비휘발성 메모리 파일시스템 기초연구
연구 개요
단일 프로세서 사용을 전제로 설계된 미닉스(Minix)를 기반하여 개발되기 시작한 리눅스(Linux)는 처음 개발 당시 미닉스 파일시스템을 지원하였다. 이후 성능상의 문제로 인하여 1992년부터 확장된 파일 시스템(extended file system)을 지원하기 시작하였다. 확장된 파일시스템은 가상 파일시스템(virtual file system)을 사용하기 시작한 첫 번째 리눅스 파일시스템 이었다. 가상 파일시스템의 채용으로 인해 리눅스에서는 동시에 여러 종류의 파일시스템을 사용할 수 있게 되었다.
최초의 확장 파일시스템은 최대 2GB(gigabyte) 크기의 파일시스템을 지원하였다. 두 번째 확장 파일시스템(ext2)의 2TB(terabyte) 크기 지원을 시작으로 커널 버전 2.6에서는 32TB 크기까지 지원였고 세 번째 확장 파일시스템(ext3)은 파일복구에 필요한 저널링 기능을 지원하기 시작하였으며, 네 번째 확장 파일시스템(ext4)은 성능과 확장성, 신뢰성 등에서 많은 발전을 이루며 1EB(Exabyte) 크기의 파일시스템을 지원하게 되었다. 네 번째 확장된 파일시스템은 JFS, XFS, ZFS 등 여러 파일시스템의 장점을 반영하여 개발되었다.
파일시스템의 빈번한 사용은 장애가 발생에 잘 대처할 수 있는 기능이 요구되기 시작하였다. 이러한 요구 사항을 만족 시키기 위하여 여러 가지 저널링 기법을 사용하는 다양한 파일시스템이 등장하게 되었다. IBM에서 처음 개발한 조금씩 변화 내용을 기록하는 파일시스템(Journaled File System)은 1990년 공개되었고, 리눅스에서는 보다 개선 발전된 JFS2를 지원하고 있다. 1994년 실리콘 그래픽스사에서 IRIX 운영체제에서 사용하기 위해 소개한 고성능의 XFS는 2001년 리눅스용으로 지원되기 시작했다. 똑똑한 파일시스템(Smart File System)은 1998년 아미가사에서 개발되었고 LGPL(GNU Lesser General Public Licence)로 2005년 리눅스를 지원하기 시작하였다. 세 번째 확장된 파일시스템(ext3)은 두 번째 확장된 파일시스템(ext2)에 변동 내용을 조금씩 기록하는 기능을 추가한 것으로 2001년부터 리눅스에서 지원되기 시작하였다.
가상 파일시스템은 빠른 메모리를 파일 캐시로 사용하여 느린 저장 장치 사용으로 인한 성능 손실을 보완할 수 있게 하였으나, 매니코어 환경을 염두에 두고 개발이 진행되지는 않았다. 즉 하드웨어 기술이 발달함에 따라 단일 시스템에서 사용 가능한 코어의 개수가 증가하고 있으며, 빠른 저장 장치의 사용으로 인한 성능 개선 연구가 많이 부족한 실정이다.
본 연구는 빠른 비휘발성 메모리를 사용하는 저장장치를 사용하는 파일시스템 구현을 통해 매니코어 환경에서 최적의 파일 처리 성능을 얻기 위해 요구되는 것을 도출하고 적용하여 프로토타입의 파일시스템을 구현하였다. 매니코어 환경의 리눅스 시스템에서 코어수 증가에 따라 성능 향상이 가능한 파일시스템을 프로토타입 수준으로 구현하여 다양한 실험을 통하여, 성능 증진에 필요한 요소를 추가로 확인하였으며 매니코어 기반의 확장성이 좋은 파일시스템이 될 수 있음을 확인하였다.
방향
- 매니코어 시스템의 코어 개수가 증가하면 파일처리 성능도 증가하는 확장성 있는 고성능 파일시스템에 대한 연구
- 연구 내용을 기반으로 새로운 하드웨어 환경에 적합한 파일시스템 제안
- NUMA환경에서 메인메모리버스에 연결된 빠른 저장장치에 최적화된 파일시스템을 설계하고 프로토타입의 파일시스템 구현
배경
컴퓨터 시스템에서 사용가능한 저장장치의 속도가 비약적으로 개선되어가고 있다. 그러나 운영체제의 파일 처리 과정은 느린 저장 장치 사용환경에 최적화 되어 있다. 따라서 빠른 저장장치의 성능을 최대한 활용하기 위해서는 이에 적합한 파일시스템의 연구를 포함한 파일 처리 과정(Virtual File System, Block IO Layer)의 변화가 요구된다.
- 다양한 저장장치
HDD(Hard Disk Drive)와 같은 느린 저장 장치를 사용할 때 파일 처리 성능을 높이기 위하여 운영체제에서는 느린 저장장치에 보관되어 있는 데이터의 일부를 빠른 저장장치인 DRAM(Dynamic Random Access Memory)에 잠깐동안 저장하는 캐싱 기법을 사용하여 왔다. 리눅스에서는 파일의 데이터와 파일의 정보를 저장하는 메타 데이터를 pagecache, i-cache, d-cache에 저장하여 사용하였다.
플래시 메모리와 같은 비휘발성 메모리를 사용하는 SSD(Solid State Disk)와 같은 저장 장치의 사용으로 기존 HDD(Hard Disk Drive)에 비해 빠른 처리가 가능해졌으나 읽기와 쓰기 속도가 다르고 저장 수명에 제한이 있다.
NVDIMM(Non-Volatile Dual In-line Memory Module)과 같이 컴퓨터의 주기억 장치로 쓰이는 휘발성 메모리인 DRAM(Dynamic Random Access Memory)과 같은 특성을 갖는 저장장치의 등장은 고성능의 확장성 있는 파일처리를 가능한 환경 요소가 되고 있다.

