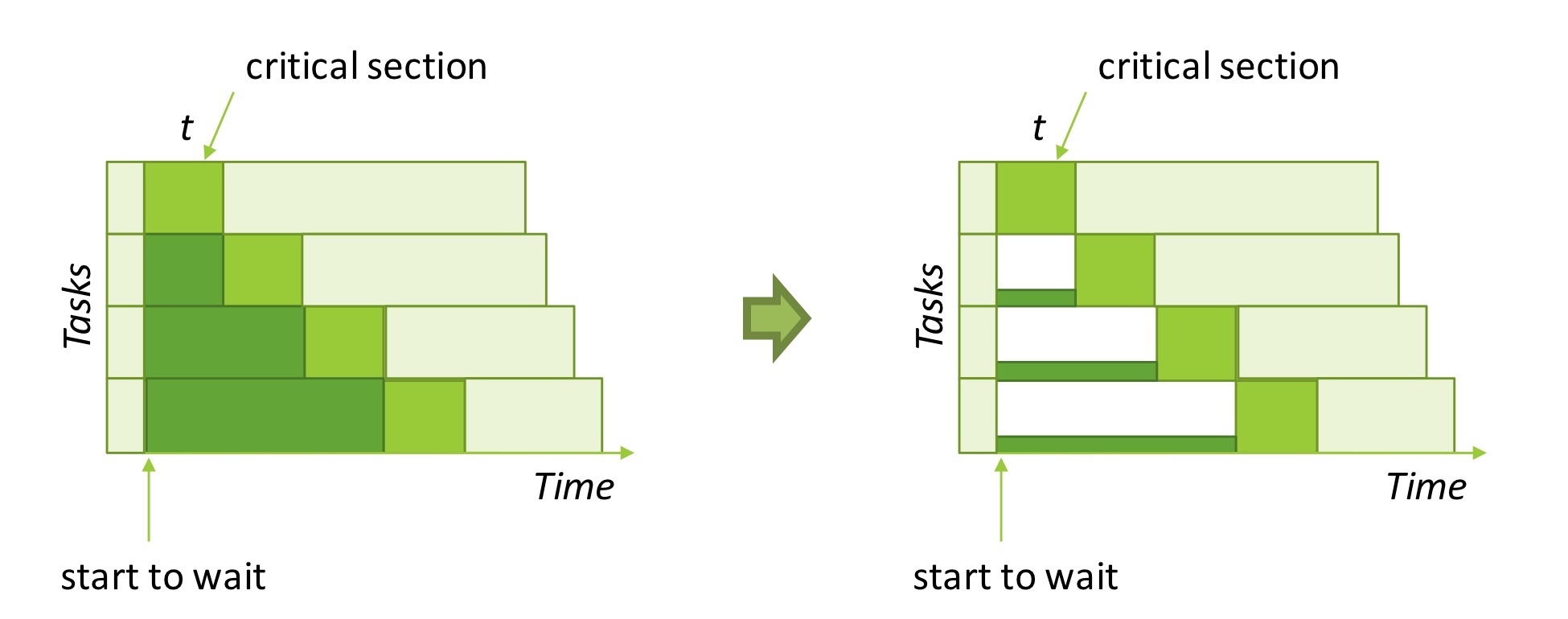
위 그림은 바쁜 대기 방식으로 동기화될 때 발생하는 오버헤드가 가장 커지는 경우에 에너지 낭비가 얼마나 심각해질 수 있는지를 설명하고 있다. 그림은 4개의 태스크가 각각 세로축의 높이만큼 전력을 소모하면서 실행되다가 동시에 임계 영역에 접근하는 경우를 보여주고 있다.
임계 영역의 길이가 t라면 마지막에 락을 얻게되는 태스크는 3t 만큼 기다려야한다. 바쁜 대기를 사용하고 있기 때문에 락을 기다리는 태스크들이 소모하는 전력은 작업 수행에 도움이 되지 않은 낭비이며, 이 예시에서 낭비되는 에너지는 6t에 달한다. 동시에 임계영역에 접근하는 태스크가 많을수록 이 낭비는 기하급수적으로 늘어날 수 있다.
