스케일러블 NOVA 파일시스템
Range Lock을 이용한 NOVA의 단일 파일 쓰기 병렬화
연구 개요
비휘발성 메모리는 DRAM과 비슷한 읽기/쓰기 지연시간, 바이트 단위 접근성, 갑작스러운 전력 차단 이후의 비휘발성 등의 특성을 가지고 있다. 이러한 특성들로 인하여 비휘발성 메모리는 I/O를 위한 스토리지 매체로 사용될 수 있으며 이에 관한 연구가 활발히 진행되고 있다. NOVA는 일관성을 보장하는 비휘발성 메모리 파일시스템중 State-of-Art 이며 멀티코어를 염두한 자료구조 때문에 어느정도의 스케일러빌리티를 가진다. 하지만 파일 쓰기 시 파일에 획일적을 락을 거는데, 이로 인하여 단일 파일에 대한 스케일러빌리티가 전혀 없다. 이는 단일 파일 쓰기가 잦은 멀티 쓰레드 고성능 데이터베이스같은 애플리케이션의 스케일러빌리티를 제한한다. 이를 위하여 NOVA 파일시스템에 단일 파일 쓰기의 스케일러빌리티를 위한 최적화 연구를 수행한다.
연구 내용
- 범위 기반 락
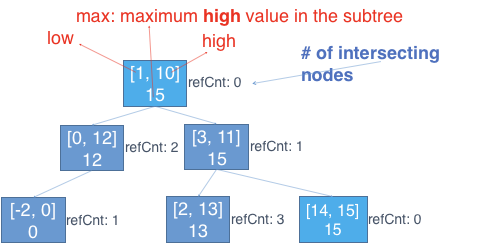
Interval tree를 이용한 범위 기반 락으로 파일 쓰기시의 획일적인 락을 대체한다. Interval tree는 겹치는 범위를 찾기 위한 효율적인 자료구조이며, 범위의 시작과 끝이 tree의 노드로 삽입된다. 파일 쓰기 시, 해당 쓰기의 범위를 tree의 노드로 삽입하고, 해당 노드와 범위가 겹치는 노드가 있다면 현재 쓰기는 중단되어 기다린다. 겹치는 범위를 가지는 쓰기가 종료되면 그 쓰레드가 범위가 겹쳐서 기다리는 쓰레드들을 깨워주고, 중단되었던 쓰기는 다시 진행된다. 겹치는 범위를 확인하는 단위는 페이지 (4KB) 이므로, 설령 어떤 두 쓰기가 실제로는 겹치지 않더라도 같은 페이지에 쓰기를 하는 쓰기라면 둘중 하나의 쓰기는 중단되어 기다리게 된다. 하지만 겹치지 않는 쓰기에 대해서는 모두 병렬적인 쓰기가 가능하다.
- lock-free 로깅
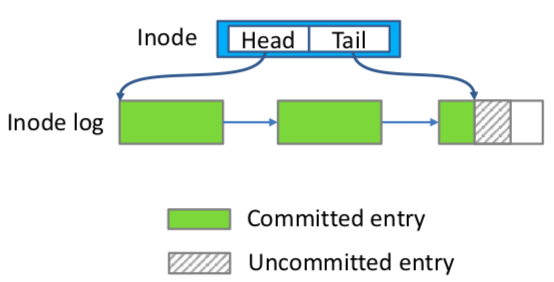
위 그림처럼 NOVA는 쓰기 시 로깅을 하여 일관성을 보장한다. 또한 로그를 통해 갑작스러운 전원 차단 시 파일시스템의 상태를 복구하게 된다. 즉 로그는 NOVA 파일시스템의 신뢰성의 가장 큰 요소이다. 하나의 파일당 로그 페이지들이 연결 리스트로 구성이 되어 있으며, 하나의 로그 페이지 안에서는 순차적으로 로그가 쓰이게 된다. 따라서 단일 파일 병렬 쓰기 시, 로그를 순차적으로 쓰기 위하여 로그를 쓸 자리인 로그포인터에 대하여 lock을 이용하여 순차쓰기를 수행하여야 한다. 그러한 로그 포인터의 lock은 매니코어 시스템에서 단일 파일 병렬 쓰기의 스케일러빌리티를 제한한다.
