코어별 저널링을 통한 파일시스템의 저널 로깅 확장성 개선 연구
연구 개요
파일시스템에서 저널은 파일 데이터의 일관성이 손상되는 것을 방지하고, 갑작스러운 시스템의 충돌 혹은 전원에 이상이 발생하는 경우에 최종적으로 쓰기를 완료한 데이터가 저장장치에 안전히 남아있는 것을 보장한다. 따라서 대부분의 현대 파일 시스템은 어떤 방식으로든 저널 기법을 사용하고 있다.
최근에는 시스템상에서 코어의 수가 늘어남에 따라 파일시스템에 동시에 접근하여 I/O를 수행하는 쓰레드의 수 또한 증가하고 있다. 하지만, 대부분의 파일시스템은 다양한 병목 지점들 때문에 쓰기 작업 수행 과정에서 낮은 스케일러빌리티를 보여왔으며, 저널 계층이 그러한 병목 중 하나로 지적되었다. 이것은 파일시스템에서 쓰기 요청들이 수행될 시 단 하나의 저널로만 모여 처리되기 때문에 발생한다.
본 연구에서는 매니코어 시스템 환경에서 수많은 어플리케이션들이 동시에 쓰기 작업을 수행할 때 최적의 저널 쓰기 확장성을 제공하는데 활용될 수 있도록 저널 영역을 코어별로 두어 처리하는 기법을 연구한다.
연구 내용
코어별 저널 구조
제안하는 코어별 저널인 jet-journal에서 각 코어는 저장 장치에 자신만을 위한 저널 영역을 가지고 있고, 커밋(commit) 작업을 처리하는 kjournald 또한 각자 가지고 있다. Jet-journal에서는 기존 리눅스 커널에서 사용되는 저널인 JBD2에서와 같이 데이터들을 한 번에 모아서 처리하는 단위인 트랜잭션(transaction)을 보유한다. 