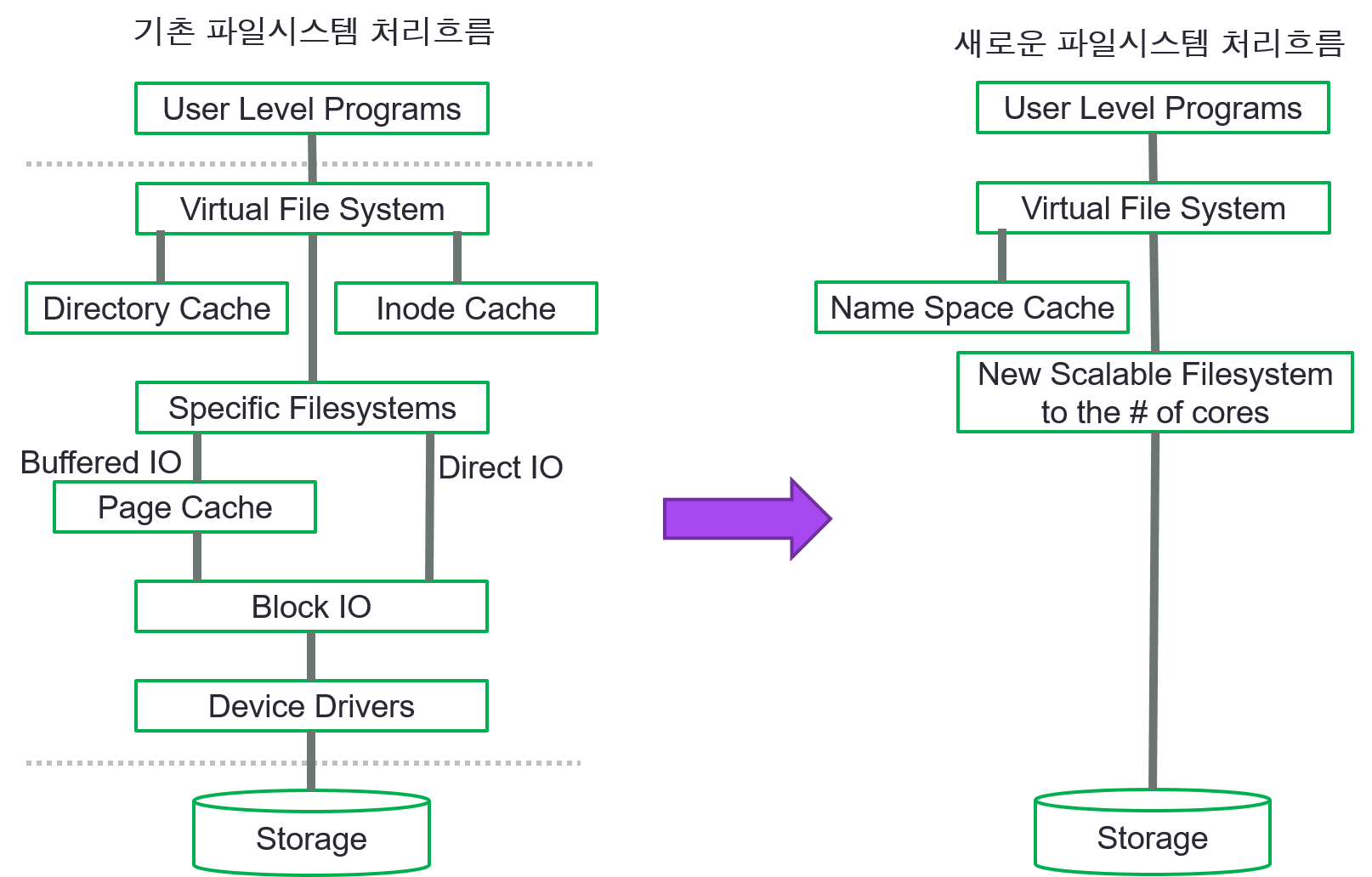
- 기존 파일시스템 처리 경로와 새로이 제안하는 파일시스템 처리 경로
리눅스에서는 아래 그림의 왼쪽과 같이 파일 처리를 위해 다양한 캐시를 사용하고 있다. 빠른 메인 메모리를 캐시로 사용함으로써 느린 저장 장치 사용으로 인해 발생하는 성능 손실을 보완하여 왔다. 메인메모리와 같은 빠 저장 장치를 사용할 경우에는 이러한 페이지 캐시의 사용이 오히려 성능을 떨어뜨리는 요인으로 작용을 한다. 따라서 본 연구에서는 오른쪽과 같이 페이지 캐시를 사용하지 않는 경로 사용을 제안한다.
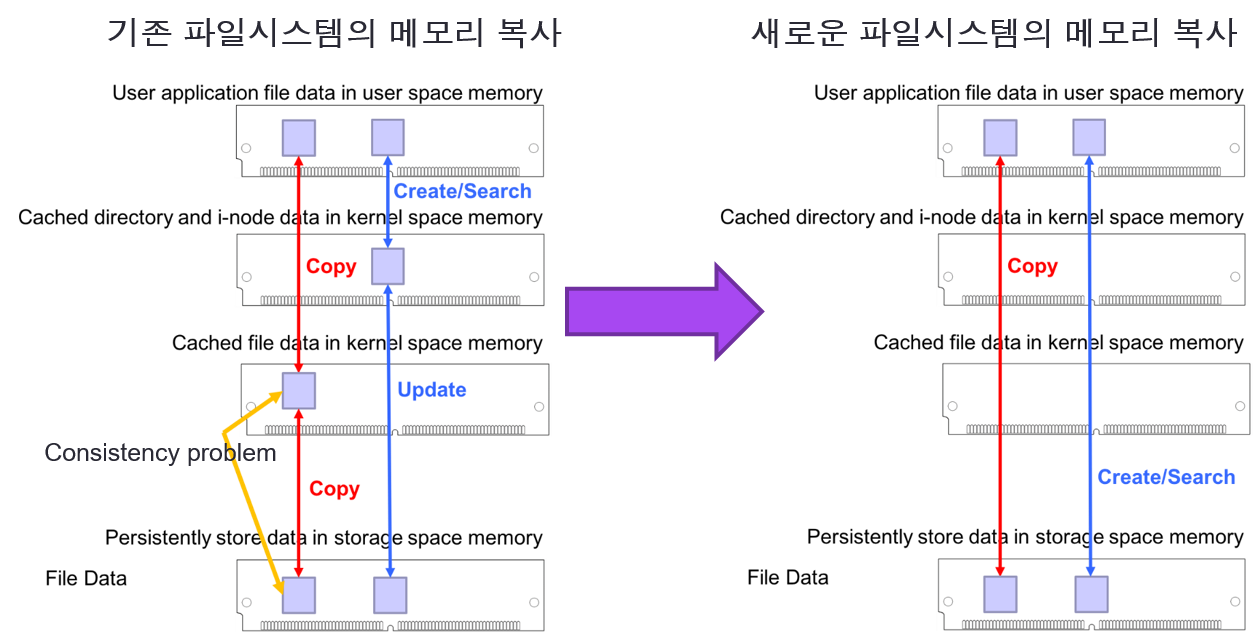
- 기존 파일시스템 처리 경로에서의 메모리 복사와 새로이 제안하는 파일시스템 처리 경로에서의 메모리 복사
페이지 캐시를 사용할 경우 아래 그림의 왼쪽과 같이 페이지 캐시에 기록 될 때와 저장 장치에 기록 될 때 각각 복사 과정이 필요하다. 느린 저장 장치를 사용할 경우에는 이러한 기법을 적절하게 사용함으로써 빠른 저장 장치를 사용하는 것과 같은 효과를 통해 시스템 성능을 개선시킬 수 있지만, 메인메모리와 동등한 성능을 같는 NVDIMM과 같은 저장 장치를 사용할 경우에는 불필요한 복제 과정으로 인해 오히려 성능을 떨어뜨리는 요인이 된다. 따라서 오른쪽 그림과 같이 캐싱 과정을 거치지 않고 직접 저장 장치 접근을 통해 파일 처리를 하는 것이 성능상 유리하다.
