네트워크 입출력 성능 개선
연구 배경
멀티코어 및 매니코어 시스템에서 응용 프로세스가 수행되는 코어를 결정하는 방법은 다양하다. 일반적으로 운영체제의 스케줄러가 코어들의 부하상태를 고려하여 결정한다. 하지만 데이터 입/출력을 위한 프로세스는 커널 수준의 처리가 동반되기 때문에 인터럽트가 수행되는 코어와 응용 프로세스가 수행되는 코어의 관계를 고려해야 효율적인 입/출력이 가능하다. 만약 인터럽트와 응용 프로세스가 하나의 코어에서 수행되는 경우 데이터 지역성이 향상되기 때문에 더 나은 입/출력 성능을 기대할 수 있지만 잦은 문맥 교환에 따른 부작용이 발생할 수 있다. 반면 인터럽트와 응용 프로세스가 서로 다른 코어에서 수행되는 경우 문맥 교환에 따른 부작용은 제거할 수 있지만 인터럽트와 응용 프로세스가 사용하는 데이터가 서로 다른 곳에 위치하기 때문에 데이터 접근에 따른 부작용이 발생할 수 있다. 코어 친화도(Core Affinity) 기법은 멀티코어 및 매니코어 시스템에서 응용 프로세스가 수행되는 코어를 결정하는 기법을 의미한다. 코어 친화도 기법을 이용해 인터럽트 또는 응용 프로세스가 수행될 코어 또는 코어 집합을 지정할 수 있다. 멀티코어 및 매니코어 시스템은 일반적으로 다수의 코어가 최하위 레벨 캐쉬 메모리를 공유하는 특성을 갖는다. 만약 인터럽트와 응용 프로세스가 최하위 레벨 캐쉬 메모리를 공유하는 서로 다른 코어에서 수행된다면 데이터 지역성을 제공하면서 문맥 교환에 따른 부작용을 제거할 수 있으며 더 높은 입/출력 성능을 기대할 수 있다. 따라서 본 연구에서는 매니코어 시스템을 이용해 네트워크 I/O 관점에서 응용 수준의 성능 향상을 보장하기 위한 코어 친화도에 대해 연구하였다.
연구 내용
응용 프로세스 수준의 코어 친화도
실험 환경
- CPU : 2-way Intel Xeon E5-2680V2 (Ivy-Bridge, Deca(10)-Core, 2.80Ghz) / Total 20-Core (40-Core on HT Enable)
- RAM : 64GB
- Disk : Intel SSD 530S 240GB
- Network : Chelsio T580-LP-CR 40GigE
- Operating System : CentOS 7.0 (Kernel Version 3.10.0-123, RHEL 7 Base)
실험 방법
네트워크 I/O의 성능을 위한 코어 친화도 기법은 연구 배경에서 설명한 바와 같이 인터럽트 처리 코어와 응용 프로세스 처리 코어를 함께 고려해야 한다. 따라서 본 연구에서는 두 가지 관점의 코어 친화도에 대해 실험을 진행하고 분석하였다.
- 프로세스-코어 친화도
- 인터럽트-코어 친화도
프로세스-코어 친화도의 경우 네트워크 I/O의 인터럽트를 처리하는 코어를 기준으로 설정한다. 따라서 그림 1과 같이 인터럽트 처리 코어와 같은 코어(NS), 인터럽트 처리 코어와 최하위 캐쉬 메모리를 공유하는 코어(NC) 그리고 인터럽트 처리 코어와 하드웨어 자원을 공유하지 않는 코어(NZ, 다른 프로세서 패키지)와 같이 설정할 수 있다. 멀티 프로세서 패키지를 사용하는 머신의 경우 인터럽트를 처리하는 코어에 따라 I/O 거리에 따른 I/O 성능 차이가 발생할 수 있다. 따라서 인터럽트-코어 친화도는 그림 2와 같이 근접한 프로세서 패키지에서 처리하게 하거나 I/O 버스가 연결되지 않은 다른 프로세서 패키지에서 처리하게 할 수 있다. 본 연구에서는 프로세스-코어 친화도와 인터럽트-코어 친화도가 네트워크 I/O 성능에 미치는 영향에 대해 분석하기 위해 그림 1과 그림 2의 코어 친화도 설정과 ttcp 마이크로-벤치마크를 이용해 실험을 진행 하였다.