또한, 각 코어의 저널 스택은 데이터들이 모으는 러닝(running) 상태의 트랜잭션, 모인 데이터들을 저널 영역에 작성하는 커밋팅(committing) 상태의 트랜잭션, 저널 영역에 적힌 데이터들을 파일시스템의 원래의 영역에 옮겨적는 체크포인팅 (checkpointing) 상태의 트랜잭션을 가지고 있으며, 각 트랜잭션들은 JBD2와 동일한 순서로 작동한다.
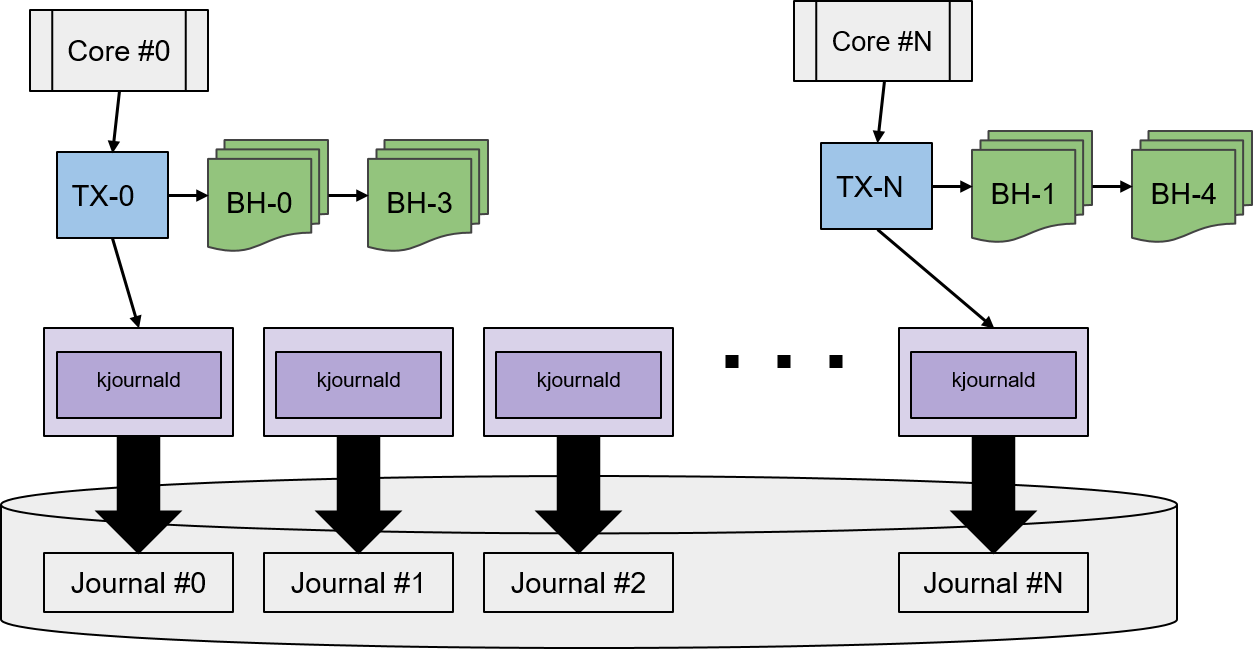
위 그림은 jet-journal의 코어별 저널 처리를 나타낸 것이다. 각 코어는 쓰기 작업 수행으로 수정한 데이터(BH)들을 각자의 러닝 상태의 트랜잭션에서 처리하면 되기 때문에, 쓰레드들은 저널에대한 접근 권한을 얻기 위해 다른 쓰레드와 경쟁할 필요가 없다. 뿐만아니라 kjournald들은 병렬로 커밋할 수 있기 때문에 jet-journal은 고성능 저장 장치가 가진 다수의 채널들을 충분히 활용할 수 있다.
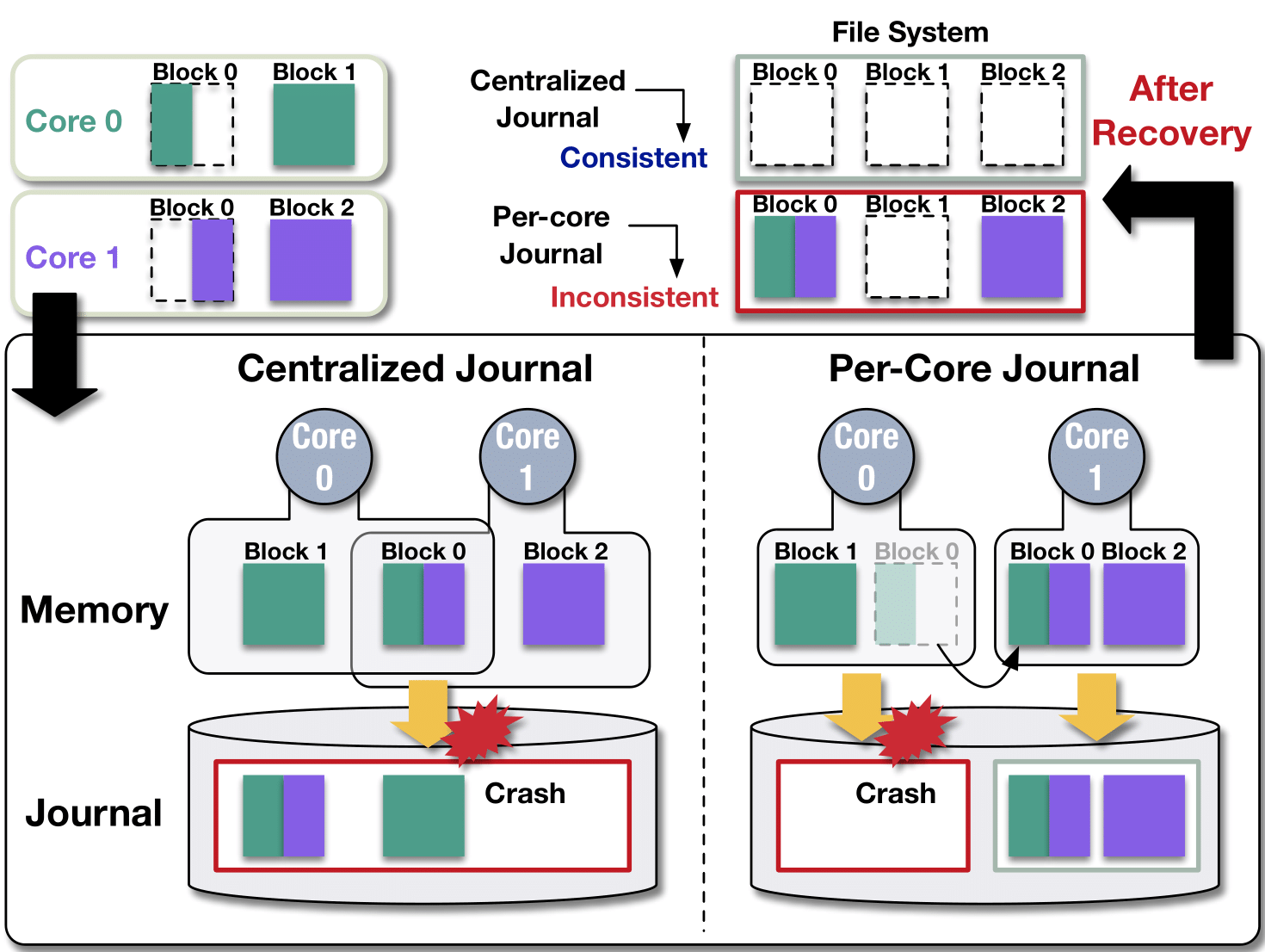