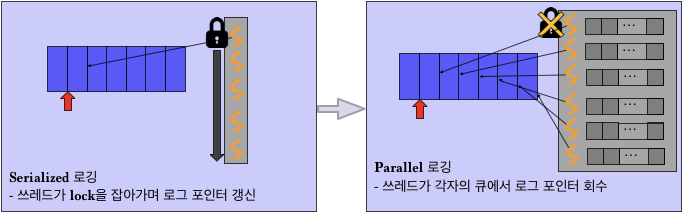
이를 해결하기 위하여 로그 포인터 갱신시 락을 쓰지 않는 로깅 기법을 제안한다. 우선 각 코어마다 로그 포인터를 저장하기 위한 lock-free circular queue를 정의한다. 하나의 지정된 쓰레드는 주기적으로 로그 포인터들을 각 코어의 queue에 삽입한다. 쓰기를 수행하는 쓰레드들은 해당하는 코어의 queue에서 로그 포인터를 꺼내오고 그 포인터에 로깅을 수행한다. queue에 삽입 연산은 지정된 하나의 쓰레드가, 꺼내오는 연산은 쓰기 쓰레드 하나만이 수행하므로 queue의 모든 연산은 락을 필요로 하지 않는다. 이런 방식으로 락이 없는 로깅을 수행할 수 있다.
- light-weight 범위 락
기존의 범위 락은 범위가 겹치는지를 확인하기 위하여 매 쓰기시 마다 해당 노드를 tree에 삽입해야한다. 그런데 삽입 연산은 tree를 독점해서 사용해야 하므로 매니코어 환경에서 interval tree의 락이 병목지점이 된다. 따라서 파일시스템에서 겹치는 범위로 쓰기가 잘 발생하지 않는 점에 착안하여, interval tree의 락 병목을 줄이는 light-weight 범위 락 기법을 제안한다. 이를 위하여 우선 페이지의 집합인 segment라는 단위를 정의한다. 또한 segment들을 비트맵으로 관리하며, 쓰기를 수행하는 segment 대하여 해당하는 비트를 1로 set 한다. 