이러한 낭비는 그림의 오른쪽과 같이 대기하는 태스크들을 유휴 상태 (Idle state)로 보내거나 태스크를 재우는 것으로 줄일 수 있다. 기존의 Blocking 방식의 동기화의 경우 기다리는 태스크를 sleep 상태로 변경하여 자원 낭비를 막고있지만, 바쁜 대기에 비해 오버헤드가 크고 실제로 sleep 상태가 되기 까지 상당한 딜레이가 필요하기 때문에 임계 영역의 길이가 충분하지 않은 경우에 성능 저하를 크게 발생시킬 수 있다. 따라서 바쁜 대기의 형태를 그대로 유지하면서 대기 태스크들이 전력을 덜 소모하도록 만드는 기법이 필요하다.
리눅스 커널에서 스핀락은 매니코어 환경에서 확장성 (Scalability)을 제공하기 위해 MCS 락의 변형인 큐-스핀락 (Queued spinlock)을 사용한다. 큐-스핀락에서 대기 태스크는 전용의 노드에 대해서 spinning 하면서 차례를 기다린다. 따라서 다수의 태스크가 1개의 변수를 반복적으로 확인하면서 발생할 수 있는 캐시와 버스, 메모리 등에 발생하는 경쟁 문제를 근본적으로 해결할 수 있다. 그로 인해 리눅스 커널은 수십 개의 코어를 가진 시스템에서 합리적인 확장성을 제공하는 것이 가능해졌다. 하지만 대기 태스크들은 더 원활하게 spinning 할 수 있게 되었고, 대기 태스크의 전력 낭비 문제는 그대로 남겨져있다.
본 연구진은 리눅스 커널의 에너지 효율성을 개선하기 위해 Catnap 스핀락을 개발하였다. Catnap 스핀락은 대기 중인 태스크가 코어를 유휴 상태로 변경한 후 대기한다. 스케쥴 아웃되지 않으므로 깨어나는데 걸리는 시간이 비교적 짧으면서 대기중에 코어가 저전력 모드로 들어가게 되므로 전력 소모가 줄어든다. 또한, 하이퍼쓰레딩 구조와 결합하여 자원 활용율을 높이는데 도움을 준다. 매니코어 환경에서 리눅스 커널에 Catnap 스핀락 기술을 적용하였을때 AIM7 벤치마크의 에너지 소모가 10.17%~10.75% 절감되는것을 확인하였다.
Energy Efficient Polling 기법
polling은 프로그램이나 장치들이 어떤 상태에 있는지를 주기적으로 확인하고 사용 가능한 시점이 되면 요청을 처리하도록 하는 기법이다. polling은 장치의 상태가 변할 때 발생하는 신호를 통해 깨어나서 요청을 처리하는 인터럽트와는 달리 주기적으로 깨어나 상태를 확인하는 연산을 수행하기 때문에 요청 지연 시간이 길어지면 길어질수록 더 많은 연산을 수행하게 된다. 이러한 단점에도 불구하고, 인터럽트에 비해 빠른 응답시간 빠르고 대역폭이 큰 장치를 지원하기에 적합하기 때문에 네크워크 통신의 처리는 polling 기법을 활용하여 구현된다.
