영구 메모리 연구
영구 메모리의 내구성 및 수명 관리 기술 연구 (Tonic)
연구 배경
최초로 상용화된 영구 메모리(Persistent Memory : PM)인 Intel사의 Optane Persistent Memory Module(DCPMM)의 수명 관리 기술 연구에 필요한 배경 지식 함양을 위해 조사한 결과이다. 이를 통해 영구 메모리의 하드웨어 구조를 통해 수명 관리 필요성을 설명하고, 기존의 NAND Flash 기반의 저장 장치를 위한 수명 관리 기술과 영구 메모리를 위한 수명 관리 기술이 어떤 차이를 가져야하는지 소개한다.
메모리의 내구성(Endurance) 와 수명(Lifetime)
메모리는 정확한 위치에 데이터를 저장하고, 저장된 데이터를 정확하게 읽어올 수 있으며, 데이터를 깨끗이 삭제할 수 있어야 한다. 이러한 기능을 일정 기간 동안 온전하게 발휘할 확률을 신뢰성(Reliability)이라고 한다. 신뢰성을 높이기 위해서 메모리 셀은 높은 내구성(Endurance)과 보존성(Retention)을 제공하고, 교란(Disturbance)과 간섭(Interference)을 최소화 할 수 있어야한다. 메모리 셀의 무결성은 무한히 보장되지 않으며 메모리 셀의 수명은 데이터를 저장하고(program), 지우기(erase)를 반복하다 보면 저장한 데이터의 무결성을 보장할 수 없게 된다. NAND flash 메모리는 in-place update가 불가능하기 때문에 쓰기가 일어난 이후에는 반드시 데이터를 소거하는 작업을 거쳐야 셀에 새로운 데이터를 저장할 수 있다. 이 두가지 동작을 한번 반복하는 것을 P/E cycle 이라고 한다. NAND flash 메모리 셀에서 내구성이란 메모리 셀이 몇 회의 P/E cycle을 견딜 수 있는가를 의미한다. 반면 보존성은 읽기 쓰기 동작과는 무관하게 저장된 데이터를 저장할 수 있는 기간을 의미한다. DRAM의 경우, 전원이 꺼지면 데이터가 사라지므로 데이터를 오랜 시간 저장하는 특성이 필요하지는 않지만, 전원이 공급되고 있는 동안에는 Refresh time(64ms) 동안은 캐패시터에 전하가 유지되어야 데이터의 무결성을 제공할 수 있다. DRAM은 데이터를 유지하기 위해 refresh를 통해 캐패시터에 전하를 재 충전 한다.
PMem의 메모리 계층 구조와 write amplification
그림 1는 PMem을 포함하는 메모리 계층구조와 application에서 저장한 데이터가 실제 미디어에 쓰여지는 과정을 묘사한 그림이다. PMem은 byte-addressable memory로 DRAM을 사용 하는것과 동일하게 STORE instruction을 통해 데이터를 PMem에 직접 쓸 수 있다.하지만 STORE 된 데이터는 미디어에 즉시 쓰이지 않고 cache에 쓰여졌다가, cache eviction 에 의해 결국에는 메모리에 쓰여진다. application이 해당 데이터가 미디어에 physically saved 된 것을 보장받으려면 clflush (Cache line flush), 혹은 clwb (Cache line write back) 등의 instruction을 통해 data를 명시적으로 flush 하 거나, movnti, movntq, etc. 와 같은 non-temporal store instruction으로 cache를 bypass 하여 메모리에 직접 써야한다. 그림 1에서 (1) 어떤 core가 flush instruction issue 하면, 해당 어드레스의 데이터가 L1∼L3 에 캐시되어 있고, dirty 상태일 경우, (2) iMC (integrated Memory Controller) 에 있는 WPQ (Write Pending Queue)로 내려 보낸다. WPQ 는 프로세서 내부에 있지만, asynchronous DRAM refresh (ADR) domain에 속해있다. PMem 을 포함하는 시스템에 서는 ADR domain에 도달한 데이터는 Power-fail 에서도 안전하게 미디어에 저장 되는 것이 보장된다. (3) iMC는 DDR-T interface를 통해 PMem에 데이터 를 보낸다. (4) PMem 내부의 컨트롤러는 write-combining buffer를 가지고 있다. 이 버퍼는 CPU가 보낸 64-byte granularity의 requests를 256-byte requests로 translate 하는 데 활용된다. (5) 최종적으로 미디어 쓰기를 위해 address indirection table (AIT)을 참조하여 데이터가 저장될 위치를 찾는다. AIT는 wear-leveling, bad-block 관리를 위해 메모 리 address를 internal address로 translate 하기 위해 사용 한다.