만약 이미 1로 set 되어 있다면, 같은 세그먼트에 쓰기가 수행 되는 중이므로 cpu를 소모하며 해당 bit이 0이 될 때 까지 spin 하며 기다린다. 이러한 segment-based 범위 락은 범위를 확인하는 단위를 page 아닌 segment로 하여 course-grained한 범위 확인을 한다. 따라서 범위의 세밀성을 잃는 대신, 간단한 자료구조와 락 병목이 적은 범위 확인 방법을 제공하여 확장성을 높인다.
성능 측정
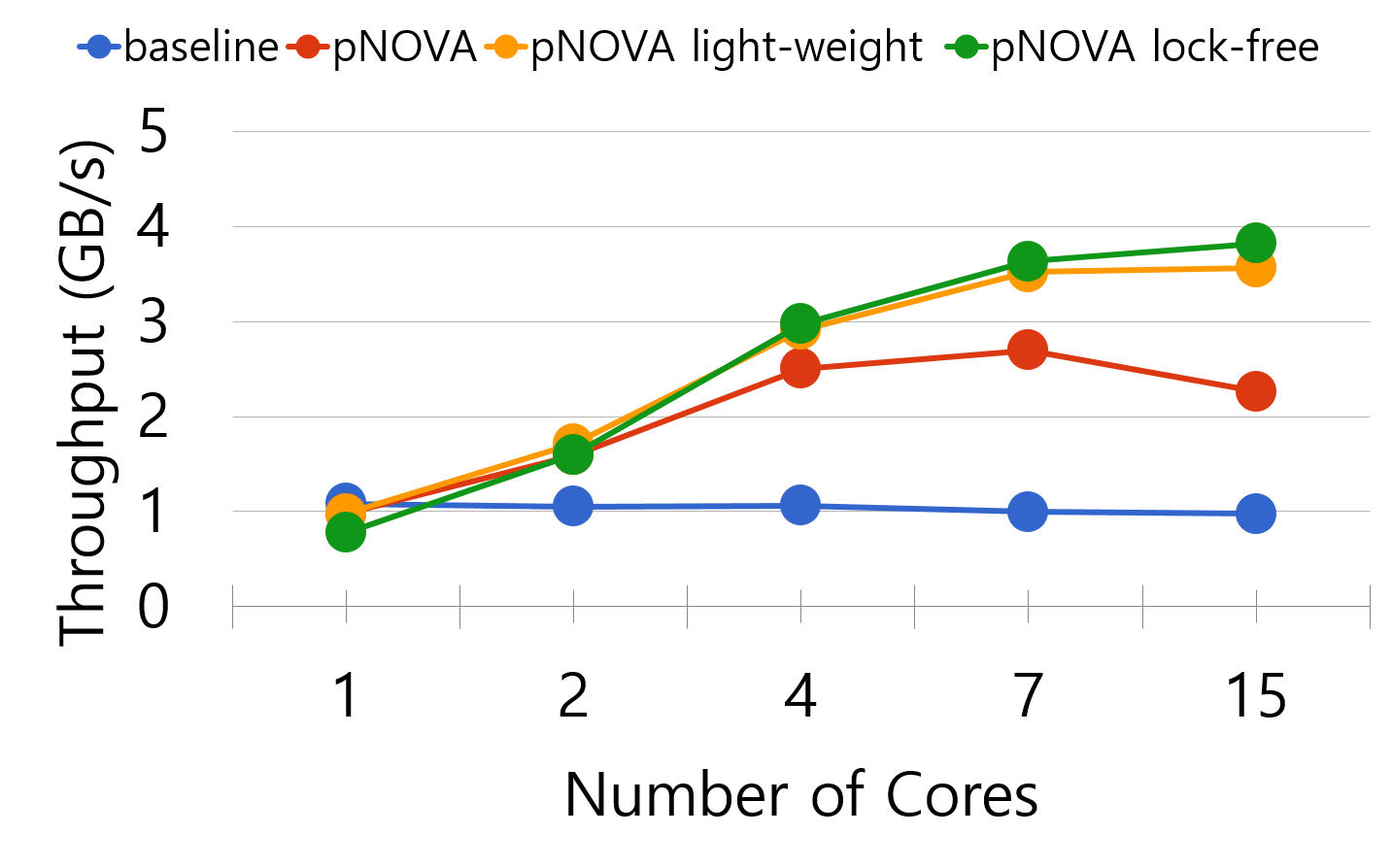
파일시스템의 스케일러빌리티를 측정하는 벤치마크인 FxMark에서 단일 파일에 멀티 쓰레드 쓰기의 성능을 측정할 수 있는 DWOM 워크로드를 이용하여 성능을 측정하였다. 기존의 NOVA (baesline)은 파일 전체에 걸리는 락 때문에 단일 파일 쓰기에서 전혀 스케일러빌리티가 없다. 범위 락이 구현 된 NOVA (pNOVA)는 7코어 가지 스케일러빌리티를 보인다. 하지만 범위 락을 위한 interval tree의 병목과 로그 포인터 락의 병목때문에 그 이상의 스케일러빌리티를 보이지 못한다. segment 기반의 범위 락이 적용된 NOVA (pNOVA light-weight)는 pNOVA 보다 개선된 스케일러빌리티를 보이지만 로그 포인터 락의 병목으로 인하여 15코어 까지는 스케일러빌리티가 없다. 마지막으로 lock-free 로그 포인터 갱신이 적용된 NOVA (pNOVA lock-free)는 로그 포인터 락의 병목까지 제거하여 15코어 까지의 스케일러빌리티를 보인다.