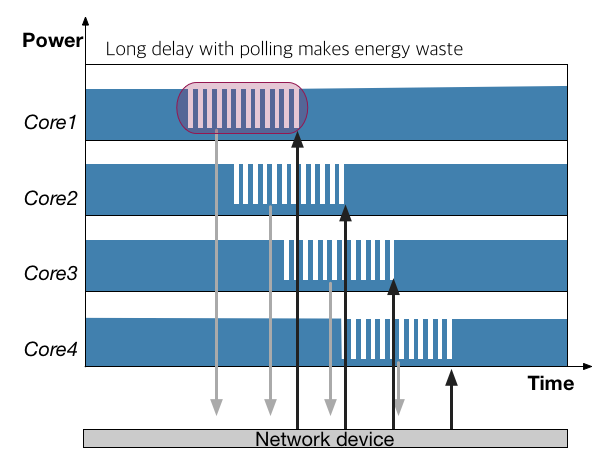
매니코어 환경에서는 코어들이 동시에 네크워크 통신을 사용할 때 매우 쉽게 contention이 관측될 수 있는데, 그때 각 코어가 polling을 수행하고 있다면, 전체 프로세서의 관점에서는 매우 많은 자원이 불필요하게 소모되는 문제가 발생할 수 있다. 아래의 왼쪽 그림은 네트워크에서 경쟁이 발생했을때 각 코어의 지연시간이 증가하면서 늘어날 불필요한 에너지 소모를 보이고자 하였다. 이때 polling 주기가 길어져서 대기 중에 적게 깨어날 수 있다면, 성능 저하 없이 이러한 불필요한 에너지 소모를 줄이는 것이 가능할 것이다. Energy efficient polling은 커널 안에서 contention을 관측하여 polling 주기를 동적으로 조절 하는 기술이다.
결과물
- 공개 소프트웨어
- Github: Catnap
- 시연영상
전력 캡핑
전력 캡핑(power-capping)은 평균 전력 소모를 허용량 이하로 유지시키는 기술로, 데이터 센터의 전력 집적도를 높여 전력 공급 비용을 절감할 수 있게 해준다. 단일 서버 수준의 전력 캡핑 기술은 전력 공급 장치에 과부하가 걸릴 가능성을 제거하여 유연한 전력 관리 시스템을 구축하는 것을 가능하게 한다. 특히 매니코어(manycore) 시스템은 단일 시스템 수준에서도 전력 집적도가 높으며 평균 전력 소모가 큰 고성능 워크로드를 위해 주로 사용되므로 전력 캡핑 기술의 중요성이 더욱 크다고 할 수 있다.
Idle injection 기반의 전력 캡핑
매니코어에서 정밀하게 전력 소모를 제어하여 가용 범위 내에서 성능을 최대한 제공하기 위해서 idle injection 기법을 활용한 전력 캐핑 기술에대한 연구를 진행하였다. 전력 캡핑을 구현하기 위해서는 전력 절감이 요구될 때 전력 소모를 즉각적으로 변화시킬 수 있어야 하는데, 이를 위해서는 요구되는 성능 수준까지 단번에 할 수 있어야한다. 이러한 두가지 요구를 만족시키기 위해서는 현재 전력 사용량을 기반으로 적절한 유휴 전력을 계산해주는 동적 전력 모델이 필요하다.
전력 캡핑 전력 모델
유휴 삽입이 코어의 상태를 변경하여 전력 소모를 낮추겠지만, 그 양과 관계를 정확히 파악하지 못한다면 목표로 하는 전력의 상한 값에 맞출 수 없다. 전력 제한으로 인해 전력 소모를 강제적으로 줄여야 할 때, 허용된 범위안에서는 성능을 최대한 사용할 수 있도록 하기 위해서 적절한 유휴 삽입 비율을 계산하는데 사용할 전력 모델을 설계하였다. 전력 모델을 설계하기 위해서 유휴 삽입을 수행하면서 유휴 비율이 전력 소모에 미치는 영향을 실험적으로 파악하고 두가지 측정 데이터 사이의 관계를 정의하였다.
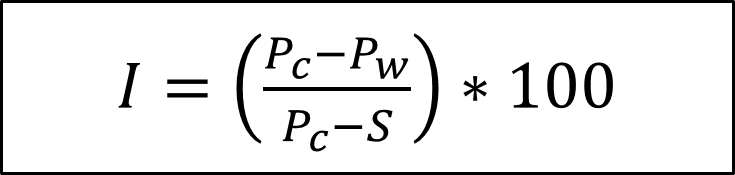
위 수식에서 I는 유휴 상태 비율, Pc는 현재의 전력, Pw는 원하는 전력의 상한선, S는 시스템의 정적 전력을 나타낸다. 이 모델을 통하여 전력 소모가 한계를 초과한 경우 목표로 하는 전력량에 맞추어 전력 소모를 줄이기 위해서 삽입해야 할 유휴 비율을 계산할 수 있다.
