가상화 환경의 스케일러블 Lock 기법
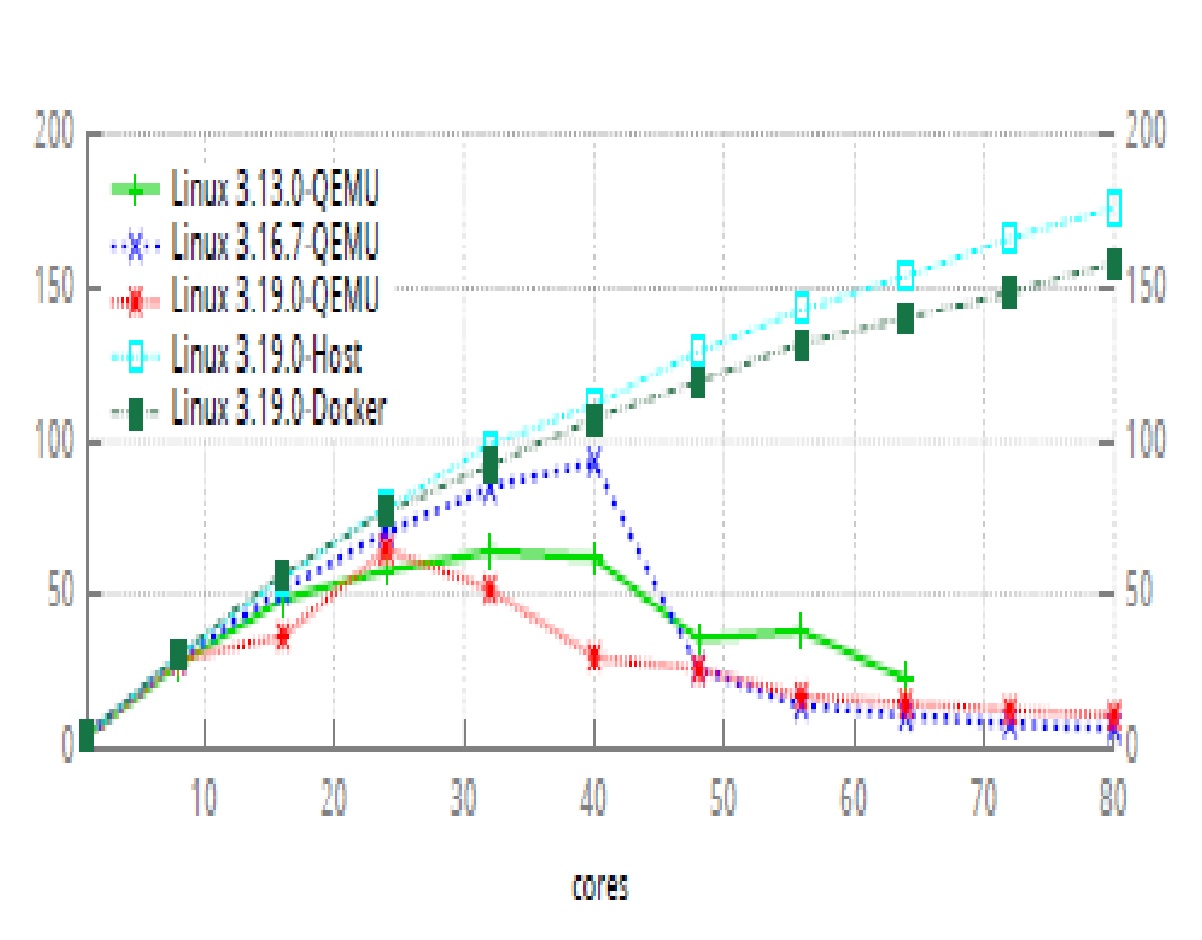
이제는 클라우드 환경으로 가상머신(VM)에서 운영체제의 스케일러빌러티도 연구의 대상이 되어야 한다. 현재 아마존 등의 클라우드 프로바이더는 vCPU로 30여코어까지만 지원하지만, 2016년 상반기부터는 100개의 vCPU까지 제공할 계획이다. 먼저 여러 가상화 환경에서 스케일러빌러티를 실험하였다. 80코어 머신에서 리눅스 빌더 응용으로 스케일러빌러티를 실험하였다. 그 결과, 물리적 머신(host) 및 도커(docker) 환경은 스케일러빌러티를 제공하였지만, QEMU 환경을 그렇지 못하였고, full virtualization(HVM)보다 paravitualization(PVM) 환경에서 스케일러빌러티의 문제가 존재하였다. 따라서 이 문제를 개선하고자 하는 것이 목적이다.