세그먼트 기반 Range lock을 이용한 NOVA의 단일 파일 읽기/쓰기 최적화
연구 배경
최근 인텔의 3D-Xpoint, RRAM (Resistive RAM), PCM (Phase Change Memory) 등의 메모리 버스에 장착되는 비휘발성 메모리는 접근의 단위가 바이트이며 DRAM과 같거나 약간 큰 읽기/쓰기 지연시간을 가진다. 이러한 비휘발성 메모리의 특징으로 인하여 이들은 최근 요구되기 시작하는 고성능 I/O를 위한 스토리지 매체로 사용 될 수 있다. 한편, 비휘발성 메모리 기반의 파일시스템들은 비휘발성 메모리 자체의 하드웨어 특성과 파일시스템의 여러 가지 최적화로 인하여 SSD와 HDD같은 기존의 블락 기반 장치 파일시스템들보다 좋은 성능을 제공한다. 우선 초당 메가바이트의 스루풋을 보이는 블락 기반 장치에 비하여, 비휘발성 메모리는 초당 기가바이트의 스루풋을 보인다. 둘째로, 기존 블락 장치 기반 파일시스템에서는 디스크 접근을 최소화하기 위하여 페이지 캐시를 사용한다. 즉, 데이터에 대한 접근이 우선 페이지 캐시부터 발생하여 이로 인한 오버 헤드가 발생한다. 하지만 비휘발성 메모리 파일시스템은 페이지 캐시를 사용하지 않으므로 해당 오버헤드가 없어지며 이로 인하여 I/O의 지연시간이 짧아진다. 또한 비휘발성 메모리 파일시스템은 장치의 바이트 단위의 접근성으로 인하여 상대적으로 적은 오버헤드로 파일시스템의 일관성을 보장한다. 즉, 블락 장치 기반 파일시스템들의 일관성 보장 방식은 하나의 트랜잭션에 대한 일관성을 보장하기 위하여 하나 이상의 블락을 써야하므로 큰 오버헤드를 유발하는데 비해, 비휘발성 메모리 기반 파일시스템들은 메모리의 바이트 단위의 접근성을 이용하여 적은 양의 쓰기로 하나의 트랜잭션의 일관성을 보장하므로 일관성 보장의 오버헤드가 적다.
- 기존 비휘발성 메모리 파일시스템 NOVA의 문제점
하지만, 이러한 고속의 스토리지 매체의 특징에도 불구하고 NOVA 파일시스템에서는 여러 쓰레드들이 단일 파일에 읽기/쓰기 연산을 하는 경우 병렬적인 I/O 수행의 확장성 문제를 보인다. 이는 NOVA 파일시스템 계층에서 읽기/쓰기 연산 시 파일 전체에 락을 걸기 때문이다. 첫째, 여러 쓰레드가 한 파일에 동시 읽기를 수행하는 경우 각각의 쓰레드들은 파일의 하나의 참조 계수를 증가시키기 위해 경쟁을 한다. 이는 참조 계수 카운터 문제로 잦은 캐시 일관성 프로토콜을 일으켜 확장성에 심각한 손상을 일으킨다. 둘째, 여러 쓰레드의 한 파일에 대한 동시 쓰기 동작이 불가하다. 쓰레드들의 쓰기 범위가 다름에도 불구하고 특정 쓰레드가 파일에 대해 쓰기 중이라면 다른 쓰레드들은 블락킹되어 쓰기 동작들이 직렬화 될 수 밖에 없다. 이를 해결하기 위하여 본 논문에서는 획일적인 락이 아닌 파일 쓰기 범위에 기반한 범위 락의 이용을 제안한다. 다음으로 범위 락을 사용하더라도 단일 파일이 관리하는 단일 메타데이터에 대한 경쟁으로 인해 확장성을 저해 받는다. 대표적으로 NOVA는 한 파일 당 하나의 linked-list 형태의 log-structure를 관리하기 때문에 여러 쓰레드가 한 파일에 대해 쓰기 연산을 하는 경우 로그를 올바르게 업데이트하기 위해 쓰레드들이 직렬화 된다.
연구 내용
- 세그먼트 범위 기반 락
pNOVA는 NOVA의 획일적인 락을 범위 기반 락으로 대체하였다. pNOVA의 범위 기반 락은 파일을 세그먼트라는 단위로 나누고 각 세그먼트들을 관리하는 락 변수를 두어 읽기/쓰기 범위에 따라 해당 세그먼트들만 락을 한다.