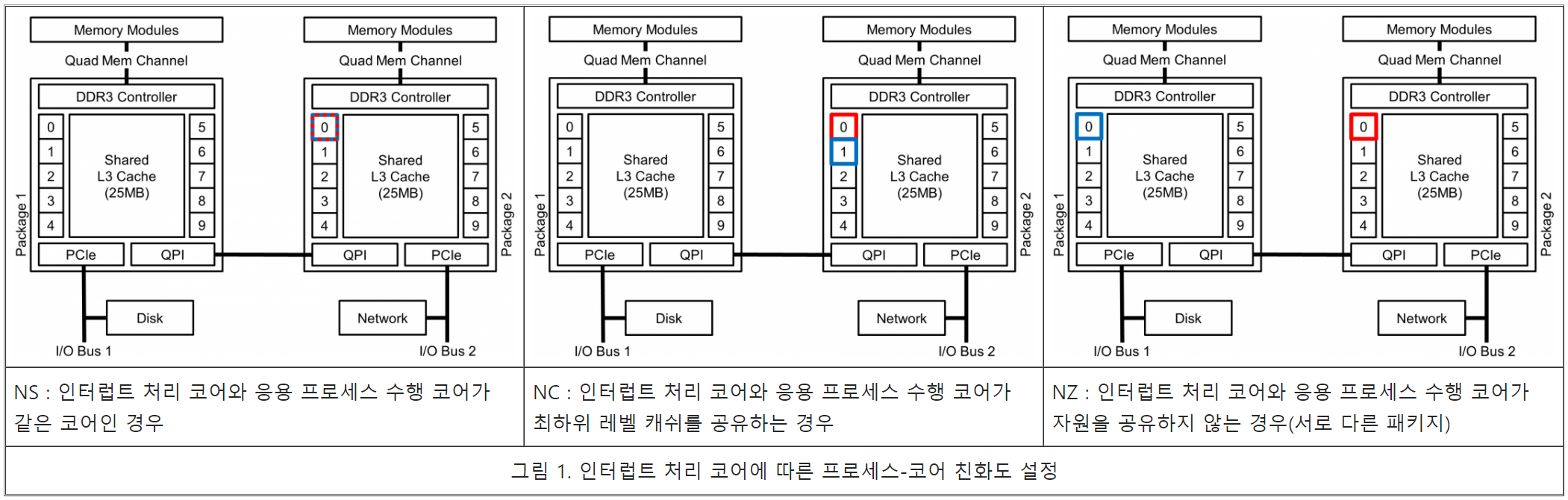
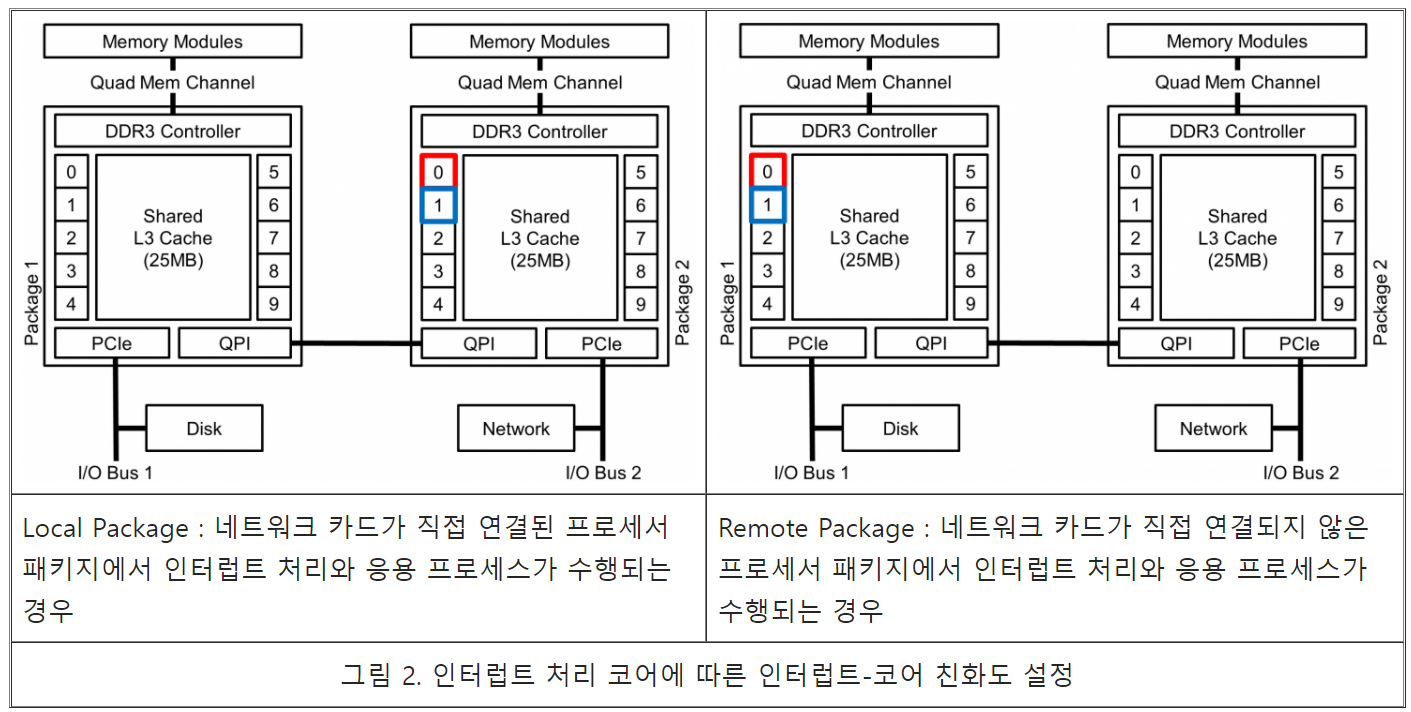
코어 친화도의 영향
그림 3과 그림 4는 각각 프로세스-코어 친화도에 따른 네트워크 I/O 성능과 인터럽트-코어 친화도에 따른 네트워크 I/O 성능을 나타낸다.