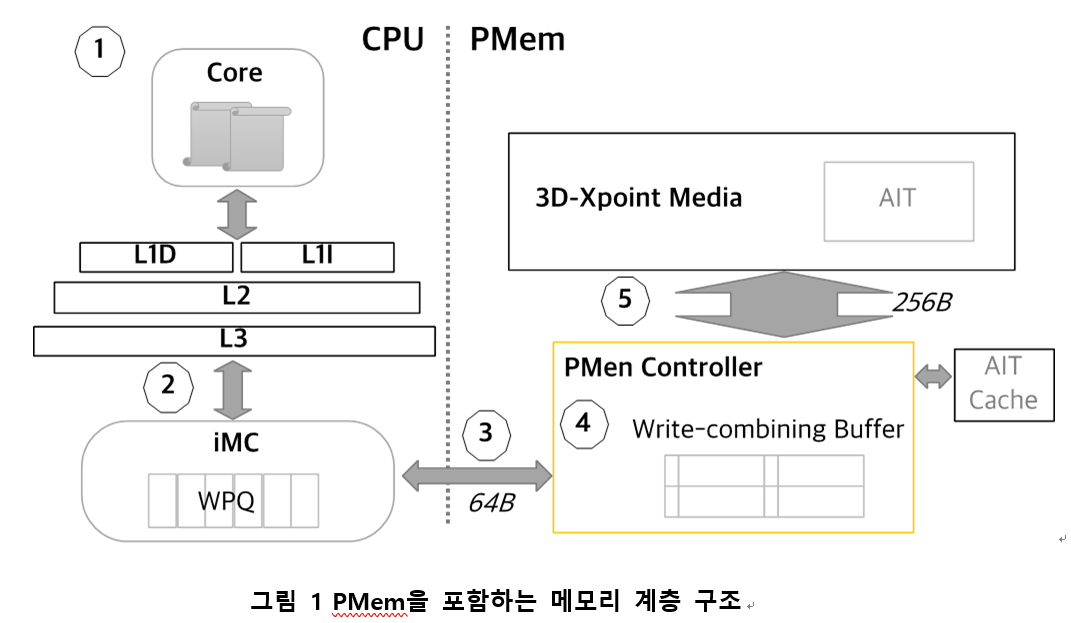
PMem 계층 구조에서 write requests는 각 메모리 계층 마다 증폭되거나 merge될 가능성이 있다. (1) application 이 cache align 되지 않은 data structure를 사용할 경우, 더 많은 flush가 issue될 수 있다. (2) cache eviction에 의해 아직 flush 하지 않은 데이터가 flush 될 수 있다. (4) write- combining buffer에서는 small write 들은 read-modify-write 로 바뀌면서 write amplification이 발생할 수 있다. 반대로, write-combining buffer 매우 짧은 시간 안에 동일한 위치에 반복된 write requests를 merge 하기도 한다. PMem-aware application의 제어되지 않은 메모리 사용 은 PMem hierarchy 에서 발생할 수 있는 write amplification 을 크게 키울 가능성을 가지고 있다. PM-aware application 은 PMem을 byte-addressable non-volatile memory로 인식 하고 memory space 를 직접 mapping 하여 사용한다. block storage 와는 달리 4KB 단위로 데이터를 packing 하는 과 정이 불필요하므로 시스템 소프트웨어의 관여가 제거된다. 따라서 어플리케이션 개발자는 스스로 write amplification 을 유의하여 어플리케이션을 개발해야한다.
성능 실험
실험 환경
application은 어떤 data structure를 사용하느냐에 따라 issue 하는 flush 횟수가 차이날 수 있다. 동일한 역할을 수행하기 위한 다양한 data structure들을 비교하기 위해 Recipe benchmark를 활용하였다. Recipe benchmark는 Yahoo! Cloud Serving Benchmark (YCSB) 워크로드를 활 용하여 Persistent-memory index 알고리즘을 비교하기 위 해 구현되었다.