기초 실험 (파일 입출력 경로상의 병목 지점 관련 연구)
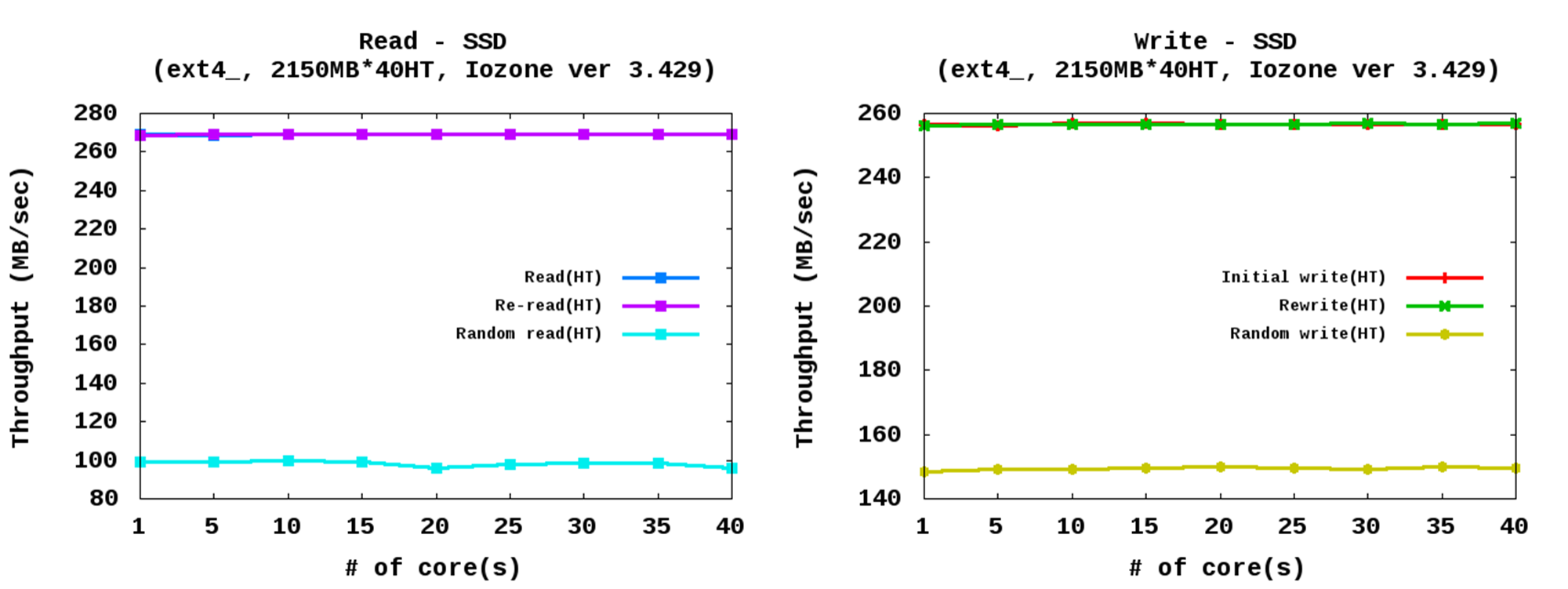
- SATA 연결의 SSD
코어 개수 변화에 큰 영향을 받지 않음 - 아래의 실험 결과는 페이지 캐시를 사용하지 않는 조건에서의 실험 결과 이며, SATA버스를 통해 연결되는 SSD의 하드웨어 경로와 저장 장치 특성에 의해 코어 개수가 증가하여도 성능의 변화가 관찰되지 않았다.
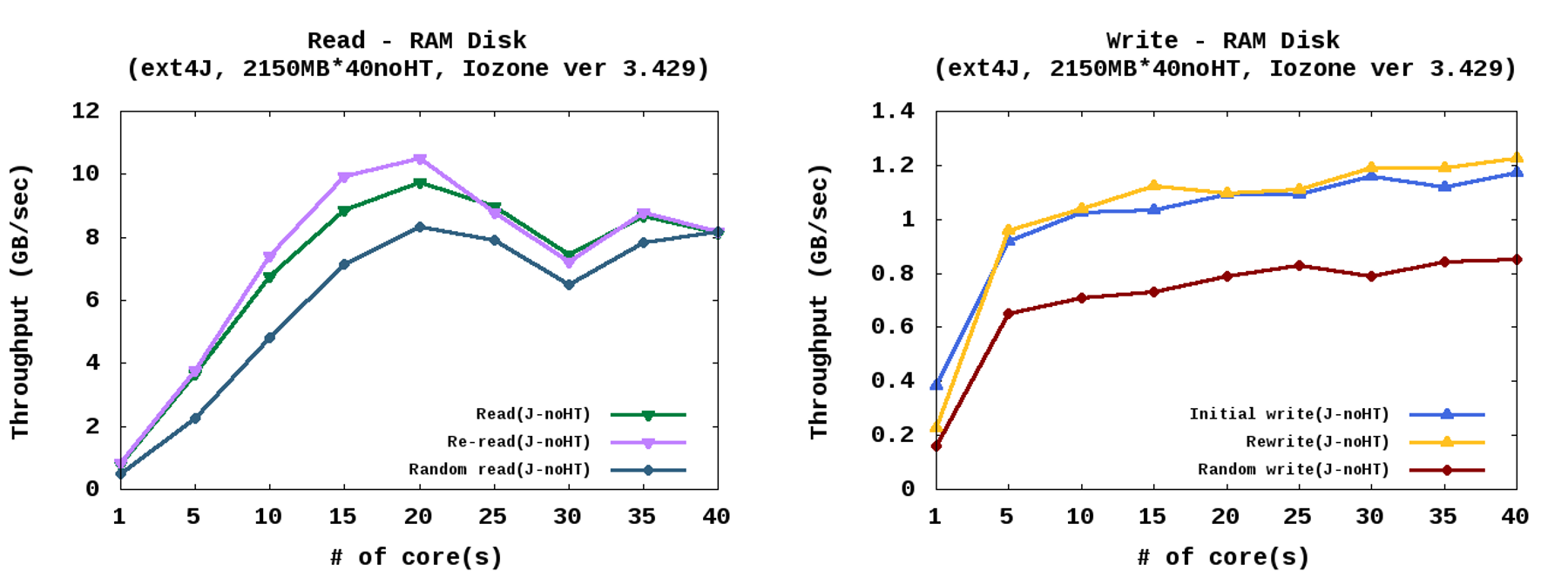
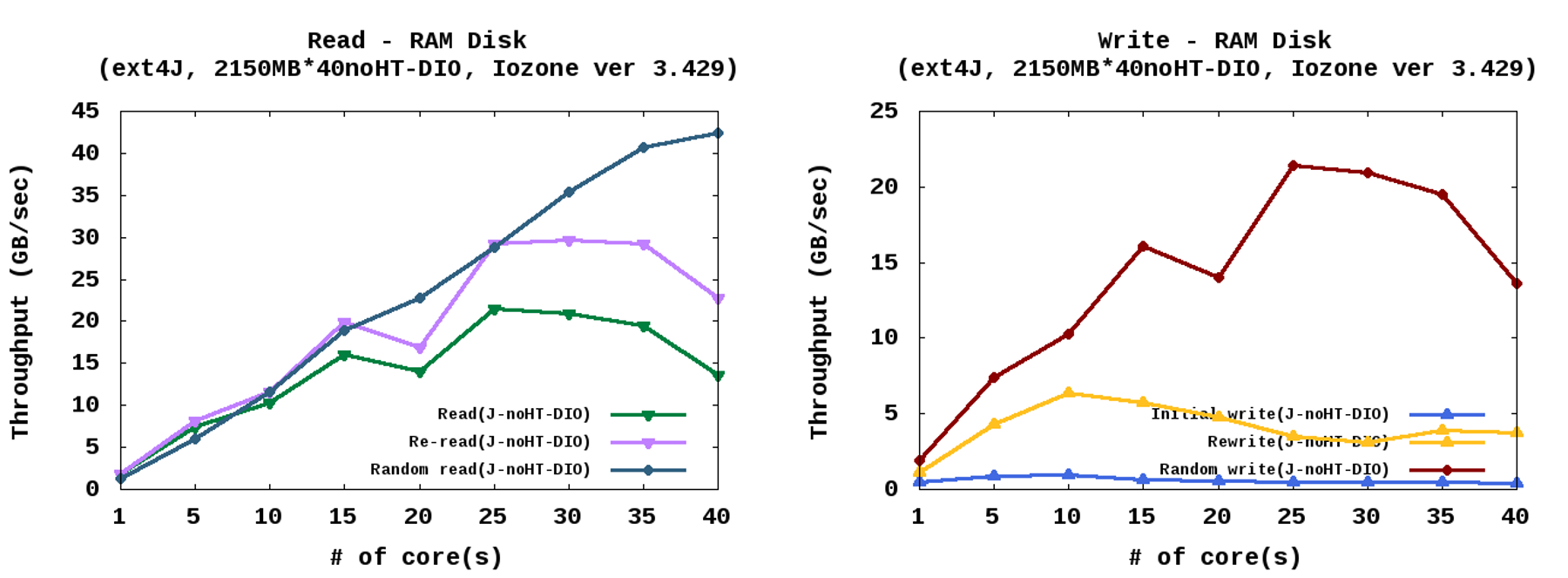
- RamDisk를 사용한 EXT4(페이지 캐시 사용)
코어 증가에 따라 성능도 증가하는 모습 - 빠른 메인메모리를 저장 장치로 활용하는 기법 중 하나인 ramdisk를 이용하고 페이지 캐시를 사용하여 실험하였을 경우 아래 그림과 같이 코어 증가에 따라 성능 변화가 관찰되었다. 읽기 실험에서 성능이 떨어지는 부분은 NUMA구조의 시스템에서 메인메모리를 저장 장치로 사용하였기 때문에 나타나는 현상이다.