- 리눅스 커널을 위한 전력 캡핑 모듈
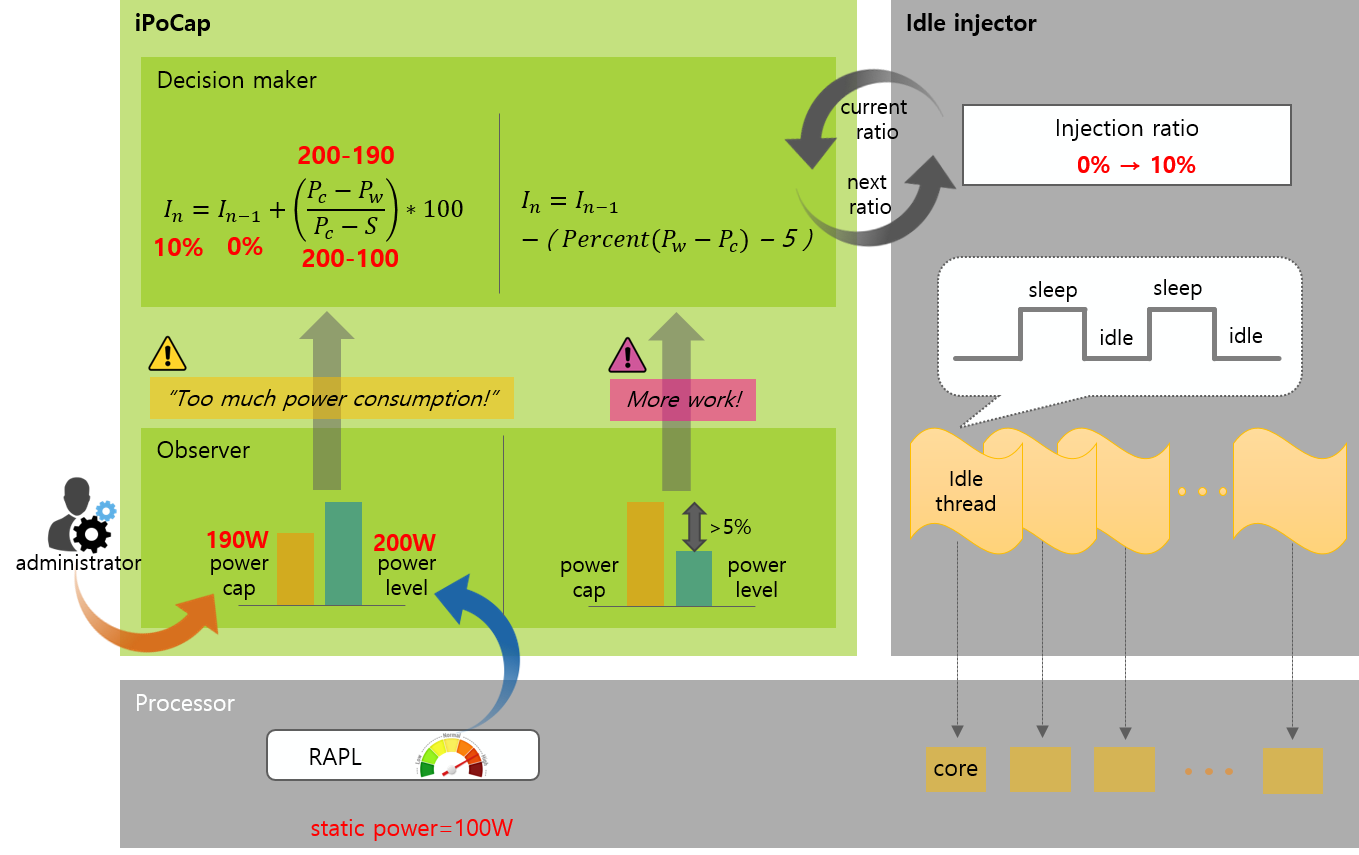
리눅스 커널을 위한 전력 상한제한 모듈을 구현하고 전력 모델의 정확도를 평가하였다. 구현된 전력 캐핑 모듈은 W 단위로 전력 상한을 지정할 수 있으며, 주기적으로 소모 전력과 전력 상한을 비교하여 전력 모델을 통해 적정 수준의 유휴 삽입을 자동으로 수행한다. 아래 그림은 우리가 개발한 모듈의 구조를 보여주고 있다.