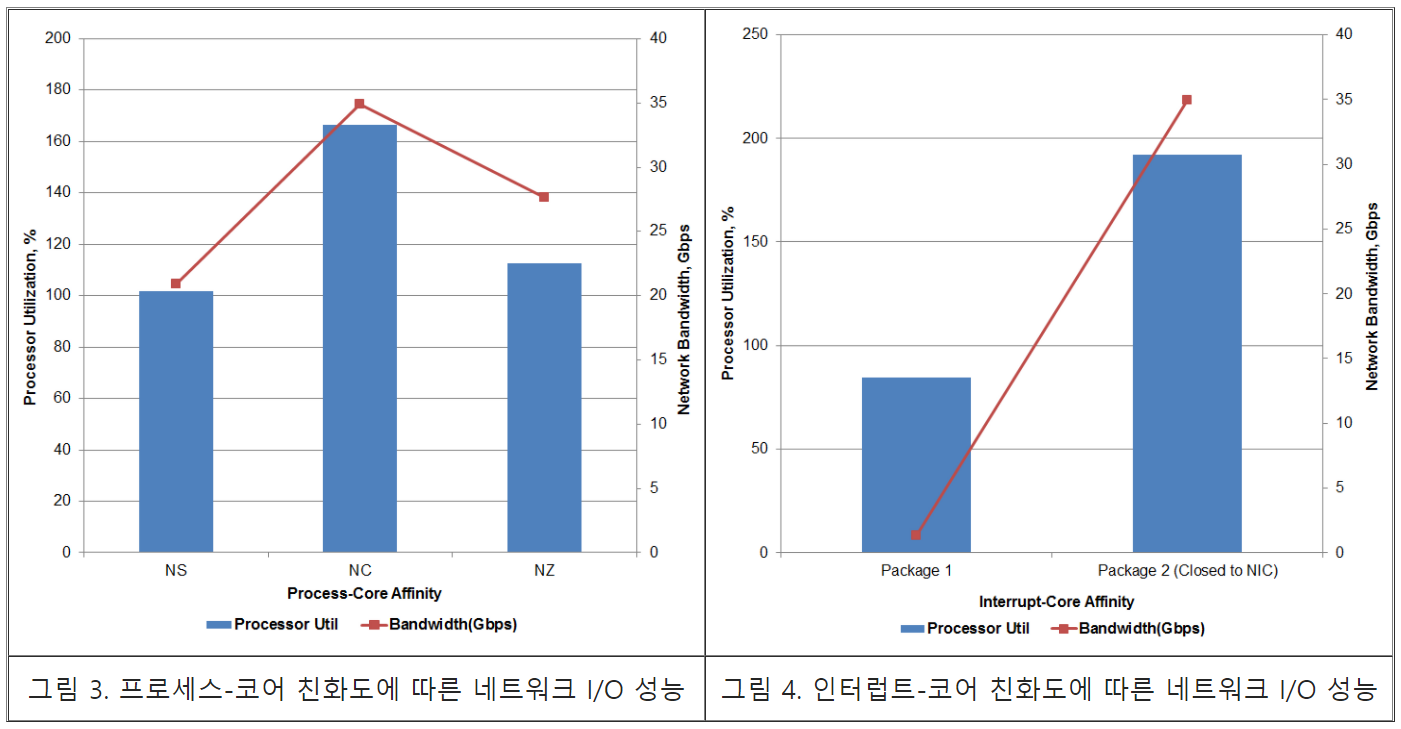
먼저 프로세스-코어 친화도의 경우 NC로 설정 하였을 때 가장 높은 성능을 보이고 있다. 그 원인으로는 데이터 지역성과 응용 프로세스 병렬성을 모두 보장해 주었기 때문인 것으로 예상된다. 반면 NS는 가장 낮은 성능을 보이고 있는데 역시 연구 배경에서 언급한 바와 같이 문맥 교환에 따른 오버헤드에 의한 것으로 예상된다. NZ는 NC에 비해 20% 정도 낮은 성능을 보이며 NS에 비해 30% 정도 높은 성능을 보이고 있는데 NZ의 결과를 통해 네트워크 I/O 성능을 위해서는 인터럽트 처리와 응용 프로세스의 병렬성을 우선하되 가능하다면 데이터 지역성을 함께 보장해 주어야 할 것으로 판단된다.
인터럽트-코어 친화도의 경우 NIC과 가까운 프로세서 패키지에서 인터럽트를 처리 하였을 때 더 나은 성능을 보이고 있는데 거리가 먼 프로세서 패키지(Package 1)의 경우 정상적인 결과로 판단하기 어려워(1.3Gbps, 40Gbps 속도의 3.3%) 계속해서 확인을 진행할 예정이다.
시스템 호출 수준의 코어 친화도
전체 디자인
시스템 호출 수준의 네트워크 입출력 성능 개선은 응용 수준에서 socket() 이 호출될 때마다 Syscall Thread라고 불리는 독립적인 쓰레드를 생성하고 이 쓰레드가 네트워크 관련 시스템 호출을 전담하도록 하여 시스템 호출이 수행되는 코어와 응용 쓰레드가 수행되는 코어를 분리하고 이를 통해 사용자-커널 문맥 교환 과정에서 발생하는 캐시 오염을 줄인다. 