- RamDisk를 사용한 EXT4(Direct IO)
페이지 캐시를 사용하는 경우 보다 성능이 높게 관찰됨 - ramdisk를 사용하여 직접 저장 장치에 읽고 쓰기 실험을 하였을 경우 페이지 캐시를 사용하였을 때보다 높은 성능을 보여주는 것이 확인 되었다. 또한 임의로 읽고 쓰기에서 확인된 높은 성능은 저장 장치 특성을 잘 설명해 주고 있다.
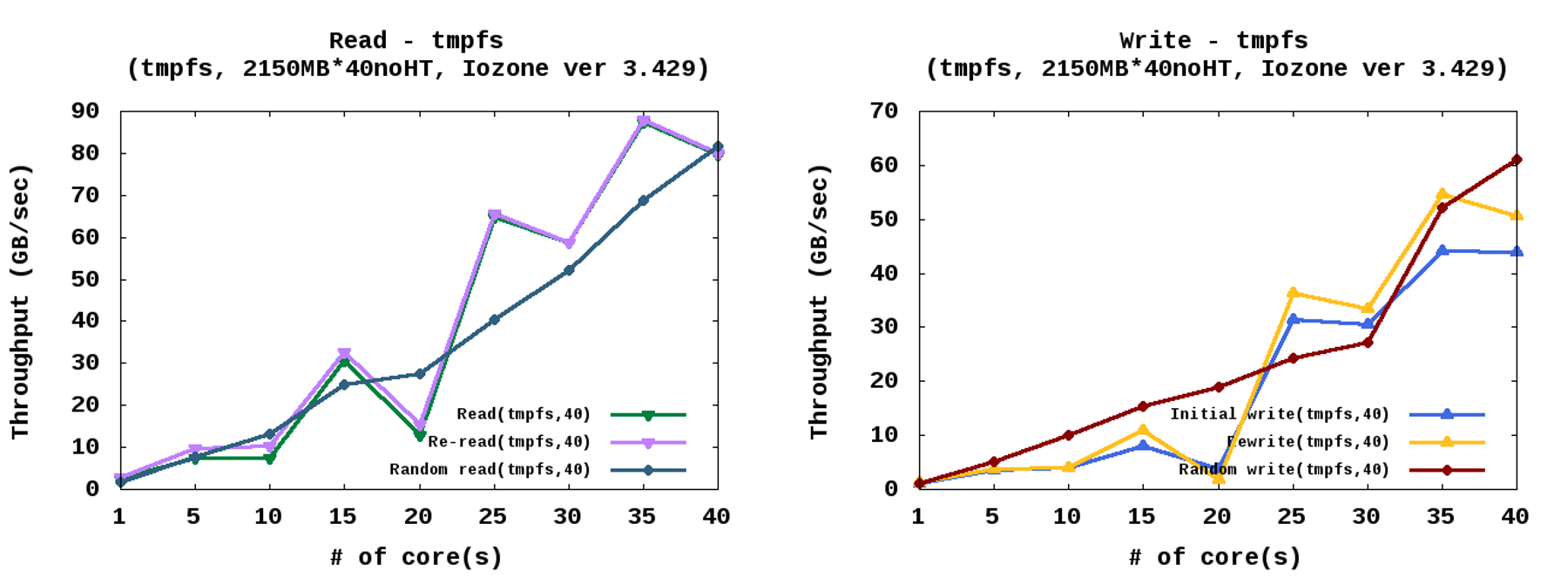
- 블록 입출력이 없는 tmpfs
가장 높은 성능이 관찰됨 - 빠른 메모리를 저장공간으로 사용하는 기법 중의 하나인 tmpfs의 경우, 페이지 캐시에 파일을 저장하고 최종 저장 장치에 기록하는 과정이 없다. 위의 실험 결과와 비교할 때, 복잡한 블록 입출력 과정이 제거된 것으로 기초 실험 중 가장 높은 성능 결과를 보여 주었다.