그러나 이러한 코어별 저널은 두 개 혹은 그 이상의 쓰레드가 동시에 같은 파일 시스템의 블록에 대해서 쓰기를 수행한다면, 메모리상에서의 데이터와 스토리지의 저널에서의 데이터가 달라질 수 있어 데이터의 일관성이 유지되지 못하고 파일의 데이터가 깨질 수 있다. 예시를 위해 코어0이 블록 0과 1을, 코어 1이 블록 0과 2를 이야기한 순서대로 수정한다고 가정하자. 위 그림은 해당 시나리오를 중앙화된 저널과 코어별 저널에서 수행했을 때, 갑작스러운 시스템 충돌 시 데이터가 어떻게 남아있는지를 보여주고 있다. 그림 우측의 per-core 저널에서는 커밋이 서로 독립적으로 발생하기 때문에 코어 1의 커밋이 먼저 완료될 수 있다. 만약 코어 1은 커밋이 완료되었는데 코어 0이 커밋 되지 않은 상태로 충돌이 발생했다면, 저널 레이어는 코어 1의 데이터들만을 복원하고 코어 0의 데이터는 복원하지 않을 것이다. 그러나 블록 0는 메모리에서의 수정 순서에 의해 커밋 되지 않은 코어 0의 수정사항 일부분을 포함한 상태로 복원이 진행 된다. 이러한 일관성 붕괴의 상황은 그림 좌측의 기존 중앙화 되어있는 저널에서는 발생하지 않는다.
저널 일관성 매커니즘
우리가 제안하는 jet-journal에서는 스케일러빌리티의 향상을 위해 코어별로 저널을 두면서도 인메모리 수정과 커밋하는 순서가 서로 일치하지 않아 발생하는 일관성 붕괴 문제를 해결하기 위해 순서 보전 트랜잭션 체이닝 방식을 사용한다.