또한, Syscall Thread를 네트워크 디바이스에 가까운 프로세서 패키지에서 수행되도록 하여 패키지 간 캐시 일관성 오버헤드를 감소시킨다. 시스템 호출 수준의 네트워크 입출력 성능 개선은 시스템 호출 라이브러리를 재정의 하여 기존의 커널이나 응용을 변경하지 않고 사용할 수 있도록 구현하였다.
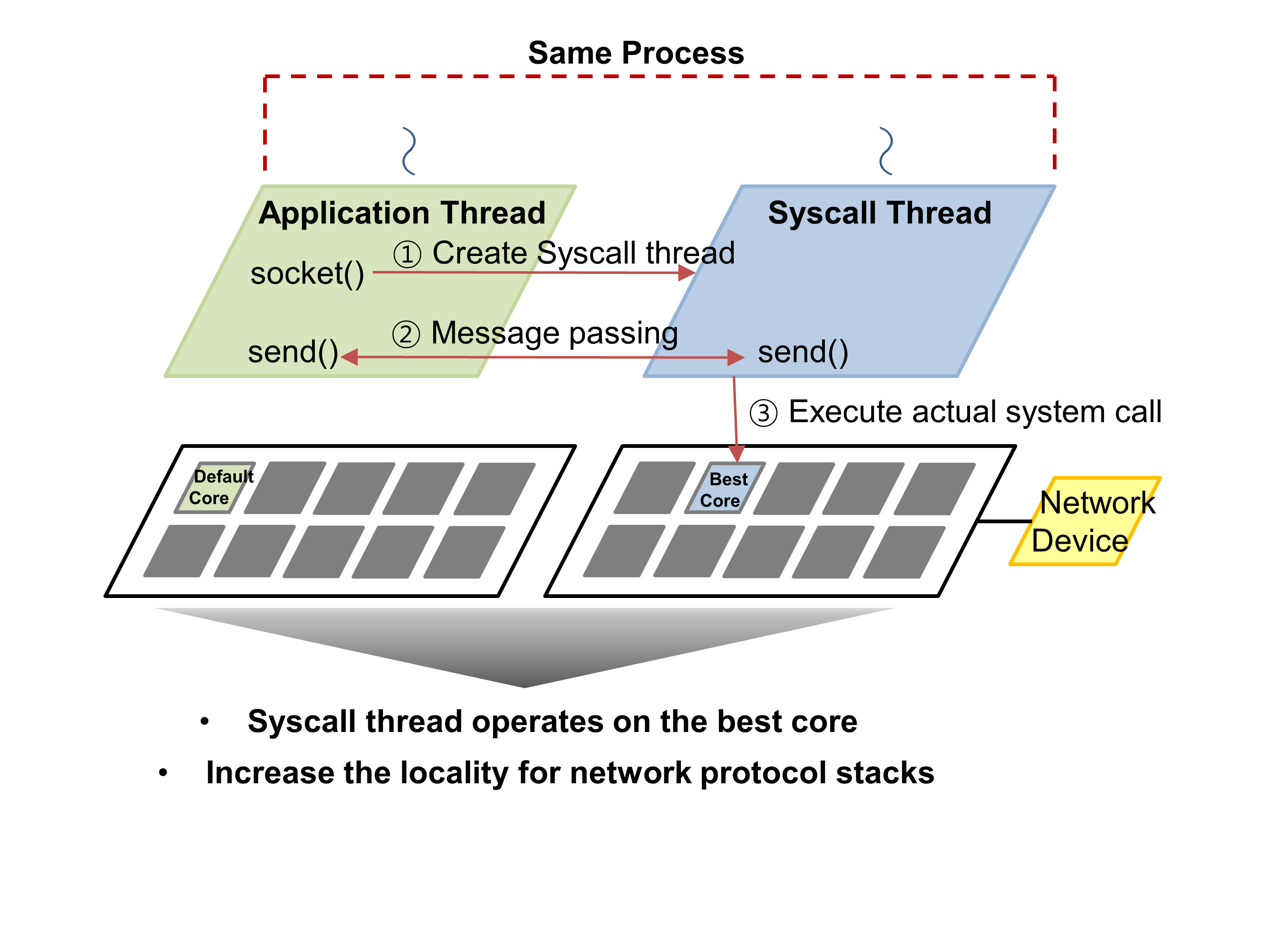
실험 환경
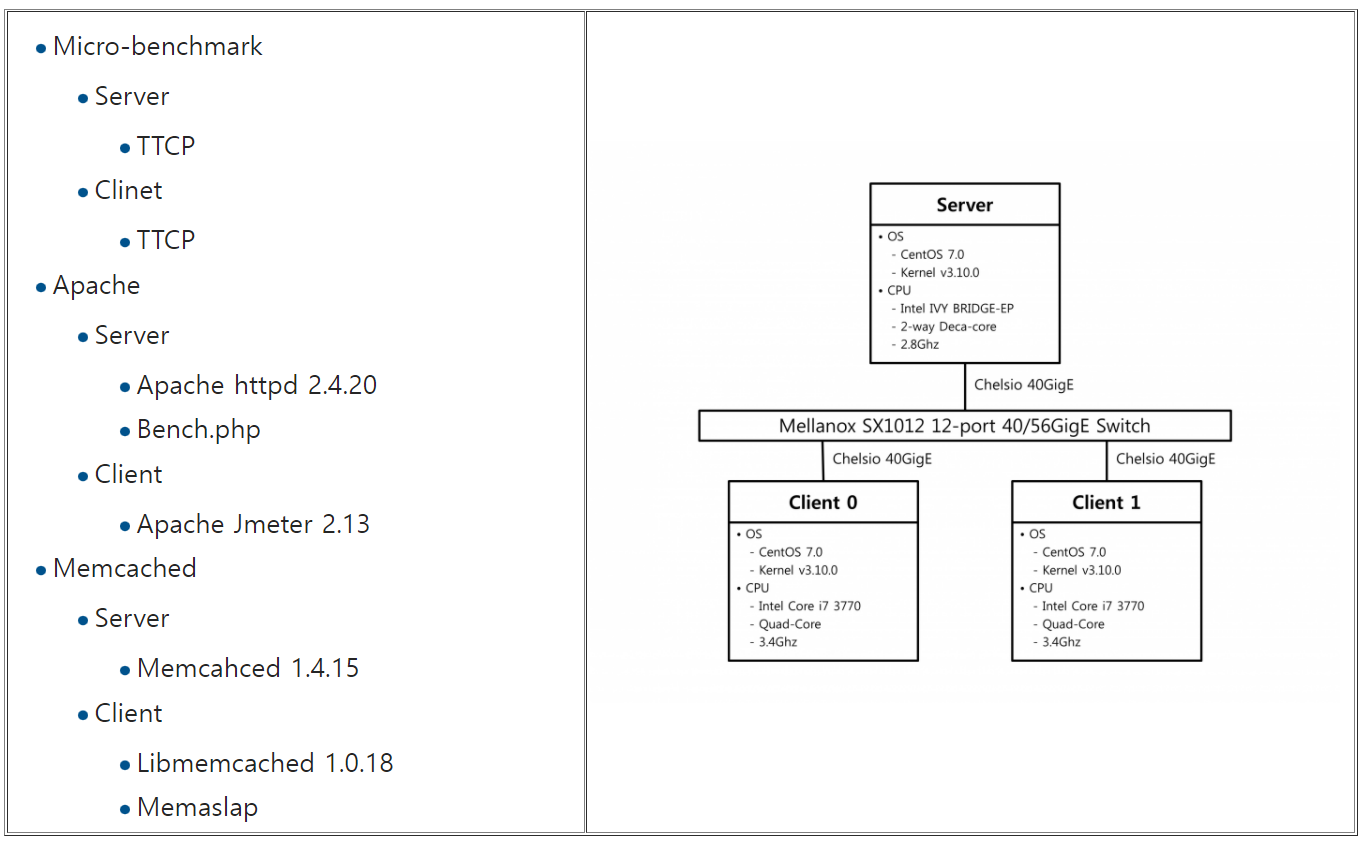
시스템 호출 수준의 네트워크 입출력 성능 영향
제안된 구조는 응용과 시스템 호출 문맥을 분리하고 시스템 호출 문맥이 수행되는 코어를 네트워크 디바이스가 연결된 프로세서 패키지로 고정하여 문맥 전환 시 발생하는 오버헤드를 줄이고, 프로세서 패키지 간 캐시 일관성 오버헤드를 줄이고자 한다. 그러나, 제안된 디자인은 응용 쓰레드와 Syscall Thread 간의 메시지 통신으로 인한 오버헤드가 존재할 수 있다. 이러한 부작용의 영향을 분석하기 위해 마이크로 벤치마크를 통해 네트워크 대역폭과 지연시간을 측정해보았다. 마이크로 벤치마크는 시스템 호출을 집중적으로 사용하기 때문에 실제 응용 동작 패턴과 비교했을 때 많은 메시지 통신이 발생된다. 따라서 마이크로 벤치마크를 이용한 성능 실험에서 기존의 리눅스와 비교하여 성능 향상을 보이기보다는 비슷한 수준의 성능을 기대하여 메시지 통신으로 이한 부작용을 점검한다.