심화 실험 (NUMA 효과를 최소화하기 위한 코어 배치를 했을 경우 성능 실험)
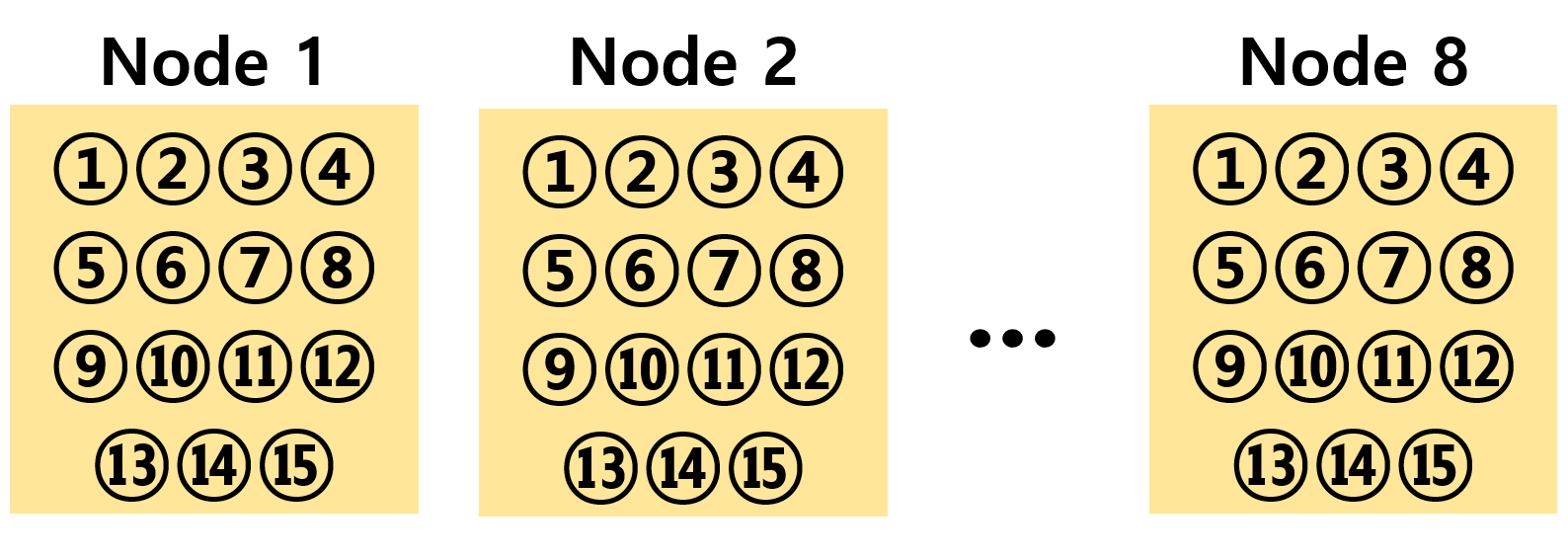
- 코어 개수 증가 방법
※아래 그림의 번호와 같이 각 노드의 활성화 코어 개수를 동일하게 하여 전체 코어 개수가 증가하게 하여 실험을 실시-노드별 활성화 된 코어 개수를 동일하게 한 실험으로, 노드 증가에 따른 NUMA효과를 최소화 하기 위한 실험 구성이다.
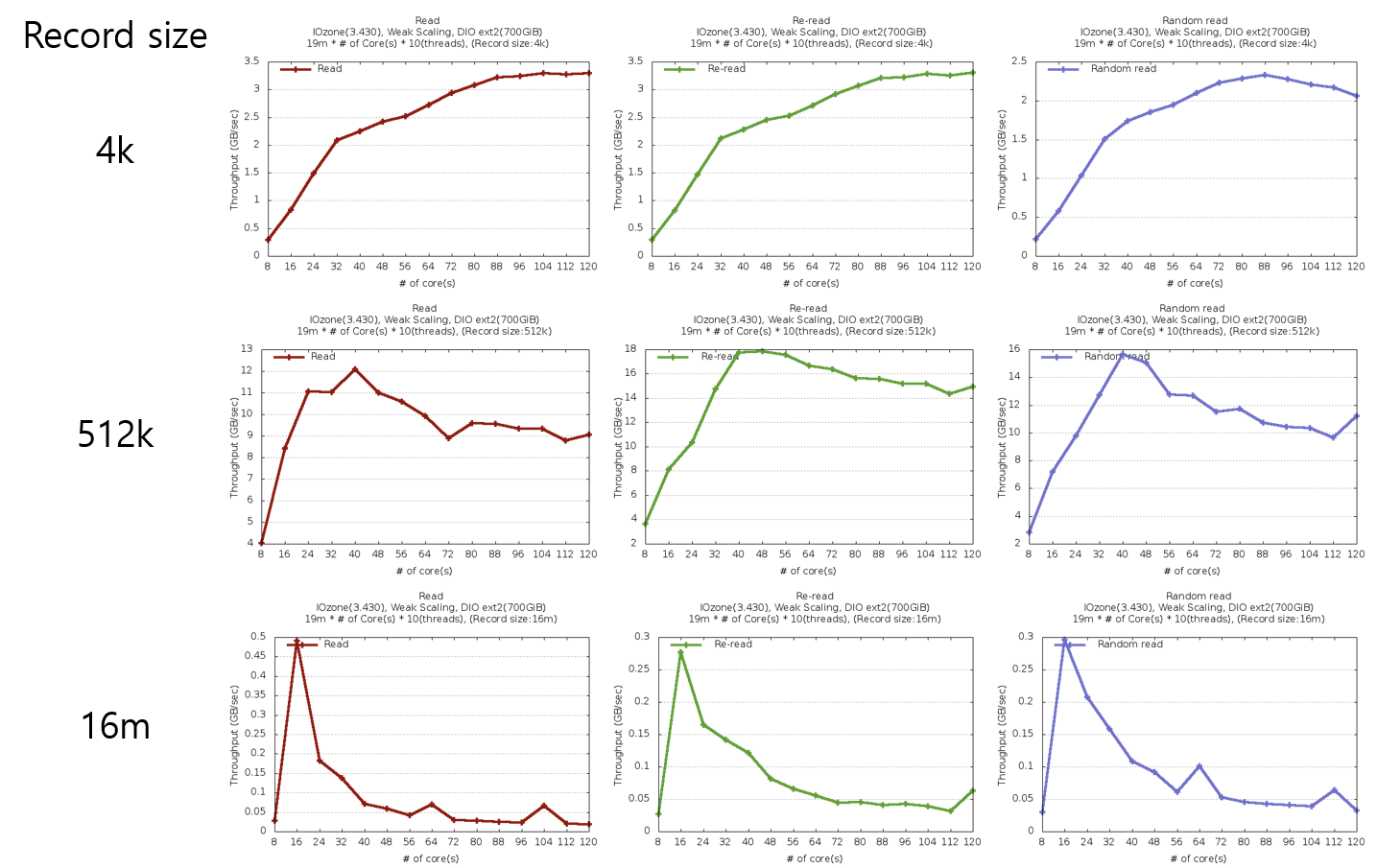
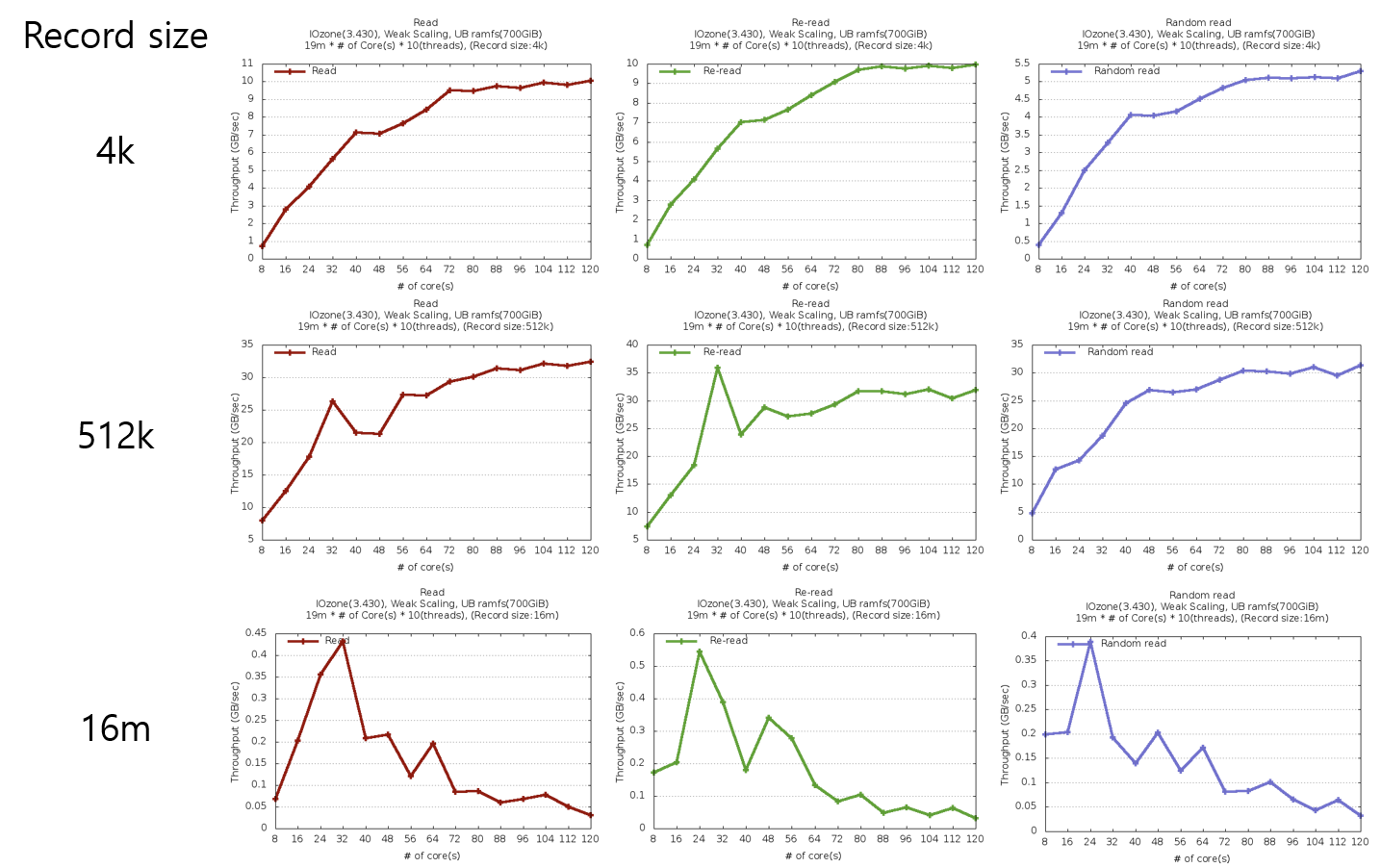
- RAMdisk에서 EXT2파일시스템을 사용하여 직접 입출력(Direct IO)으로 실험하였을 경우
레코드 크기가 4KB일 경우 확장성이 관찰되지만, 최고 성능은 512KB에서 관찰됨 - 4KB 단위로 파일을 읽을 경우 하드웨어의 최고 성능에 도달하지 않아 120코어를 모두 사용하였어도 최고치에 비해 성능 차이가 많지 않았다. 그러나 512KB단위로 파일을 읽을 경우 최고치 도달이후 자원 경쟁으로 인한 락 문제로 인해 성능이 떨어졌으나, 최고치 성능은 가장 높았다. 16MB단위 실험에서는 가장 낮은 성능 결과를 관찰 하였는데, 이는 CPU 캐시 미스율 증가로 인해 발생하였다.
- tmpfs를 사용하여 실험하였을 경우
레코드 크기가 4KB일 경우와 512KB일 경우 확장성이 관찰되고 성능은 512KB일 때가 더 높게 관찰됨 - ramdisk를 사용하였을 때에 비해 최고 성능는 높았으나, 비슷한 패턴의 결과를 보여주었다.