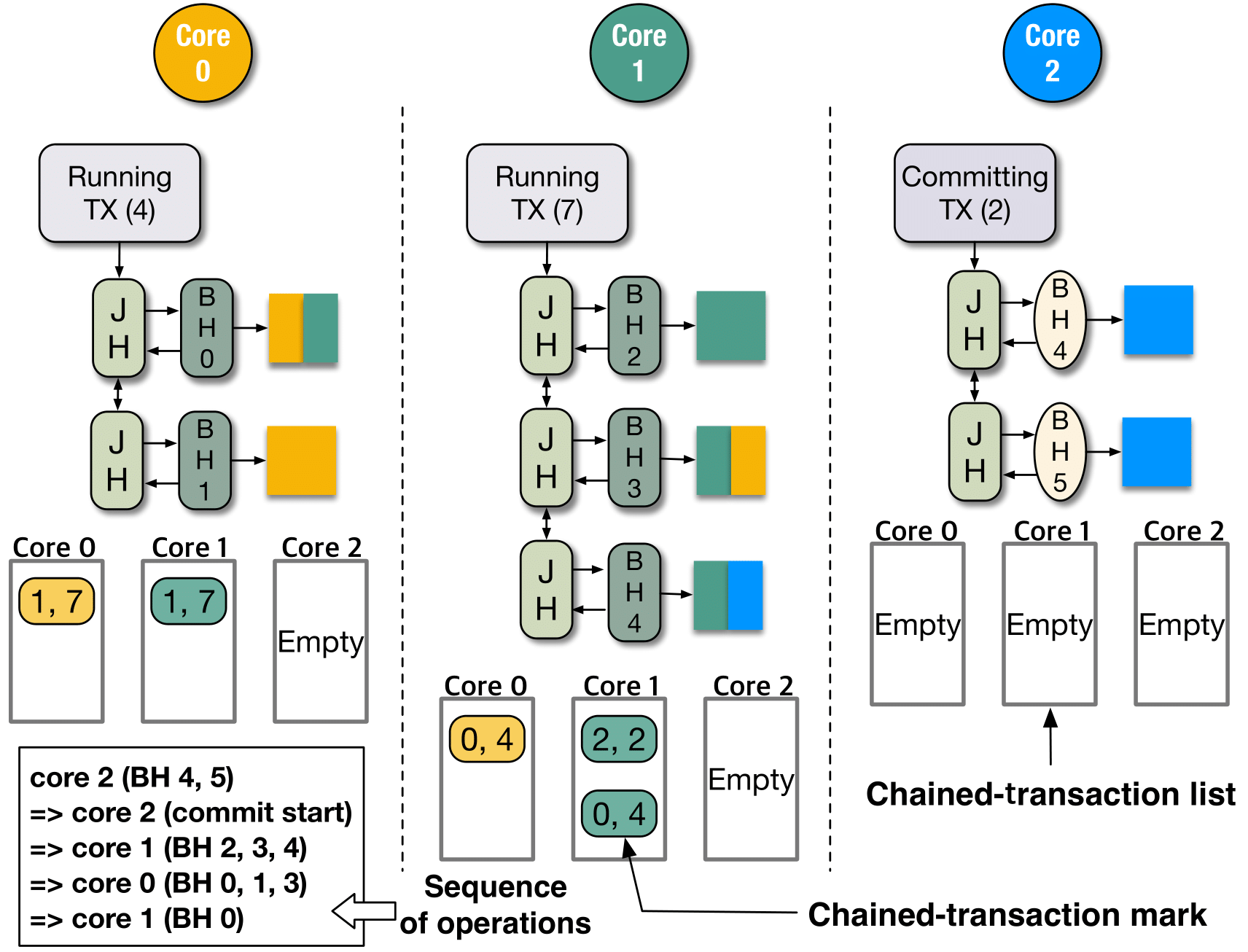
위 그림은 코어가 3개인 상황에서 왼쪽 아래에 적힌 순서대로 데이터(BH)가 수정될 때의 jet-journal에서의 모습을 나타낸 것이다. 데이터는 앞서 이야기했듯 트랜잭션(TX)이라는 단위로 묶여서 관리가 되며, 모두 트랜잭션들은 각자 일관성 보장을 위한 리스트들을 시스템상의 코어의 개수만큼 가지고 있다(위 그림에서는 트랜잭션마다 3개의 리스트를 가진다). 이 리스트는 chained mark를 포함하고 있는데, 각 chained mark는 지금 돌아가고 있는 데이터들이 일관성이 붕괴되지 않으려면 다른 코어의 어떤 TX들이 커밋 완료되어 있어야 하는지를 (코어의 번호, TX의 번호) 형태로 표시해주기 위해 존재한다.