Index 알고리즘 비교
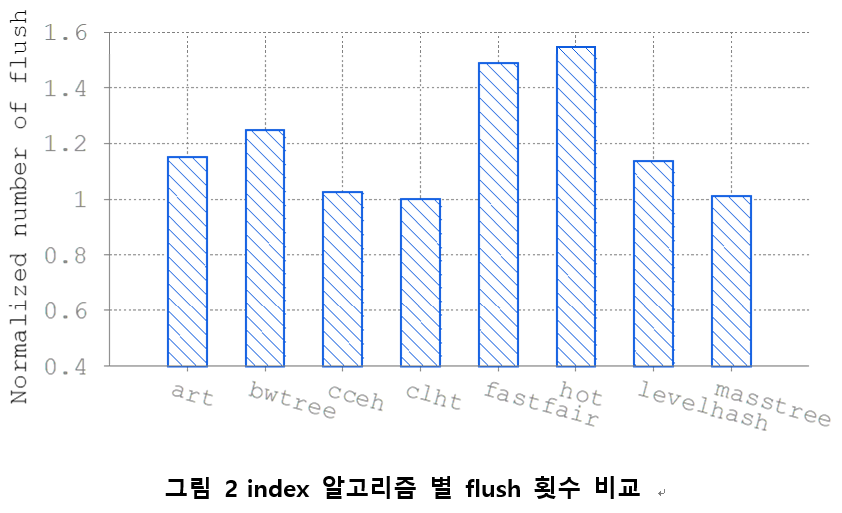
그림 2는 Recipe benchmark에서 insert operation만 수행하는 워크로드에서 측정된 flush 수를 clht 알고리즘을 기준으로 normalized 한 그래프이다. flush 수가 가장 적은 알고리즘은 clht이다. 이 알고리즘 은 cache-friendly hash table 로 버킷의 크기를 캐시 라인 크기에 맞추도록 고안된 알고리즘이다. 가장 flush 수가 많 은 알고리즘은 hot으로 flush operation을 54.8% 더 발생시 킨다. Recipe의 저자들이 수행한 실험에서 insert operation 별 LLC miss 횟수도 알고리즘 별로 큰 차이를 보였다. insert operation 당 flush와 LLC miss가 커질 수록 사용자는 하나의 insert operation을 위해 더 많은 수명 비용을 지불 해야한다는 것을 의미한다.
PMem 내부 쓰기 병합 실험
LLC miss 나 flush를 통해 WPQ로 보내진 write requests는 processor의 uncore performance counter에서 iMC 의 WPQ insert counter 값을 통해 확인할 수 있다. 우리 는 WPQ insert 카운터 모니터링을 위해 PCM tool을 활용하였다. WPQ에서 PMem contoroller로 보내진 이후의 request는 ipmctl tool을 활용하여 측정 할 수 있다. 특정 영역에 쓰기가 반복되는 경우에 request가 merge 되는 것이 가능한지 확인하기 위해 single thread로 fixed size range에 sequential write를 반복하는 실험을 수행하고, WPQ insert와 media write를 측정하였다. flush instruction으로는 clflush를 사용하였다.
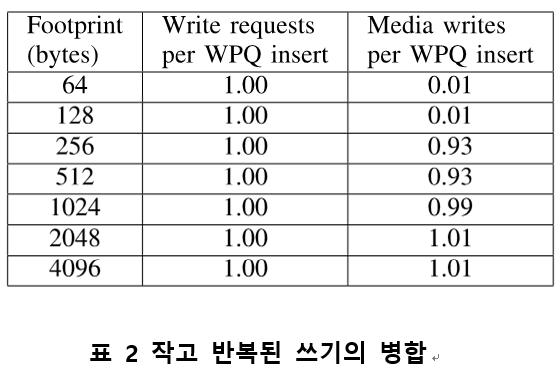
표 2는 WPQ insert 당 PMem으로 보내진 request수와 실제 미디어에 쓰여진 횟수를 footprint 크기 별로 비교한 것이다. WPQ insert와 PMem write requests 값은 거의 같았다. 이는 WPQ에서는 쓰기 증 폭이나 병합이 일어나지 않는 다는 것을 의미한다. 하지만 256 bytes 보다 작은 영역에 쓰기를 반복한 경우 request 의 대부분이 PMem controller 에서 흡수되어 Media write로 변하지 않았다. 이 결과를 통해 flush 수를 줄이기 위한 lazy flush 기법은 큰 효과가 없을 것으로 예측 할 수 있다.