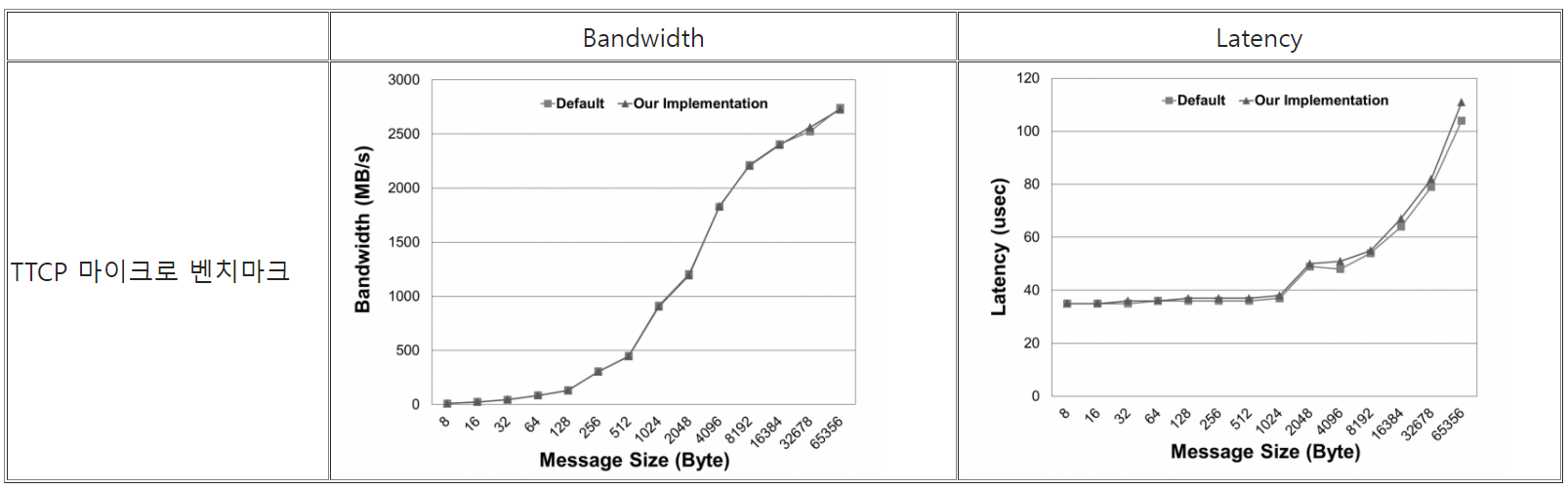
마이크로 벤치마크를 통한 부작용 점검에서 성능 차이가 기존 리눅스와 비교하여 최대 약 4%의 성능 저하를 보였다. 이를 통해 부작용이 미미하다고 판단할 수 있다.
아래는 응용 수준의 벤치마크를 통해서 시스템 호출 수준의 네트워크 입출력 성능 구조와 기존 리눅스의 성능을 비교하고 성능 차이의 원인을 분석하기 위해 성능 측정 시간동안 프로세서 내장된 Performance Monitoring Unit 을 이용해 패키지 간 캐시 일관성 활동 수를 수집한 결과이다.
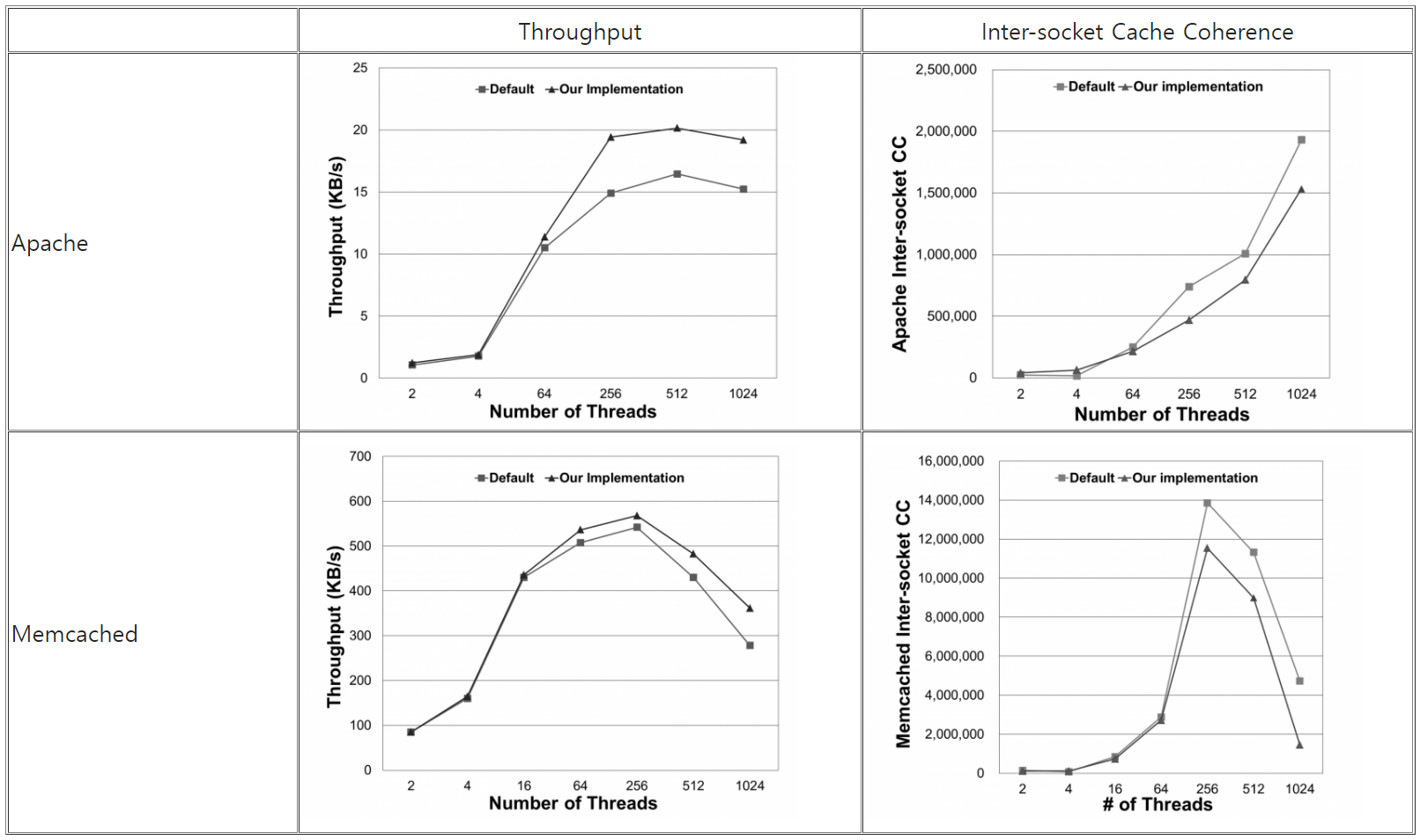
Apache와 Memcached를 통한 성능 실험에서 시스템 호출 수준의 네트워크 입출력 성능 향상 구조가 최대 약 30% 정도의 성능 향상을 보였으며, 이 때 패키지 간 캐시 일관성 활동 수 또한, 70% 수준으로 감소하였다. 