먼저 정해진 순서에 따라 코어 2의 BH4, BH5가 수정되고, 전체 시스템에서 제일 처음으로 수정된 것이므로 코어 2의 저널에 매달아준다. 그 뒤 코어 2는 커밋을 시작하고 자신에게 매달린 BH들을 스토리지의 저널영역에 적기 시작한다. 이때 기존과는 다르게 jet-journal에서는 항상 BH를 복사하여 저널에 적어주어, 커밋 중에 다른 코어가 내가 처리 중인 BH에 접근하더라도 데이터를 수정해줄 수 있도록 한다. 따라서 코어 1이 BH 2, 3, 4를 수정할 시 BH4는 코어2에서 커밋 중이더라도 수정할 수 있다. 다만, 코어 1이 코어 2보다 먼저 커밋 완료되었을 때, 일관성이 붕괴되도록 하지 않기 위해 코어 1에 (2, 2) chained mark를 넣어준다. 이를 통하여 코어 1의 BH4는 아무리 커밋되었더라도 코어 2의 데이터가 커밋 완료되어 있어야만 복원할 수 있으며, BH4의 파란색 데이터는 항상 BH5와 함께 복원될 수 있게 된다.
코어0가 BH 0, 1, 3을 수정할 때, BH3은 이미 코어 1에 속한 상태이면서, 위의 경우와는 다르게 아직 커밋을 시작하지 않은 상황이다. 이때는 BH3의 입장에서도 코어 0에 있는 BH0과 BH1이 필요하고, BH0과 1의 입장에서도 코어 1에 있는 BH3이 필요한 상황이다. 따라서 코어 1에는 (0, 4)를, 코어 0에는 (1, 7)을 리스트에 넣어준다. 마지막에 실행되는 코어 1의 BH 0의 수정 때도 위와 똑같은 형태로 처리되어진다. 모든 mark들은 자신을 삽입해야 하는 작업을 수행한 코어의 번호를 가진 리스트들에 삽입된다. 따라서 락이 없이도 처리할 수 있지만 중복이 존재할 수 있다.
위와 같은 기법들을 통하여 jet-journal은 충돌 시 일관성을 보장하면서도 스케일러블한 코어별 저널을 유지할 수 있다.
코어별 저널의 복원 기법
저널 영역에 저장된 커밋 트랜잭션에는 디스크립터(descriptor) 블록, 데이터 블록, 커밋 블록의 세 가지 블록이 존재한다. 다음 데이터 블록에 대한 정보를 저장하는 트랜잭션 디스크립터 블록은 커밋된 트랜잭션의 맨 앞에 위치한다. 다음으로 데이터 블록이 저장된다. 마지막으로 커밋 블록은 커밋의 성공적인 완료를 나타내기 위해 작성된다. 위 세가지 종류의 블록 구성은 기존 JBD2와 동일하다.
Jet-journal에서 커밋 블록은 순서 보전 트랜잭션 체이닝 방식으로 연결된 트랜잭션들의 목록도 저장한다. 또한 커밋 블록에는 여러 저널에 걸쳐 트랜잭션의 순서를 파악하기 위해 트랜잭션이 커밋을 시작한 시간의 타임스탬프를 포함한다.