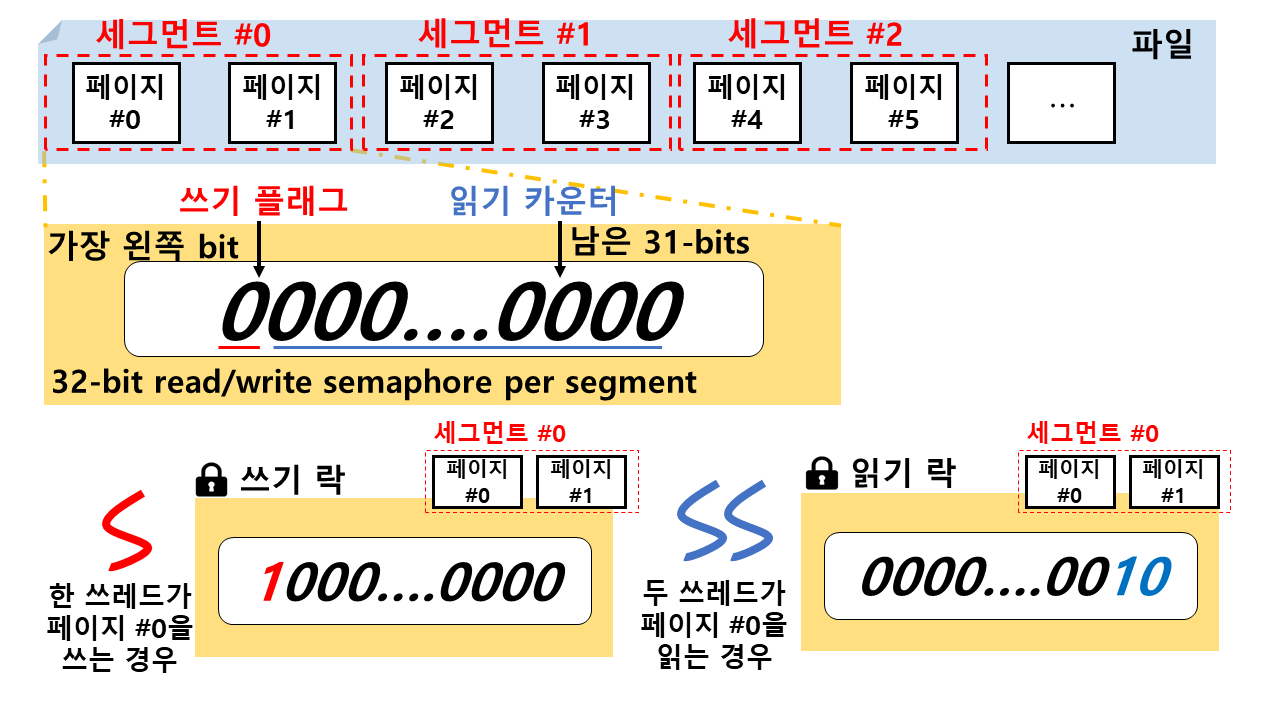
그림 1은 pNOVA의 세그먼트 범위 기반 락의 구조를 보여준다. 파일을 연속적인 페이지들의 그룹으로 생각했을 때, 우선 연속적인 페이지들을 세그먼트라는 단위로 묶는다. (그림에서는 두 페이지들을 하나의 세그먼트로 정의하였다.) 각 세그먼트는 32-bit의 세마포어를 가지는데, 세마포어의 가장 왼쪽 bit는 쓰기 플래그로 사용되며 남은 31-bit는 읽기 카운터로써 사용된다. 쓰레드들은 읽기/쓰기 범위에 따라 해당 세그먼트의 세마포어에 접근한다. 만약 가장 왼쪽의 bit가 1일 경우 해당 세그먼트에 대해 특정 쓰레드가 쓰기 중이므로 이후에 접근하는 읽기/쓰기를 블록킹한다. 만약 세마포어의 값이 0이 아니면서 가장 왼쪽 bit가 1도 아닌 경우 특정 쓰레드들이 읽기 중이므로 들어오는 읽기 동작에 대해서는 카운터를 증가시키고, 쓰기 동작에 대해서는 블록킹을 한다. 세그먼트의 세마포어를 변경하는 동작들은 모두 하드웨어가 지원하는 atomic-operation을 사용해 원자성을 보장한다. 또한 pNOVA의 범위 기반 락은 세그먼트마다 참조 계수 카운터를 가지고 있기 때문에 다른 범위의 읽기 동작에 대해서는 참조 계수 카운터 문제가 발생하지 않는다. 병렬적 쓰기 동작에 대해서는 각각의 쓰레드가 쓰기 범위에 해당하는 세그먼트만 락을 걸어 범위가 다른 경우 서로에 의해 블락킹 되지 않는다.