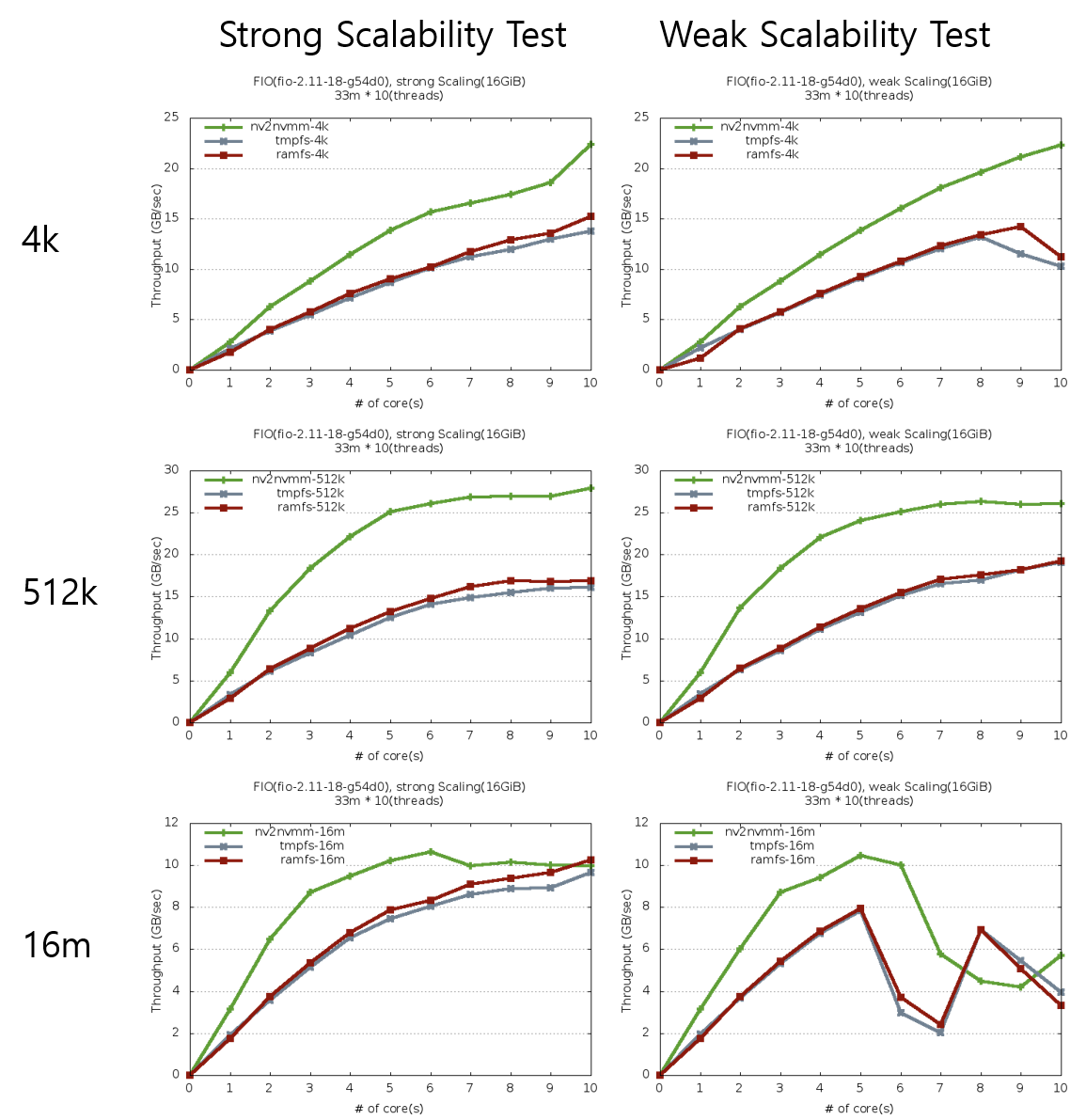
제안하는 파일시스템 에뮬레이션
단일노드
How to Emulate Persistent Memory on an Intel® Architecture Server
인텔의 Persistent Memory Emulation Platform(PMEP)를 사용하여, 메타데이터와 파일데이터를 직접 비휘발성 메모리 저장장치에 쓰거나 읽음
- 성능 측정 실험 결과
fio를 사용하여 실험한 결과 1mb미만 크기 단위로 읽을 때는 기존의 tmpfs, ramfs 보다 높은 성능(녹색의 nv2nvmm)을 얻을 수 있었고 단일 노드에서는 확장성도 훨씬 좋은 것으로 확인되었다.
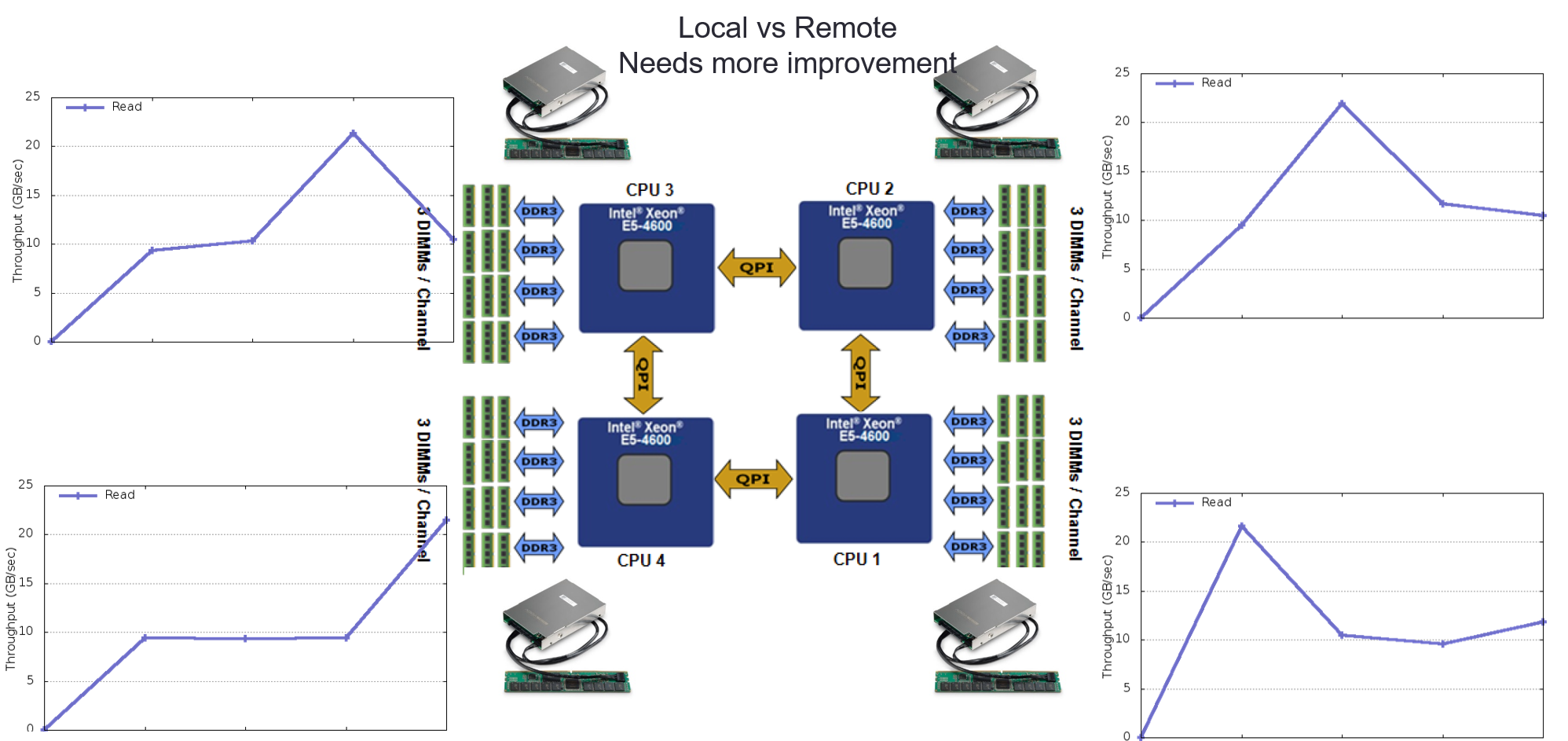
기존의 HDD나 SSD와 같은 느린 저장 장치를 사용하고 페이지 캐시를 사용하는 파일시스템에서는 저장 장치의 위치와 파일을 접근하는 프로세스가 위치한 노드간에 상관관계가 관찰되지 않았으나 메인메모리 버스에 연결된 빠른 저장장치를 사용하고 페이지 캐시를 사용하지 않는 제안하는 파일시스템의 경우 저장 장치의 위치가 파일 처리 성능의 주요 요인이 되는 것을 실험 결과를 통해 확인할 수 있었다.