복구 시 먼저 모든 저널에서 커밋 블록이 적혀있는 트랜잭션들을 검색하여 유효한 트랜잭션을 찾는다. 그 후에, 커밋 블록에 적힌 체인 트랜잭션 목록에 근거하여 트랜잭션의 순서 그래프를 만든다. 그렇게 만들어진 그래프의 노드를 하나씩 검사하여 유효한 트랜잭션들을 찾아낸다. 마지막으로 유효한 트랜잭션의 최신 데이터를 사용하여 파일 시스템의 원래 위치에 블록을 업데이트한다.
실험 결과
실험 환경
리눅스 커널 내에 있는 ext4 파일시스템이 여러 개 저널을 가질 수 있도록 수정하였으며, Jet-Journal은 JBD2를 기반으로 수정하였다. 추가적으로 mke2fs 툴을 ext4가 코어별로 저널을 가지게 포맷하도록 수정하였다. Jet-Journal을 ext4에서 돌리는 것의 성능을 JBD2를 가지고 돌리는 것과 아예 저널이 없이 돌리는 것(No Journal)을 함께 비교하였다. 우리는 전체 파일시스템의 확장성 향상을 목표로 하는 것이 아닌, 저널 계층의 확장성 향상을 목표로 하기 때문에 저널을 없이 돌리는 ext4의 성능이 우리가 달성할 수 있는 가장 최고의 성능이다. 모든 실험은 저널의 데이터 모드로 설정 후 수행하였다.