- 2D log-structure
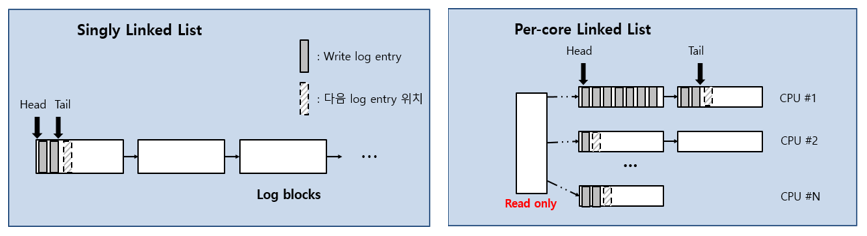
NOVA의 파일 당 단일 linked-list log-structure (single linked-list log-structure per file) 구조는 여러 쓰레드가 단일 파일에 대해 쓰는 경우 병목현상이 될 수 있다. pNOVA는 이를 해결하기 위해 코어마다 linked-list 형태의 log-structure를 관리하는 2D log-structure를 디자인 하였다. 모든 코어들은 4KB 크기의 read-only 블록을 공유하며 해당 블록은 코어들의 log-structure 인덱싱에 사용된다. 쓰기 쓰레드들은 각각의 분리된 linked-list log-structure를 업데이트 하므로 병렬적 쓰기의 성능이 향상된다.
매니코어 NUMA를 위한 확장성 있는 NVM 파일시스템 디자인
연구 배경
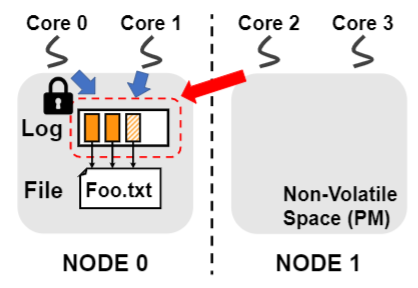
대표적인 영구적 메모리(PM, Persistent Memory) 파일시스템인 NOVA는 NUMA 기반의 매니코어 환경에서 그림 1에 설명되어 있는 두 가지 이유로 낮은 동시성에 의한 확장성 문제를 가지고 있다. 그림 1는 NOVA에서 여러 I/O 쓰레드들이 동시에 같은 파일을 업데이트 하려는 상황이다. 첫번째, NUMA를 인지하지 못한 파일시스템은 모든 파일의 데이터와 메타데이터를 단일 노드의 PM 공간에 배치한다. 따라서 다른 노드에서 수행되는 쓰레드들은 원격 메모리 접근을 통해 파일에 접근해야하므로 I/O 성능이 크게 저하된다. 두번째로 NOVA는 파일시스템의 일관성을 보호하기 위해 로그 구조의 디자인을 사용하며 PM 공간에 있는 per-inode log-structure에 파일의 업데이트 내용을 기록한다. 로그 구조는 락으로 보호되기 때문에 동시적으로 공유 파일을 쓰기하는 쓰레드들은 이 락에 의해 직렬화 된다. 뿐만 아니라 서로 다른 노드의 쓰레드들이 파일의 로그를 공유하는 경우 일부 쓰레드들에게 원격 메모리 접근을 통한 logging이 강제된다. 따라서 본 연구에서는 NUMA 기반의 매니코어 서버에서 확장성을 보이는 NUMA 인지적인 NOVA 파일시스템을 제안한다. 이를 위해 우리는 NOVA의 메모리 할당자가 여러 노드의 PM을 인지하고, 파일 데이터와 메타 데이터를 여러 노드에 분산 배치 할 수 있게 하였다. 또한 NOVA의 per-inode logging 방식을 per-Core logging 방식으로 확장하였다.