PMem 컨트롤러 내 write amplification 실험
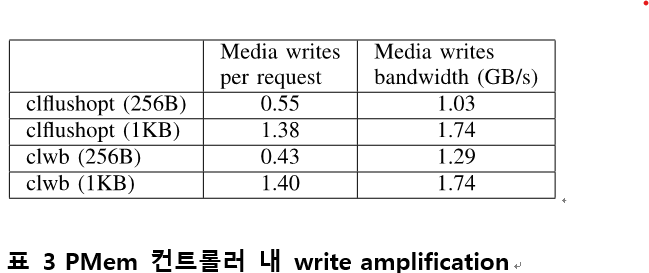
표 3은 멀티 쓰레드 어플리케이션에서 쓰레드별 footprint와 flush instruction 종류에 따라 write amplification과 성능이 달라지는 것을 비교한 table이다. 이 실험에서는 28 개의 쓰레드가 physical 코어 마다 하나씩 할당되어 각각 256B혹은 1KB 영역을 할당 받고, sequential write를 반복하도록 하였다. 각 쓰레드가 쓰는 영역이 256B 일 때는 merge되던 write가 사용하는 영역이 커지면 amplification 이 커진다. write amplification만 고려한다면, 특정 영역에 대한 update를 완료하고 다음 영역으로 넘어가는 방식으로 구현하는 것이 유리하다. 다만, 더 넓은 영역을 사용할 때 bandwidth가 더 큰 경향을 보였으므로 성능과 수명간의 trade-off가 발생할 수 있다. 256B 영역에 반복해서 쓰는 경우 사용하는 flush instruction 에 따라 Write amplification과 bandwidth가 유의미한 수준으로 차이 나는 것을 확인할 수 있다. 이를 통해 워크로드에 따라 최적의 flush instruction이 다를 수 있음 을 예측할 수 있다.
결론
PMem을 byte-addressable non-volatile memory로 사용 할 때는 디바이스의 수명 비용을 고려하여 어플리케이션을 구현해야한다. PMem의 수명이 쓰기 횟수에 비례하여 감 소하며, 다른 어떤 non-volatile memory 보다 빠르게 쓸 수 있으며, 어플리케이션 장치 사용을 제어할 수 있는 소프트웨어 레이어가 존재하지 않기 때문이다. PMem이 포함된 메모리 계층 구조를 분 석하고, 각 계층에서 발생할 수 있는 write amplification의 가능성을 소개하였다. 또한 실험을 통해 응용이 사용하는 데이터 스트럭쳐와 write pattern에 따라 write amplification 수준이 크게 달라질 수 있음을 보였다. 우리는 이 결과에서 얻은 insight를 토대로 향후 PMem application 개발자들이 응용의 수명 비용을 수치화 하고 수명 낭비 문제를 해결 하기 위해서 어떤 노력을 기울여야 하는지 가이드 하는 방안을 제시하기 위한 연구를 지속할 예정이다.
연구 결과물
- 논문
- 공개 소프트웨어
- Github: RECIPE with Tonic
영구 메모리의 메모리화 연구 (AliusM)
연구 배경
중앙처리 장치(Central Processing Unit, CPU), 주 기억장치(main memory), 보조 기억장치(secondary memory), 입출력 장치(input/output devices)는 컴퓨터 시스템의 기본 구성 요소이다. 주 기억장치로 많이 사용되는 DRAM(Dynamic Random Access Memory)은 컴퓨터 시스템 성능에 많은 영향을 주고 있다. 시스템 메모리의 용량이 증가할수록 성능 개선에 도움이 된다. 최근의 컴퓨터 시스템은 더 많은 시스템 메모리를 사용할 수 있도록 지원하고 있다. 주 기억장치의 용량은 하나의 메모리 슬롯에 설치 가능한 메모리 용량에 제한을 받기 때문에 설치 슬롯이 많을수록 시스템 메모리 확장에 유리하다. 메모리 슬롯 확장에 유리한 누마(Non-Uniform Memory Access, NUMA) 구조는 고성능 시스템에서 많이 활용되고 있다. 누마 구조에서는 프로세스(process)가 구동 중인 코어(core)와 접근하는 메모리간의 거리에 따라 접근 지연시간의 차이가 있으며 같은 CPU 소켓에 연결된 메모리에 접근하는 것이 다른 CPU 소켓에 연결된 메모리에 접근하는 것보다 빠른 특징이 있다.