블록의 공유 정도가 서로 다른 조건에서 파일 작업을 수행할 때 Jet-Journal의 확장성을 평가하기 위해 FxMark를 사용했다. FxMark의 쓰기 워크로드는 덮어쓰기와 파일 생성을 각각 낮은 공유 정도와 높은 공유 정도에서 실행할 수 있다. 낮은 공유 조건에서 각 코어들은 서로 자신만의 폴더와 파일에 대해 파일시스템 작업을 수행한다. 높은 공유 조건에서 덮어쓰기 워크로드는 모든 코어가 동일한 파일에 접근하여 서로 다른 블록들을 덮어쓰는 작업을 수행한다.
낮은 블록 공유 정도
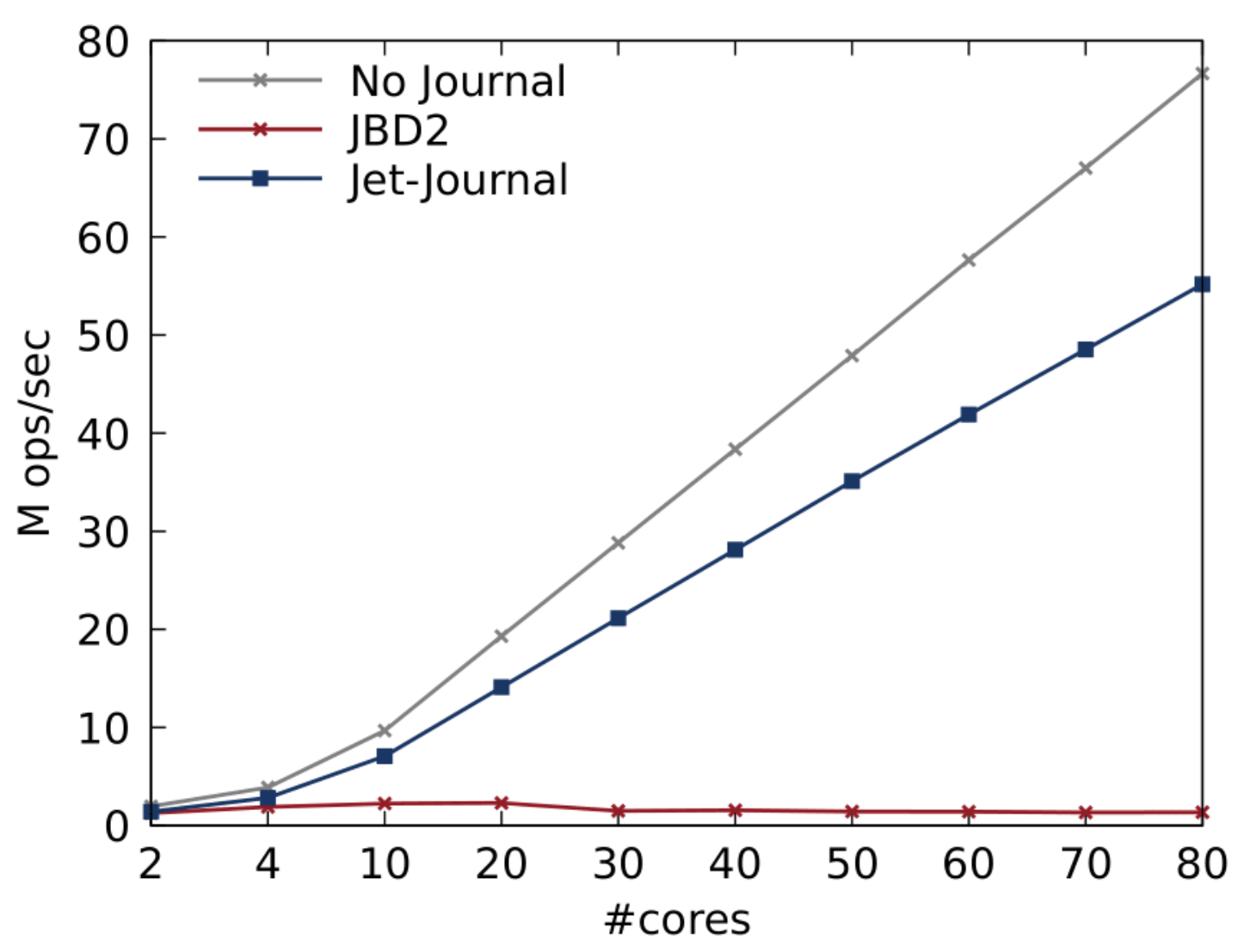
위 그림은 FxMark의 낮은 공유 정도를 가진 덮어쓰기 워크로드의 실험 결과를 보여준다. JBD2 대비 Jet-Journal이 가장 유리한 조건은 파일시스템 자체에서는 확장성 있게 작업할 수 있지만 저널 계층에서만 병목이 존재하는 상태이다. 낮은 공유 정도의 덮어쓰기는 메타데이터를 거의 수정하지 않으며, 코어가 아닌 디렉토리에 저장된 파일의 데이터 블록에 자주 쓰기를 한다. 따라서 FxMark에서 가장 유리한 작업량이다. 그러므로, Jet-Journal은 저널에 한 번 더 쓰기에 의해 발생하는 오버헤드 때문에 성능이 저하되는 것을 제외하고 저널이 없는 것에 가까운 성능을 보였으며 코어 수가 늘어날 수록 성능이 잘 향상되는 모습을 보였다. 결과적으로, Jet-Journal은 80개 코어에서 JBD2보다 40배 높은 처리량을 보였다.