참고적으로 클라우드 프로바이더들은 다양한 저장 장치 서비스 제공과 효율적인 자원 활용측면 때문에 PVM 환경을 사용하고 있다.
스케일러빌러티를 위한 Opportunistic ticket spinlock (oticket) 개발
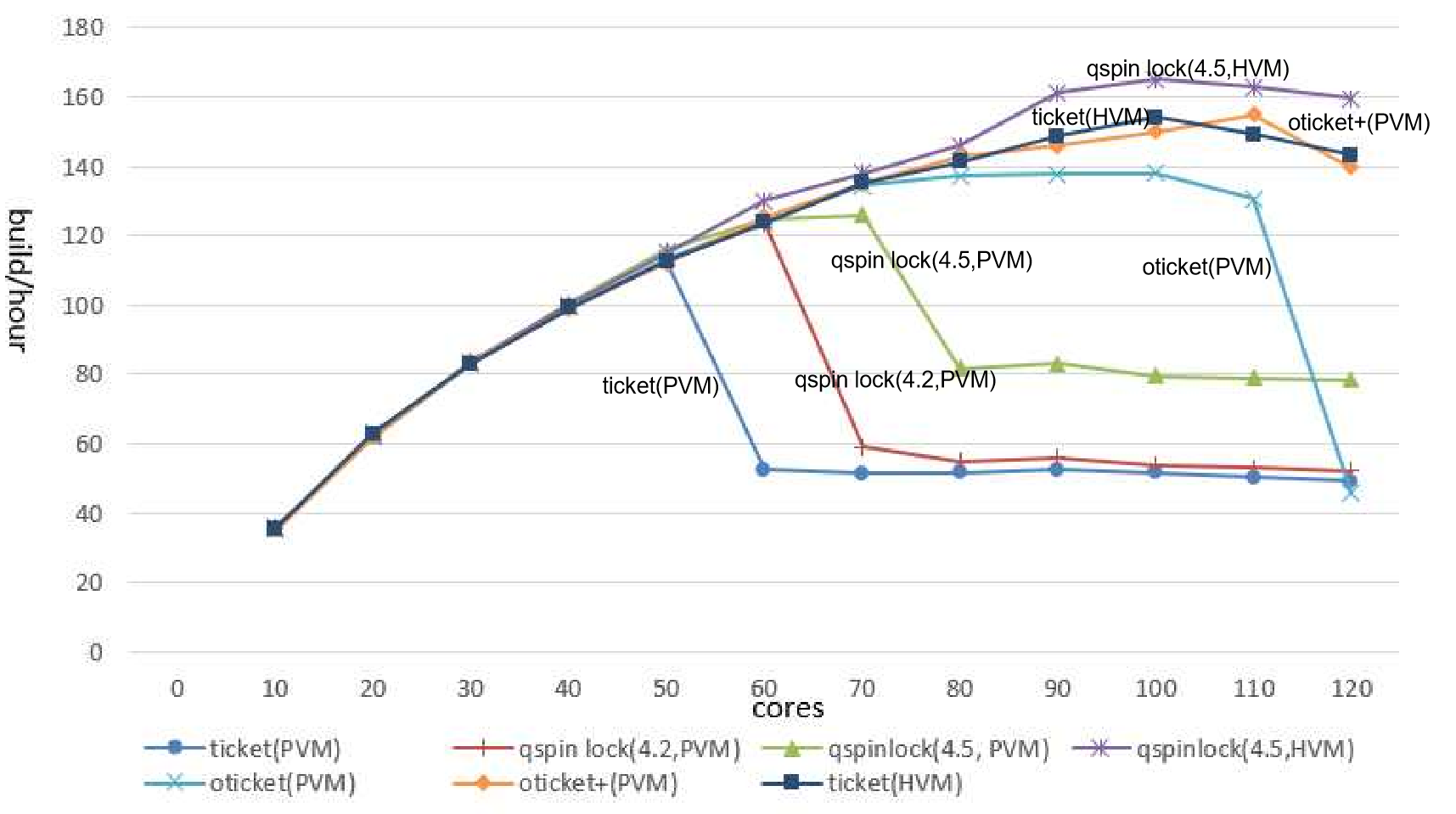
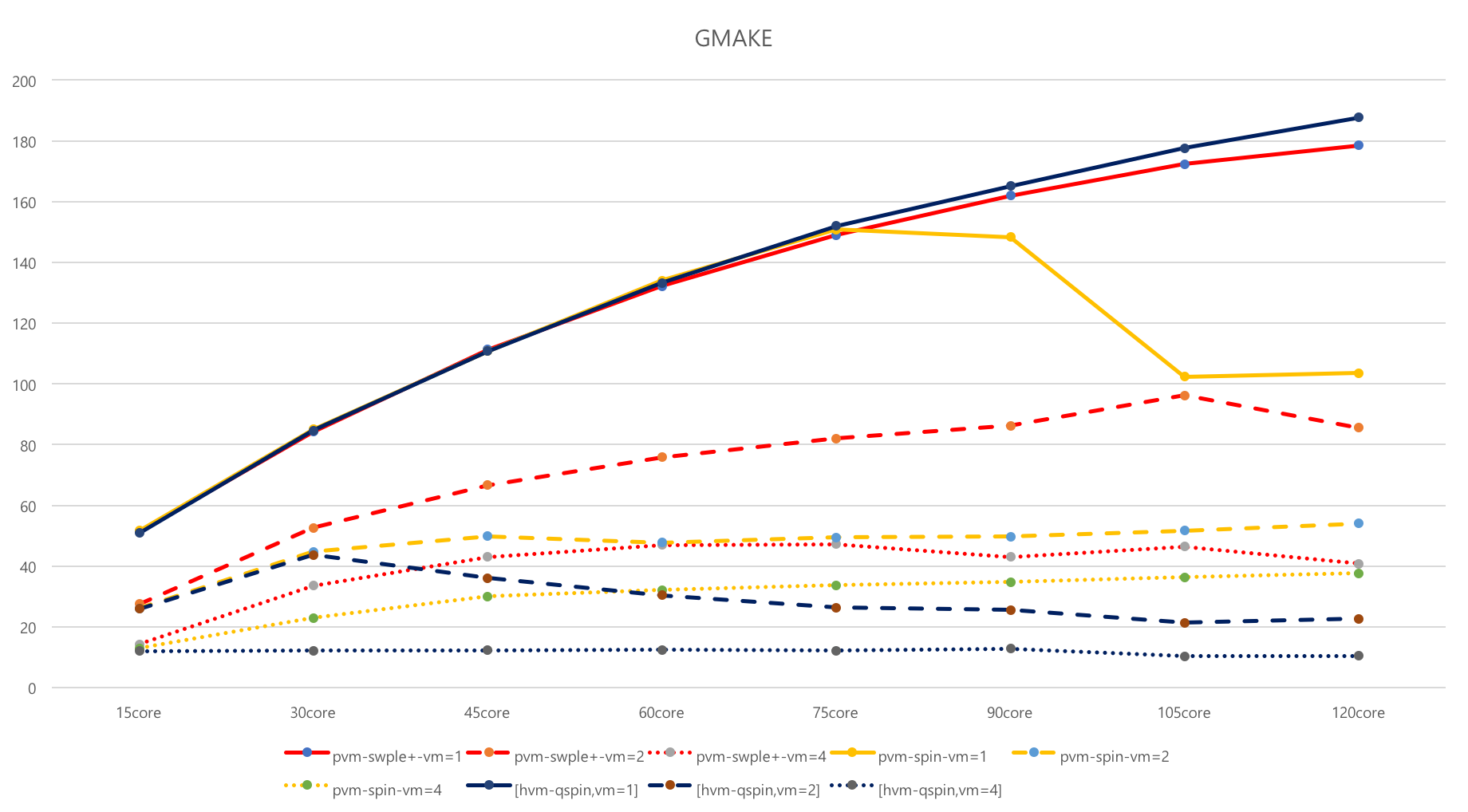
클라우드 환경에서 확장성을 저해하는 주요 요소인 락(lock)의 성능을 향상시키는 방법을 제시하였다. 스핀락은 리눅스 커널에서 동기화를 위한 기본 기능이지만, 확장성을 지원하지 않게 되면 전체 시스템 성능 하락시킨다. lock-holder와 lock-waiter를 효과적으로 선택해 내는 방식은 개선하여 스핀락의 성능이 물리환경과 유사하게 나타낼 수 있도록 하였다. 이를 통해 스핀의 임계치를 선택적으로 조절하며 또한 선택적인 wake-up을 적용하여 기존 반가상-스핀락 알고리즘을 개선한 기회-티켓-스핀락(o-ticket)을 개발하였다. 