인텔사는 메모리 버스에 설치하여 사용할 수 있는 인텔의 옵테인 영구메모리(Persistent Memory, PMem)를 개발, 보급하고 있다. 옵테인 영구메모리는 비휘발성 특성을 갖고 있으며 집적도가 높아 DRAM보다 대용량으로 제작이 가능하다. 메모리 버스에 설치하여 사용하기 때문에 DRAM과 같은 방식으로 사용이 가능하다. 그러나 DRAM보다는 긴 접근 지연시간이 필요하다. PMem은 앱다이렉트 모드(app-direct mode) 또는 메모리 모드(memory mode)로 사용한다. 앱다이렉트 모드는 옵테인 영구메모리를 빠른 파일 저장장치로 사용할 수 있도록 지원한다. 메모리 모드로 설정할 경우 옵테인 영구메모리는 시스템 메모리가 된다. 이때 PMem의 긴 접근 지연시간으로 인한 성능 손실 문제를 보완하기 위하여 DRAM을 PMem의 캐시로 사용한다. 이 때 DRAM은 PMem의 캐시로 사용되기 때문에 시스템 메모리 크기에 포함되지 않는다. DRAM은 PMem의 직접 사상 캐시 (direct-mapped cache)로 동작하기 때문에 PMem의 서로 다른 영역에서 DRAM의 동일 지역을 빈번하게 사상(mapping)할 경우 캐시 적중률(cache hit ratio)이 낮아져 성능이 떨어지는 문제가 있다.
앱다이렉트 모드에서 리눅스의 KMEM_DAX 옵션을 사용하면 옵테인 영구메모리를 시스템 메모리로 사용할 수 있다. KMEM_DAX 옵션에서는 영구메모리를 사용하는 3가지 방법을 제공한다.
▪MEMKIND_DAX_KMEM
- 코어에서 가장 가까운 영구메모리 노드만 사용한다. 해당 영구메모리에 여유공간이 없으면 스왑(swap) 공간을 활용하다가 더 이상 활용할 스왑공간이 없을 경우 메모리 부족 상태가 된다.
▪MEMKIND_DAX_KMEM_ALL
- 영구메모리만 사용한다. 영구메모리 노드에서 더 이상 할당 받을 수 없을 경우 멀리 있는 영구메모리 노드에서 할당받고, 더 이상 스왑 공간도 사용할 수 없게 되었을 경우 메모리 부족 상태가 된다.
▪MEMKIND_DAX_KMEM_PREFERRED
- 코어에서 가까운 영구메모리 부터 사용을 하고, 가장 가까운 DRAM, 멀리 있는 영구 메모리, 멀리 있는 DRAM 순으로 사용하고 스왑 공간을 더 이상 사용할 수 없을 경우 메모리 부족 상태가 된다.
누마 구조의 시스템에서 누마 지역성(NUMA-locality)을 고려하여 사용하면 성능을 개선할 수 있다. KMEM_DAX 옵션에서 지원하는 영구메모리 사용 방법은 누마 지역성을 DRAM만큼 고려하지 못하고 있으며, 사용할 PMem 노드를 사용자가 지정해야 한다. MEMKIND_DAX_KMEM과 MEMKIND_DAX_KMEM_ALL을 적용하면 사용 가능한 DRAM 자원이 있어도 메모리 부족 상태가 되는 문제가 있다. MEMKIND_DAX_KMEM_PREFERRED는 모든 시스템 메모리를 사용 하지만 DRAM보다 성능이 낮은 영구 메모리를 먼저 사용하는 문제가 있다. DRAM 기반의 누마 시스템에서 자동으로 균형을 이루는 기법(automatic numa balancing)이 PMem에는 적용할 수 없는 문제가 있다. 누마시스템에서 DRAM보다 저렴한 비용의 PMem을 시스템 메모리로 사용하기 위해서는 많은 연구가 필요하다.