높은 블록 공유 정도
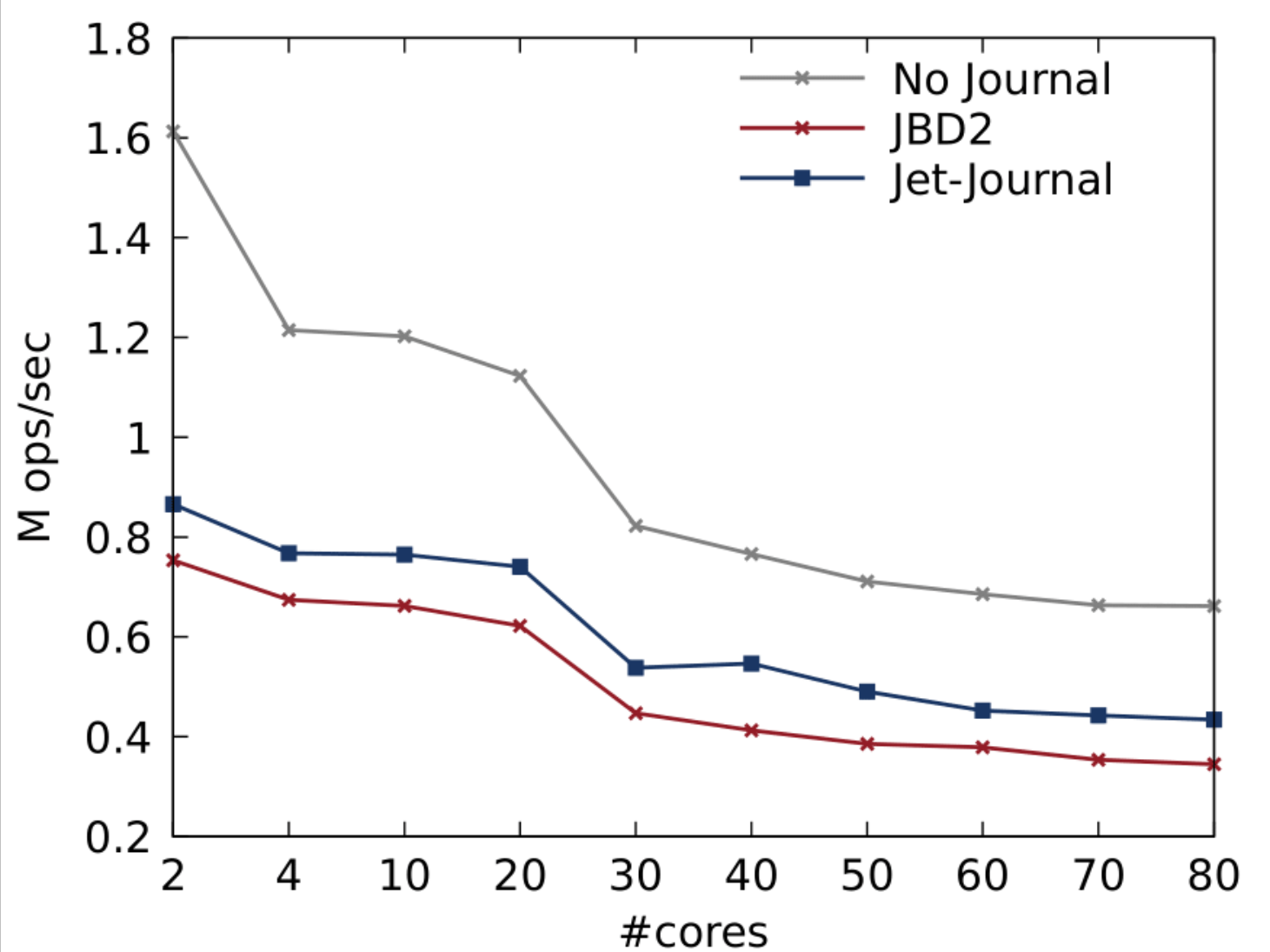
위 그림은 FxMark의 중간 공유 정도를 가진 덮어쓰기 워크로드의 실험 결과를 보여준다. 낮은 공유 때와는 다르게 블록의 공유로 인해 파일 시스템 자체의 확장성이 떨어지는 결과를 가지며, 저널 계층의 성능도 같은 이유로 저조하게 나타났다. 그러나, 이 경우에도 Jet-Journal은 병렬적으로 수행하는 커밋 메커니즘을 통해 80개 코어에서 JBD2 대비 26%의 성능 향상을 보였다.
연구 결과물
- 논문
- 공개 소프트눼어
- Github: jet-journal
- Github: Z File-browser
- 시연 동영상