하지만 HT off한 120코어에서는 90코어 근처에서 성능이 떨어지는 현상이 있어, HVM 수준까지의 스케일러빌러티가 보장되도록 연구되었다(o-ticket+). 참고적으로 oticket 기술은 리눅스 커뮤니티에 공개되었고, 4.2커널 qspinlock 개발 시 참조되었다. 아래 그림은 gmake 워크로드에서 ticket spinlock(4.1커널), queue spinlock(4.2, 4.5커널), oticket, oticket+ 각각의 스케일러빌러티 성능 결과이다. oticket과 oticket+의 차이는 스핀락을 기다리는 slow path 부분에 있으며, HVM에서 사용하는 하드웨어에서 제공하는 PLE(Pause Loop Exit)기능을 SW적으로 제공하는 것과 schedule aware하도록 동작하는 기능이다.
Over-commit 서비스 개선
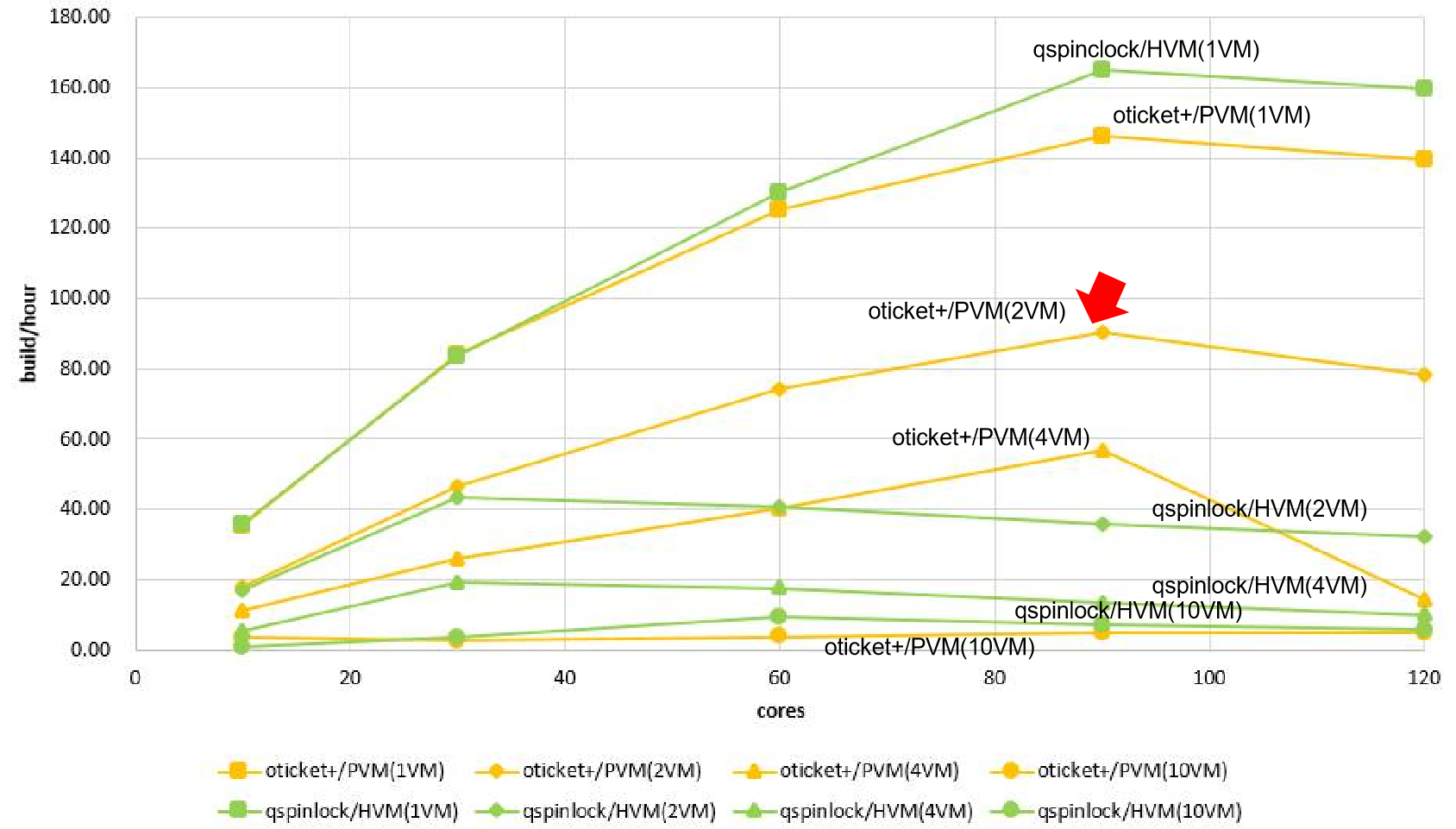
클라우드 서비스는 여러 개의 가상머신(VM)으로 컴퓨팅 자원을 공유하는 개념이다. 이론적으로 2개 가상머신에서 실험한 결과는 1개 가상머신에 실험한 성능의 반이 되어야 하는데, 실험 결과를 통해 그렇지 못함을 확인하였다. PVM뿐만 아니라 HVM에서도 마찬가지 현상이 있다. 이는 가상 머신의 상태정보(예, 락으로 sleep 등)를 QEMU가 인지하지 못하기 때문이다. 이러한 over-commit 서비스 문제를 oticket+ 개발을 통해서 해결하였으며, 해결방법은 가상머신과 QEMU간 상태정보를 전달할 수 있는 hyper-call를 제공하는 것이였다. 아래 그림에서 4.5커널의 queue spinlock 경우, over-commit 서비스가 제대로 지원되지 않는 것을 볼 수 있다. 반면에 oticket 경우 2VM까지는 지원되고, 4VM의 90코어부터는 제대로 지원되지 않는 것을 확인할 수 있다. 이 원인은 스케일러빌러터와 over-commit 서비스 개선을 위해서 추가된 schedule aware 기능 때문이다.
queue spinlock 개선
qspinlock+는 기존에 ticket lock을 개선했던 oticket+ 의 qspinlock 버전으로 oticket+와 구조는 동일하다. 기존의 PVM에서는 busy waiting 중에 특정 SPIN_THREASHOLD 만큼 spin하다 halt 를 호출해서 VMEXIT를 발생하고 KVM에서 halt handling을 다루도록 한다. 반면에 qspinlock+ 는 halt handling 대신에 HVM의 ple handling을 할 수 있도록 새로운 hypercall을 정의하여 hypercall을 수행하도록 한다. 또한 기존 HVM의 PLE handling 에서는 vcpu 가 속한 VM에서만 부스팅할 vcpu를 선택하지만, qspinlock+ 에서는 다른 VM의 vcpu도 대상으로 한다.