제안된 구조를 적용하였을 때 패키지 간 캐시 활동 수가 감소한 이유는 시스템 호출 문맥들을 같은 프로세서 패키지에서 수행시켰기 때문인다. 향후에는 Syscall Thread를 위해 더 나은 친화도 정책을 연구할 예정이다.
코어 파티셔닝
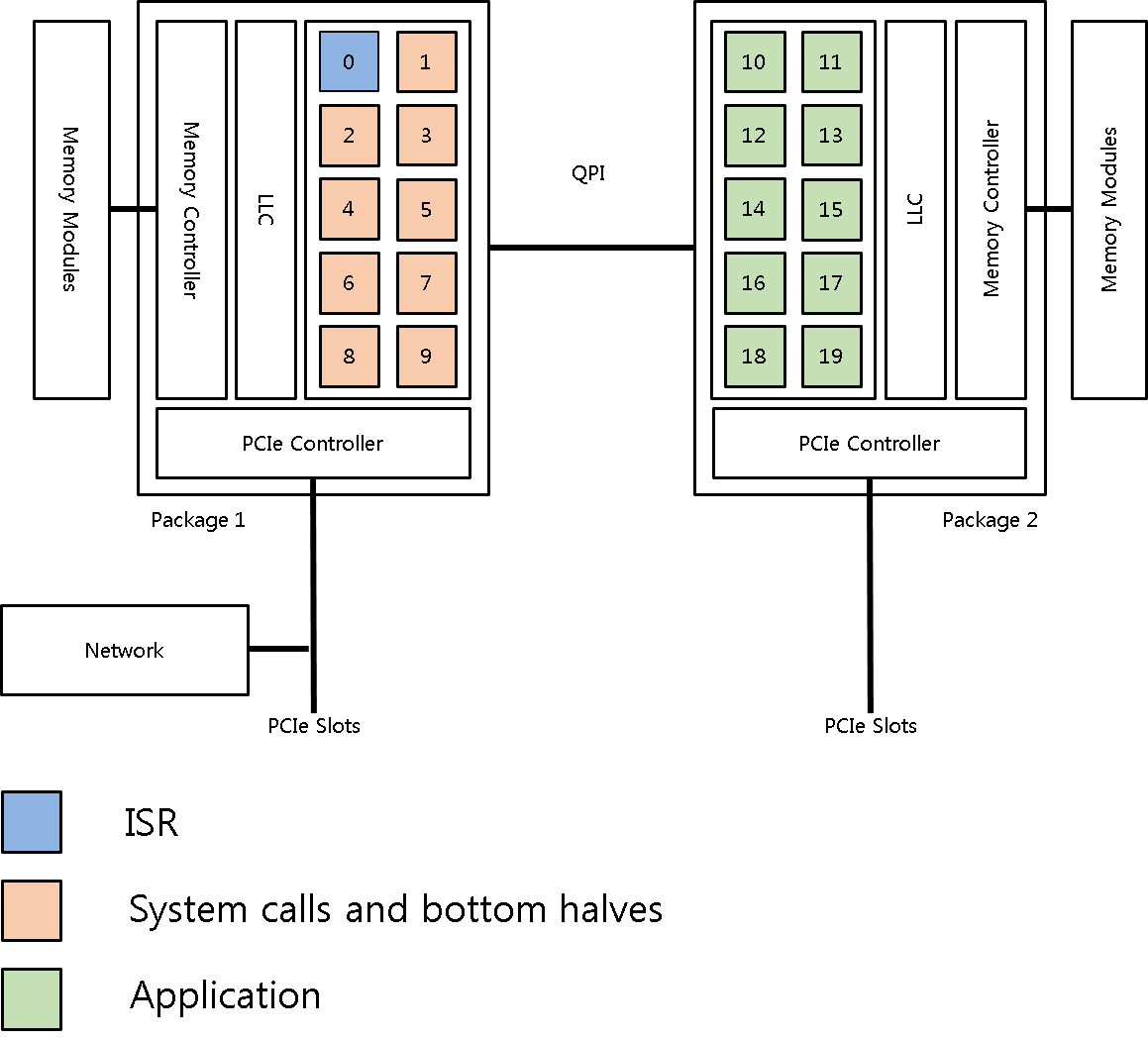
코어 파티셔닝에서는 앞서 연구했던 응용프로세스 수준의 코어 친화도, 인터럽트 수준의 코어 친화도, 그리고 시스템 호출 수준의 코어 친화도를 통합하여 실제 네트워크I/O를 수행할 코어를 지정한다. 네트워크 장치가 연결된 I/O 버스를 소유한 프로세서 소켓에 포함된 코어에서 네트워크 I/O 인터럽트를 처리하고, 인터럽트를 처리하는 코어와 마지막 수준의 캐시를 공유하는 코어에서 응용과 분리된 시스템 호출을 처리하도록 한다. 또한 동일한 네트워크 연결에 대한 네트워크 장치의 이벤트 핸들러(Bottom half)와 시스템 호출을 같은 코어에서 실행하도록 하여 데이터 지역성을 높이고 캐시 일관성 오버헤드를 낮추었다.