- 실험 및 평가
구현한 유휴 삽입에 기반한 전력 캡핑 모듈이 매니코어 시스템 환경에서 잘 동작하는지를 확인하기 위해 KNL 실험 환경에서 테스트를 진행하였다. NPB의 BT 워크로드를 256개의 쓰레드로 돌려 실험 결과를 하였으며, BT는 전력 캡핑을 하지 않은 상태에서는 평균 209.03W의 전력으로 동작한다.
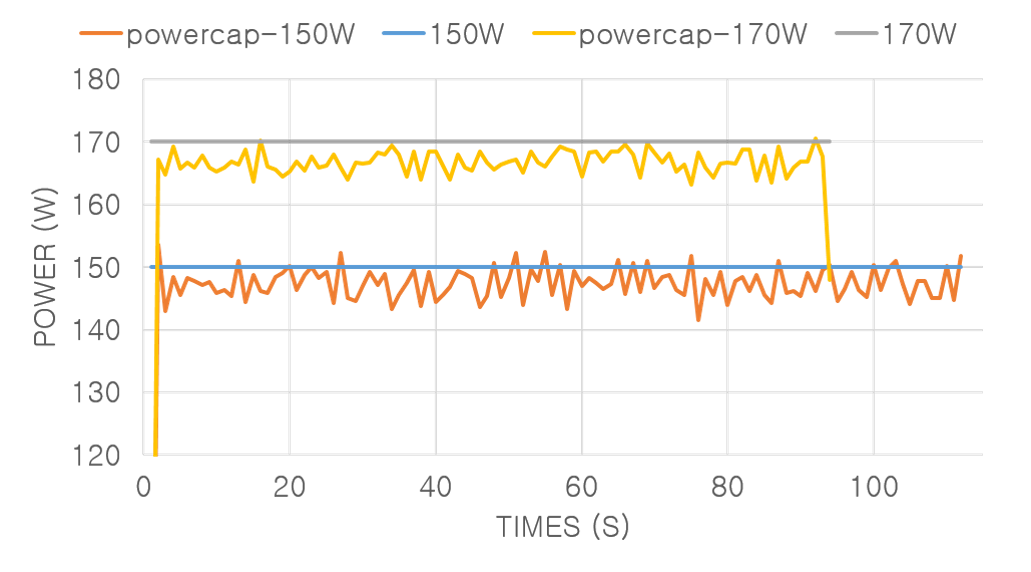
위 그림에서처럼 170 W의 전력 캡핑을 적용하면 평균 전력은 165.41 W 로 전력 모델을 2.77 % 오차 이내로 전력 소모를 조절할 수 있다. 1초 단위로 평균 전력을 측정하였을 때, 샘플링 된 전체 데이터 중 2.12 %가 지정된 상한 전력을 초과하는 것으로 나타났다. 하지만 초과된 전력의 최대값은 상한 값의 0.29 %로 전력 상한 제한 기능을 적절하게 제공될 수 있음을 보였다.
전력 제한을 150 W로 지정하였을 때는 전력 상한을 초과하는 경우가 전체의 16.07 %이며, 최대 값도 2.33 %로 더 커진다. 그러나 측정된 평균 전력은 146.67 W로 전력 모델은 필요한 유휴 삽입 비율을 적절하게 계산하고 있다고 평가할 수 있다. 만약 150 W와 같은 상황에서 더 엄격한 전력 상한 제한을 구현하고자 한다면, 목표 전력을 좀 더 낮게 잡도록 여유를 주는 것과 모듈의 동작 주기를 짧게 하는 것으로 전력이 초과되는 문제를 해결할 수 있다.
연구 결과물
- 공개 소프트웨어
- Github: iPoCap
- 시연 동영상
- Youtube: Linux with Power Capping