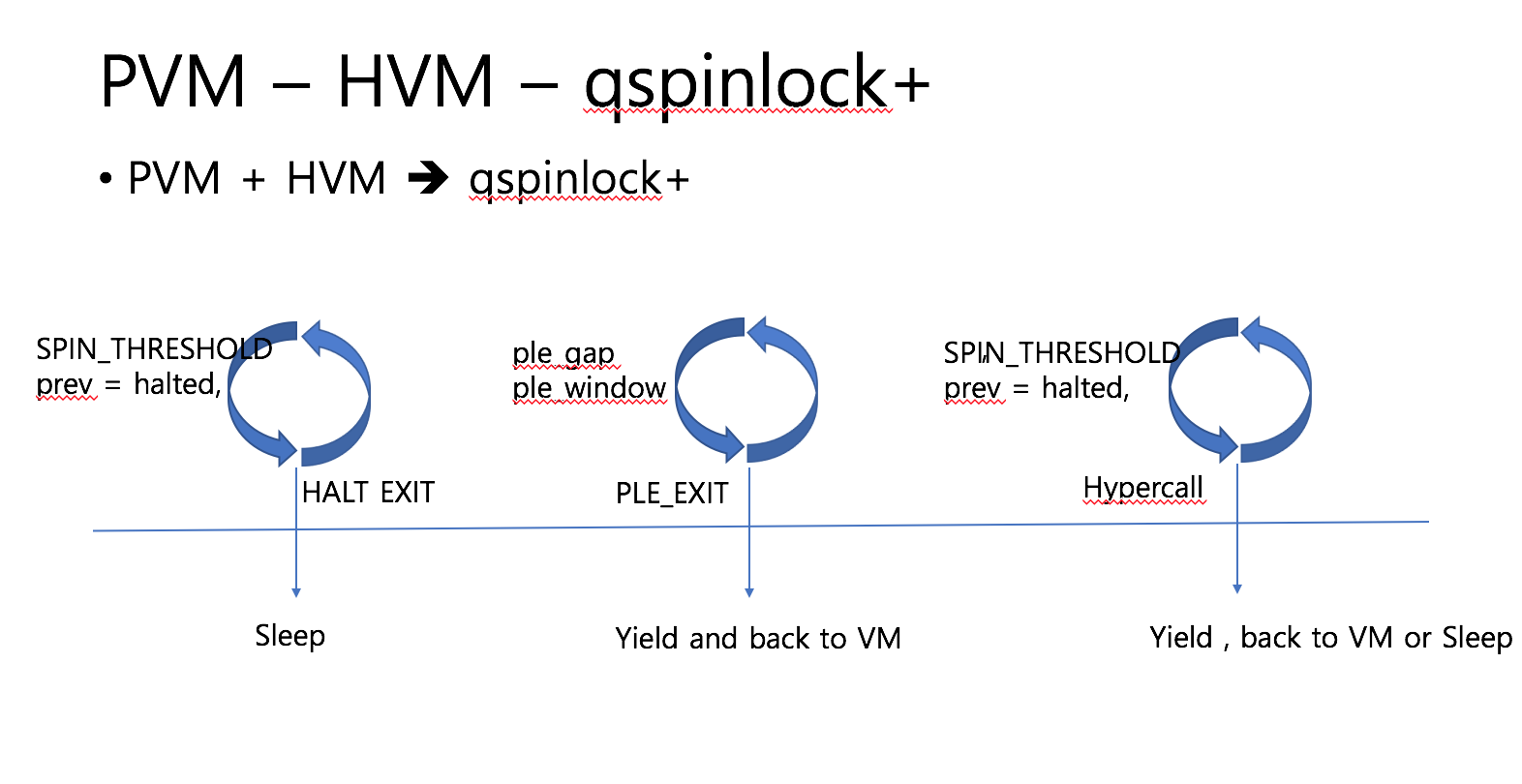
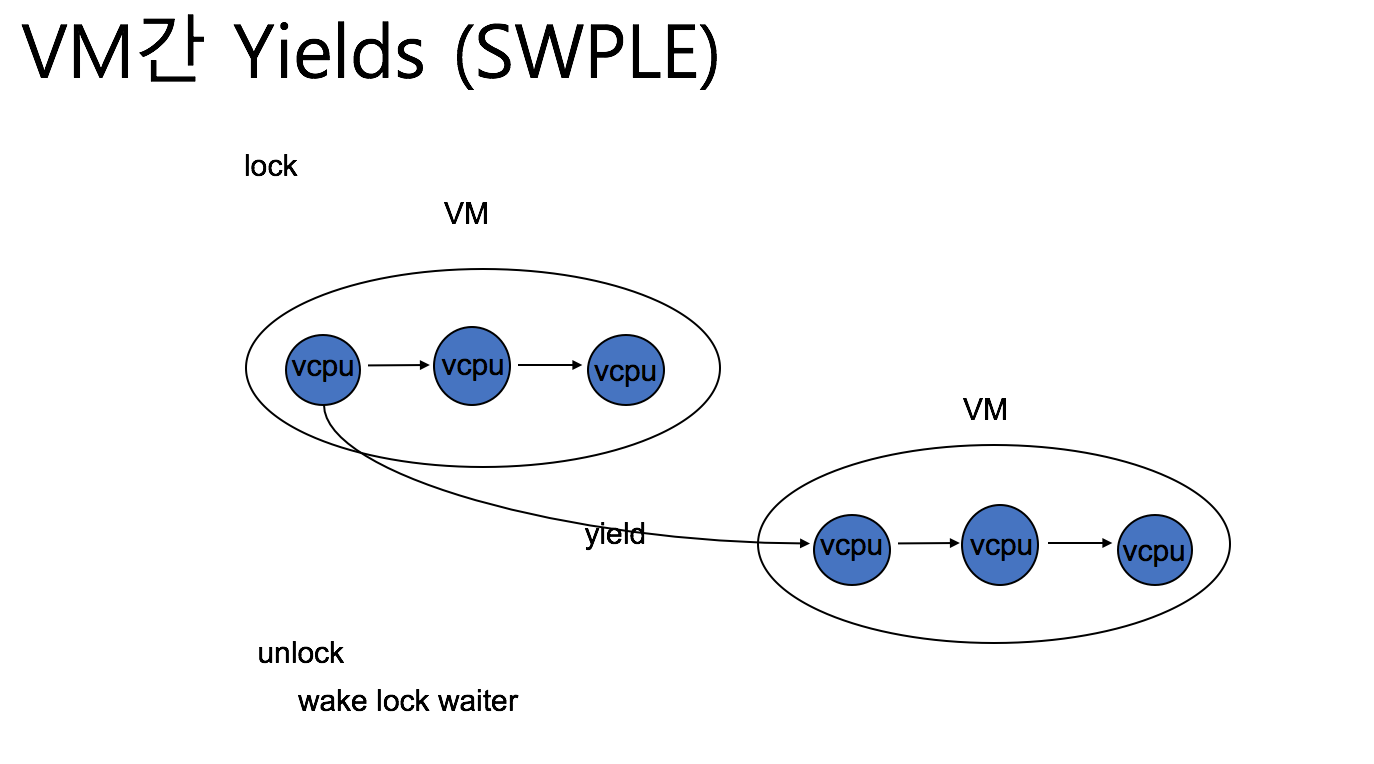
이처럼 PVM과 HVM의 장점을 취함으로써 overcommit 환경에서도 좋은 성능을 나타낸다.
결과물
- 응용성능 비교
- 성능측정을 위한 도구
- 커널소스
- Github : Opportunistic-Spinlock
- 논문
- 시연영상