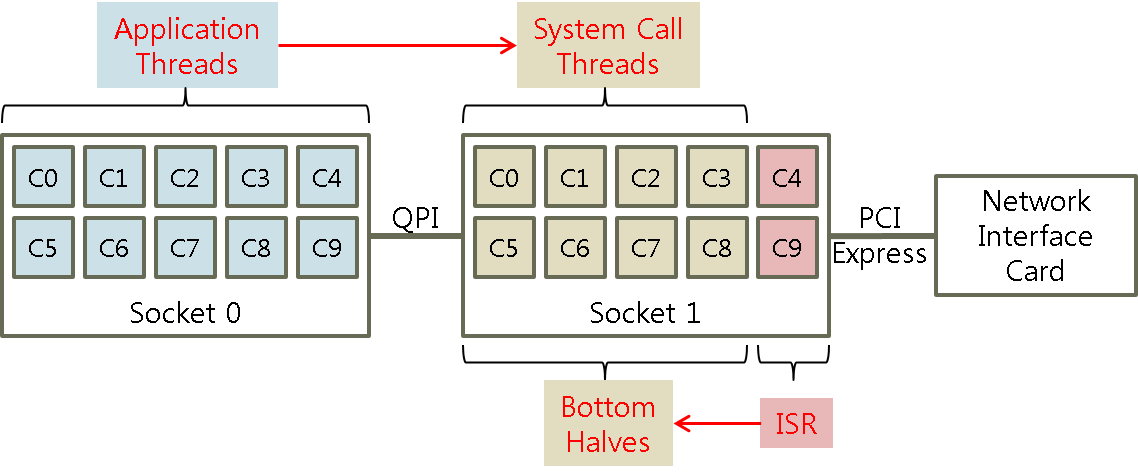
실험 환경
코어 파티셔닝 영향
실험 방법
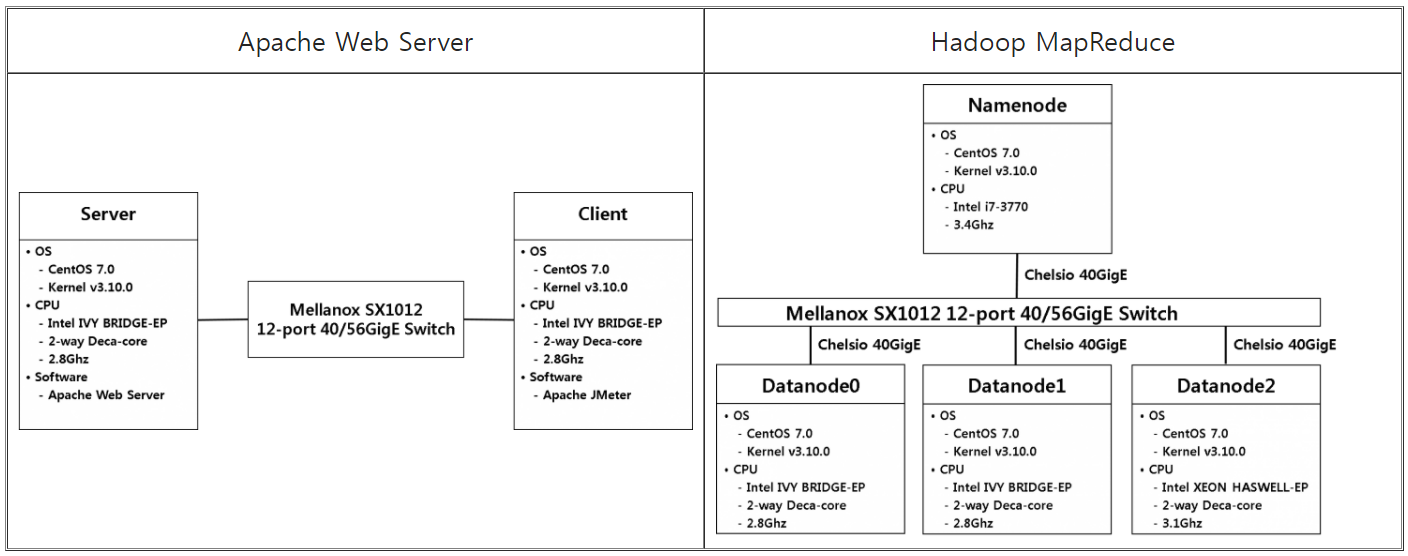
네트워크 장치와 가까운 Package1의 0번 코어에서 인터럽트를 처리하도록 한다. 인터럽트를 처리하는 코어와 LLC를 공유하는 1~9 번 코어에서 시스템 호출 및 이벤트 핸들러(Bottom halves)를 처리하도록 한다. 그리고 부하가 적은 나머지 코어에서 응용스레드를 처리하도록 코어파티셔닝을 적용한 후에, Apache Web Server와 Hadoop MapReduce를 이용해 코어파티셔닝의 성능을 측정하였다.