연구 내용
영구메모리 사용 시스템은 중앙 처리장치에 내장된 메모리 제어기(integrated Memory Controller, iMC)를 기준으로 누마 노드를 구성(sub-NUMA Cluster, sNC)할 수 있으며 물리적인 소켓을 기준으로 구성된 누마 노드의 지역성을 고려하여 사용할 때보다 높은 성능을 얻을 수 있다. 영구메모리 경우, 물리적인 소켓을 기준으로 영구메모리를 모듈단위로 하나씩 건너뛰며(interleaving) 사용할 때 가장 높은 성능을 얻을 수 있으며, 원격 DRAM을 접근할 때와 비슷한 성능을 얻을 수 있다.
누마 환경에서 영구메모리를 시스템 메모리로 사용할 때, DRAM과 영구메모리를 시스템 메모리로 사용할 수 있다면, 메모리 모드일 때 보다 큰 용량의 시스템 메모리 사용이 가능하다. KMEM_DAX 옵션과 다르게 높은 성능의 DRAM을 먼저 사용함으로써 DRAM만 사용하는 시스템과 비슷한 성능을 얻을 수 있다. 그리고 영구메모리를 모듈 단위로 하나씩 건너뛰며 사용함으로써 메모리 모드일 때보다 높은 성능을 얻는다. 본 연구에서는 영구메모리와 DRAM 모두를 시스템 메모리로 사용할 수 있는 기능을 설계하고 리눅스 커널 5.4에서 구현하였다.
DRAM을 시스템 메모리로 사용하기 위해서는 앱다이렉트 모드로 부팅해야 한다. 부팅과정에서 전달받는 하드웨어 정보로 DRAM과 PMem을 구분하였으며 PMem 관리를 위해 memblock 구조체와 memblock_add_region 함수를 사용하였다. PMem 영역에서 페이지를 할당할 수 있도록 alloc_pages_current 함수를 수정하였다.
성능 실험
aliusM 기능으로 DRAM과 PMem으로 대규모 페이지 할당이 가능한지와 큰 메모리를 요구하는 과학계산 응용으로 성능 실험을 하였다. 실험 환경은 2개의 CPU 소켓으로 구성된 56코어 시스템이며, 하나의 CPU 소켓에 2개의 메모리 제어기가 있으며 2개의 누마 클러스터로 구분된 시스템이다. 하나의 메모리 제어기에 96G DRAM과 768GB PMem이 연결되어 있다. DRAM은 총 386GB, PMem은 총 3,072GB이며, 전체적으로 3,456GB 메모리를 제공한다.
먼저, vmalloc을 사용하여 메모리 할당 능력과 수행시간에 대해서 메모리 모드와 aliusM를 실험, 비교하였다. 메모리 모드 경우, DRAM를 캐시로 사용하기 때문에 페이지 할당은 모두 PMem에서 이루어지기 때문에 aliusM보다 수행시간이 길다. 3000GB 할당 요청의 경우 메모리 모드에서는 커널이 점유하고 있는 공간을 제외하고 남는 크기가 3000GB가 되지 않기 때문에 할당이 불가능 하다. 반면에, aliusM은 DRAM에서 할당하기 떄문에 수행시간에서 많은 차이를 보인다. 그리고 aliusM이 PMem을 사용할 때 최고의 성능을 얻을 수 있도록 인터리빙하기 때문에 메모리 모드 보다 높은 성능을 얻을 수 있다. aliusM은 DRAM과 DCPMM을 합한 크기가 전체 시스템 메모리 크기가 되기 때문에 3000GB 할당이 가능하다. 2000GB에 비해 긴 시간이 소요된 이유는 원격 소켓에 있는 PMem를 할당하기 떄문이다.
대규모 메모리를 요구하는 과학계산 응용인 슈퍼파이 응용의 수행시간을 실험하였다. 시험 시스템에 장착된 DRAM 크기 (총 386GB) 이내의 페이지를 할당받고 응용이 수행하는 조건에서 성능 비교이다. aliusM 기능이 메모리 모드보다 60% 성능이 좋다.
연구 결과물
- 논문
- 공개 소프트웨어
- Github: AliusM
- 시연 동영상