연구 내용
우리가 확장 가능한 NOVA를 디자인하기 위해 제안한 두 기술은 다음과 같다:
- NUMA 인지적 파일 배치
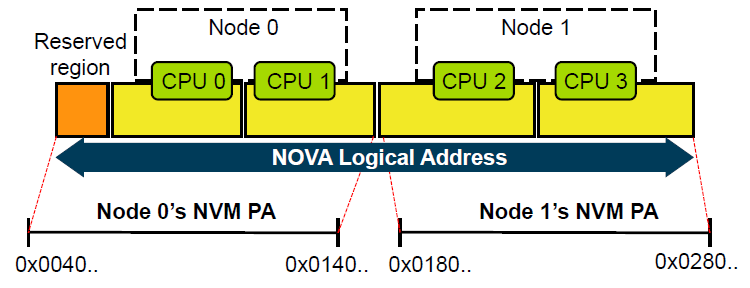
NUMA 인지적 파일 시스템은 여러 NUMA 노드에 파일을 분산 배치하여 원격 메모리 접근을 줄일 수 있다. 우리는 NUMA 인지적인 NOVA를 설계하기 위해 여러 NUMA 노드에서 연속되지 않은 NVM 주소 공간들을 연속적인 단일 가상 주소 공간으로 가상화하였다. 이를 위해 파일 시스템을 마운트 할 때 슈퍼 블록으로 모든 NUMA 노드에서 NVM 장치의 정보들을 가져온다. 결과적으로 NVM 장치의 물리적 주소가 선형으로 매핑되어 NUMA 인지적인 NOVA가 사용자 데이터와 메타 데이터를 여러 NVM 장치에 쉽게 배치할 수 있다. 이때 원격 메모리 접근을 완화하기 위해 메모리 할당 정책이 필요하다. 우리는 NUMA 인지적인 NOVA에서 쓰레드가 로컬 NVM 장치에 파일을 우선적으로 쓰도록 하는 "Local Write First" 정책을 도입했다. 그림 2는 두 개의 NUMA 노드가 있는 제안된 NUMA 인지적인 메모리 할당 정책을 보여준다. NUMA 인지적인 NOVA는 NVM 장치의 크기에 따라 전체 논리 주소 공간을 분할하고 NUMA 노드 별 파티션을 생성한다. 또한 파티션은 각 노드의 코어 수로 나뉘며 NOVA의 CPU 당 메모리 할당자에 의해 관리된다. 각 쓰레드의 파일 데이터 및 로그 페이지는 쓰레드가 실행중인 코어에 할당된 영역에서 할당된다. 예를 들어 CPU-0 및 CPU-1에서 실행되는 쓰레드는 0x0040~0x0140 범위의 물리적 주소 공간에 파일을 배치하는 것을 선호하는 반면 CPU-2 및 CPU-3에서 실행되는 쓰레드들은 0x0180~0x0280 범위에 파일을 우선적으로 배치한다. 결론적으로 각 I/O 스레드는 우선적으로 로컬 NVM 공간에서 데이터 또는 로그 페이지를 할당 받을 수 있다.
- Lock-Free Per-Core 로그 구조
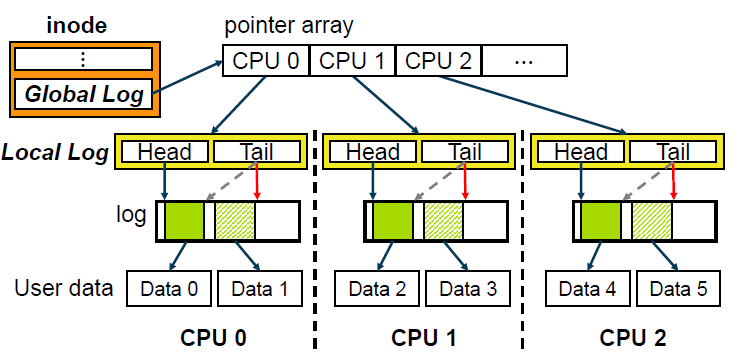
여러 쓰레드간에 공유되는 파일 데이터 구조는 NUMA 기반 시스템에서 파일 시스템의 확장성 병목 현상의 주요 원인이 된다. 서로 다른 NUMA 노드에서 실행되는 여러 쓰레드간에 파일을 공유하면 잦은 원격 메모리 접근으로 인해 성능이 크게 저하된다. 또한 공유 자원은 일관성을 보장하기 위해 락을 통해 보호되므로 동시 업데이트 작업이 직렬화된다. 따라서 우리는 확장 가능한 NOVA를 위한 per-core 데이터 구조를 제안하고 NOVA의 per-inode 로그 구조를 lock-free per-core 로그로 확장한다. 그림 3은 NOVA에 대해 제안된 lock-free per-core 로그 구조를 보여준다. 여기서 두 가지 새로운 영구적 데이터 구조인 global log 및 local log를 소개한다. global log는 그림 3에 표시된 것처럼 inode에 포함되며 각 CPU의 local log를 인덱싱하는 포인터 배열이다. Local log는 per-core 로그에 대한 헤드 및 테일 포인터가 있는 CPU 별 개인 데이터 구조이다. 이 두 데이터 구조를 통해 서로 다른 NUMA 노드의 여러 쓰레드가 파일 I/O 동작을 동시에 수행하고 확장성을 향상시킬 수 있다.
결과물
- 논문
- 공개 소프트웨어
- Github: pNOVA
- 시연 동영상