성능 평가
- Apache Web Server
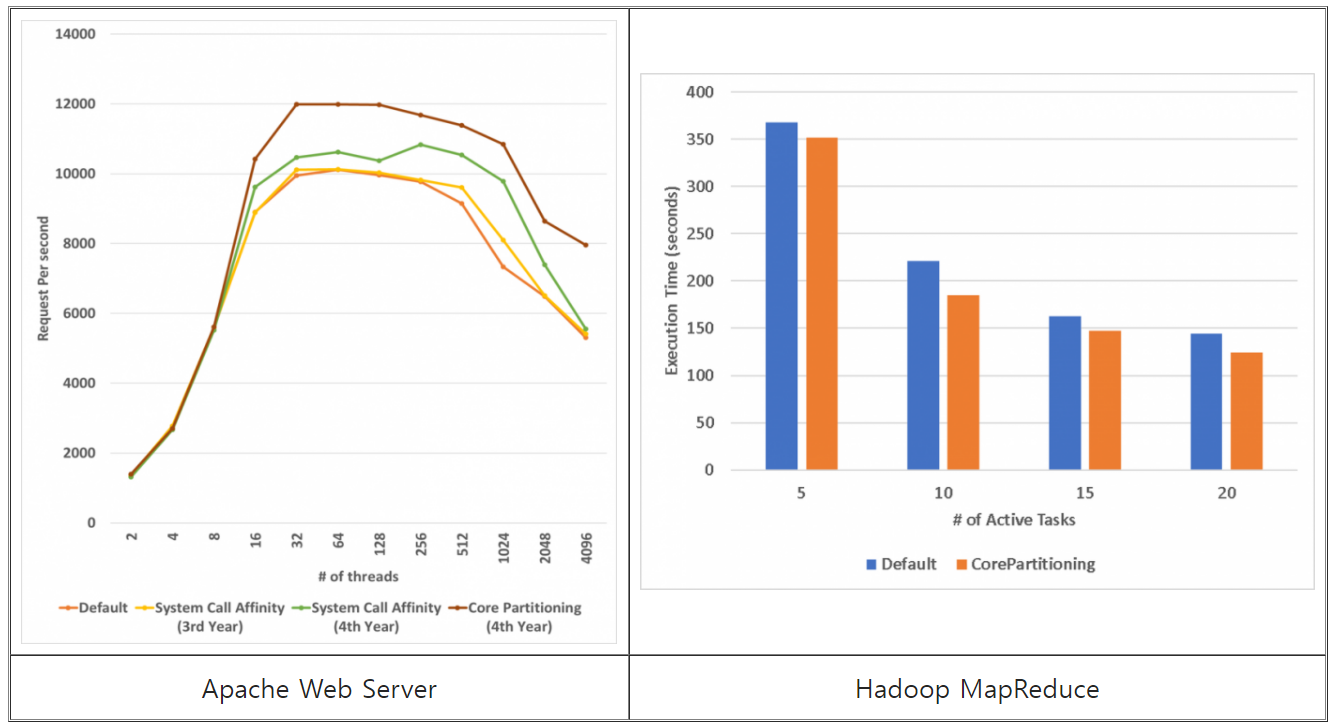
- JMeter 벤치마크를 사용하여 스레드가 증가함에 따라 초당 Request 처리율을 비교하였다. 코어파티셔닝을 적용하지 않았을 때보다 최대 50%의 성능향상을 보인다.
- Hadoop MapReduce
- TeraSort 응용을 통해 실행시간을 비교하였다. 입력된 데이터의 크기가 40Gb일 때, Active Tasks의 개수를 달리하며 실행시간을 비교한 결과 최대 16%의 성능향상을 보인다.
연구 결과물
- 발표 논문
- Joong-Yeon Cho, Hyun-Wook Jin and Dukyun Nam, "Enhanced Memory Management for Scalable MPI Intra-node Communication on Many-core Processor," Proceedings of the 24th European MPI Users' Group Meeting (EuroMPI 2017), Chicago, IL, USA, September 2017
- 조중연, 진현욱, 남덕윤, "MPI 노드 내 통신 성능 향상을 위한 매니코어 프로세서의 온-패키지 메모리 활용", 정보과학회 논문지, 제44권 제2호, pp. 124-131, 2017년 2월
- 엄준용, 조중연, 진현욱, "네트워크 성능향상을 위한 시스템 호출 수준 코어 친화도", 정보과학회 컴퓨팅의 실제 논문지, 제23권 제1호, pp. 80-84, 2017년 1월
- 조중연, 엄준용, 진현욱, 정성인, "다중 큐를 지원하는 고속 I/O 장치를 위한 동적 코어 친화도", 정보과학회 논문지, 제43권 제7호, pp. 736-743, 2016년 7월
- 엄준용, 조중연, 진현욱, "매니코어 시스템에서 네트워크 성능향상을 위한 메시지 기반 시스템 호출", 한국정보과학회 2016 한국컴퓨터종합학술대회 (KCC 2016) 논문집, 2016년 6월
- 조중연, 진현욱, "고속 I/O 시스템에서 HDFS를 위한 동적 코어 친화도 프레임워크 성능 분석", 한국정보과학회 2015 동계학술발표회논문집, 2015년 12월
- Jaehyun Hwang, Joon Yoo, Sang-Hun Lee, and Hyun-Wook Jin, "Scalable Congestion Control Protocol based on SDN in Data Center Networks," Proceedings of IEEE Global Communications Conference (GLOBECOM 2015), San Diego, CA, USA, December 2015
- 엄준용, 조중연, 진현욱, "매니코어 시스템에서 네트워크 버퍼 할당 정책에 따른 성능 분석", 한국정보과학회 2015 한국컴퓨터종합학술대회 (KCC 2015) 논문집, pp. 1586-1588, 2015년 6월
- J.-Y. Cho et al., "Dynamic core affinity for high-performance file upload on Hadoop Distributed File System," Parallel Computing, vol. 40, issue 10, pp.722-737, December 2014
- J.-Y. Cho and H.-W. Jin., "Manycore Partitioning for Big Data Processing: Does Core Affinity Matter?," ACM Symposium on Cloud Computing, November 2014
- 시연 영상