저장공간 위치 친화도를 적용한 쓰기 최적화 파일시스템 (멀티노드, NUMA 시스템)
기존 파일시스템은 저장 공간에 파일 데이터를 저장하는데 주목 하였고, 파일 처리 성능은 페이지 캐시를 통해 개선하려고 하는 것이 주된 연구 방향이었다. 본 연구에서는 빠른 메모리 저장장치를 NUMA시스템에서 사용할 때, 메인 메모리 버스에 연결된 빠른 메모리 저장장치와 프로세스의 위치가 성능 결정의 주요 요소가 되는 것을 여러 실험 분석을 통해 확인할 수 있었고, 이를 바탕으로 새로운 파일시스템 프로토타입 구현을 통해 tmpfs에 비해 확장성 있는 파일 처리가 가능함을 실험 결과를 통해 확인 가능 하였다.
- 성능 측정 실험 결과
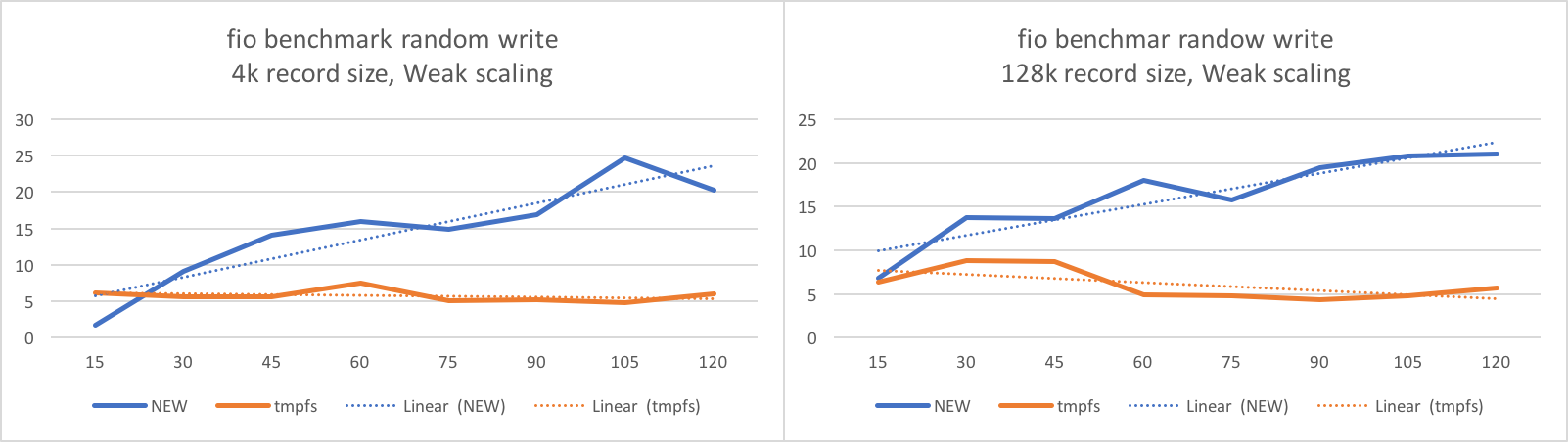
(위의 그림에서 가로축은 사용하는 코어 개수를 의미하며, 실험에 사용한 시스템은 15core의 CPU가 8개 있는 NUMA구조의 서버임)
결과물
- 논문
- U. Song, B. Jeong, S. Park, and K. Lee, "Performance Optimization of Communication Subsystem in Scale-out Distributed Storage",The 5th International Workshop on Autonomic Management of Grid and Cloud Computing (AMGCC 2017) in conjunction with IEEE International Conference on Cloud and Autonomic Computing (ICCAC 2017), September 2017.
- Jang Kim, Jae Kim, A. Khan, Y. Kim, and S. Park, "ZonFS: A Storage Class Memory File System with Memory Zone Partitioning on Linux",The 5th International Workshop on Autonomic Management of Grid and Cloud Computing (AMGCC 2017) in conjunction with IEEE International Conference on Cloud and Autonomic Computing (ICCAC 2017), September 2017.
- 김재훈, 이용섭, 박성용, "블록 저장 장치 특성에 따른 리눅스 블록 I/O 흐름 분석", 한국정보과학회, 2016 한국컴퓨터종합학술대회 (KCC 2016) 포스터 세션, 2016년 6월 29 – 7월 01일, 제주 ICC&부영호텔, 제주
- 이용섭, 박성용 "리눅스에서 메인메모리 저장소를 사용하는 파일 시스템 분석", 한국정보과학회, 2016 한국컴퓨터종합학술대회 (KCC 2016) 포스터 세션, 2016년 6월 29 – 7월 01일, 제주 ICC&부영호텔, 제주
- H. Kang, K. Jeong, K. Lee, S. Park, and Y. Kim, "Android RMI: A User-level Remote Method Invocation Mechanism between Android Devices", The Journal of Supercomputing, accepted to appear in 2016
- K. Lee and S. Park, "A CPU Overhead-aware VM Placement Algorithm for Network Bandwidth Guarantee in Virtualized Data Centers", The 3rd International Workshop on Autonomic Management of Grid and Cloud Computing (AMGCC 2015) in conjunction with IEEE International Conference on Cloud and Autonomic Computing (ICCAC 2015), accepted to appear in September 2015.
- Y. Lee, S. Park, "Linux File System Analysis over NUMA Based Servers", Poster Session at ISET 2015
- J. Lee, S. Jung, B. Kim, Y. Lee, S. Park, "A Device Aware Thread Placement Policy for NUMA-based Linux Servers", Poster Session at ISET 2015