스케일러블 자료구조 연구
연구 배경
최근 데이터의 생성량이 IoT, 자율주행 자동차 등으로 인해 폭발적으로 증가하고, AI/ML과 같은 데이터 소비가 많은 응용이 많이 생겨남에 따라, 효율적인 데이터 저장 방안 및 빠르게 데이터를 찾을 수 있도록 도와주는 자료구조 특히 인덱스 자료구조가 더욱 중요해지고 있다. 특히 매니코어 시스템에서의 확장성 있는 (Scalable)한 인덱스 자료구조를 활용하기 위해서는 효율적인 동시성 제어 알고리즘과 함께 인덱스 자료구조가 저장되는 저장장치의 특성을 효율적으로 활용할 수 있어야 한다. 최근의 인덱스 자료구조는 크게 기존의 DRAM을 효율적으로 활용하는 자료구조와 새롭게 등장한 영구메모리를 활용하는 인덱스 자료구조로 크게 나눌 수 있다. 하지만, DRAM용 인덱스 자료구조와 영구메모리용 인덱스 자료구조 모두 기존의 B+-tree 혹은 Trie 기반의 인덱스 자료구조의 한계에서 벗어나지 못하고 있는 상태이다. 본 연구에서는 DRAM과 영구메모리에서 효율적으로 동작하는 DRAM용 인덱스 자료구조와 영구메모리용 인덱스 자료구조를 각각 개발한다. 본 연구에서는 크리티컬 패스(Critical path)를 최소화 하여 테일 레이턴시(tail latency)를 개선하고, 불필요한 I/O를 개선하여, 대역폭(bandwidth) 활용을 극대화한다.
스케일러블 DRAM용 인덱스 자료구조 연구 (Hydralist)
연구 내용
기존의 Trie based 자료구조는 단일 쿼리(Query) 검색에 빠른 성능을 보이지만, 범위 탐색 쿼리(Range Query)에서는 좋지 못한 성능을 보인다. B+-tree의 경우는 범위 탐색 쿼리에서 보다 빠른 성능을 보인다. 이러한 원인으로는 Trie의 경우, B+-tree에 비해 메모리 풋프린트(footprint)가 적고, B+-tree의 경우, 비슷한 키들을 같은 리프(leaf) 노드에 순차적으로 저장하기 때문이다. 따라서 Hydralist는 Trie를 탐색 레이어(Search Layer)로 활용을 하고, 실제 데이터를 저장하는 데이터 노드는 B+-tree의 스타일을 차용하였다. Search layer는 주어진 키(Key)를 활용하여, 타겟 데이터 노드 또는, 이웃의 데이터 노드까지의 경로를 제공한다. 만약 이웃의 데이터 노드에 도착한 경우, reader/writer는 데이터 레이어의 링크드 리스트(linked list)를 활용하여 데이터 레이어를 이동하여 최종적으로 타겟 데이터 노드에 도착하게 된다. 또한, 크리티컬 (Critical path)를 줄이기 위해서 탐색 레이어의 업데이트를 비동기적으로(asynchronous) 진행한다.
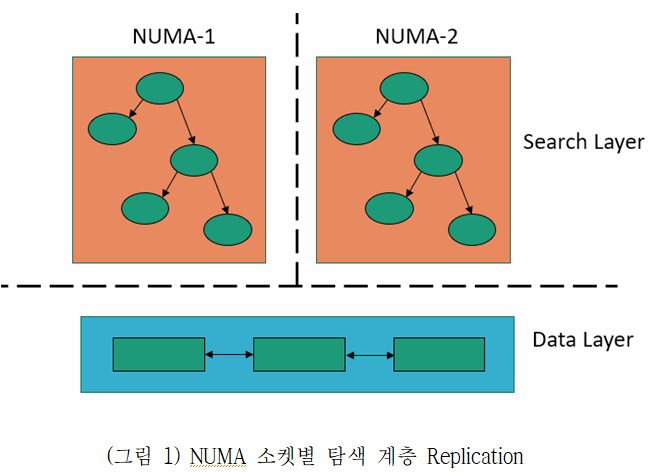
(그림 1)과 같이 다른 소켓의 메모리 읽기 연산을 최소화 하기 위하여, 탐색 레이어를 NUMA 소켓 별로 복제하며, 각 NUMA 소켓별 탐색 레이어는 각 소켓별로 할당된 백그라운드 쓰레드를 활용하여 비동기적으로 업데이트 한다.
성능 실험
Hydralist 성능 평가에서는 112개 코어와 4개의 NUMA 소켓을 가진 Xeon 8180 CPU와 125GB의 DRAM이 탑재된 서버를 활용하여 성능평가를 진행하였다. Hydralist의 성능평가는 인덱스 자료구조 성능평가 시 널리 활용되는 YCSB 워크로드를 활용하였으며, 비교군으로는 ART, B+-tree, MassTree, Wormhole과 같은 최근 발표된 자료구조와 널리 활용되는 자료구조 모두 포함하였다.
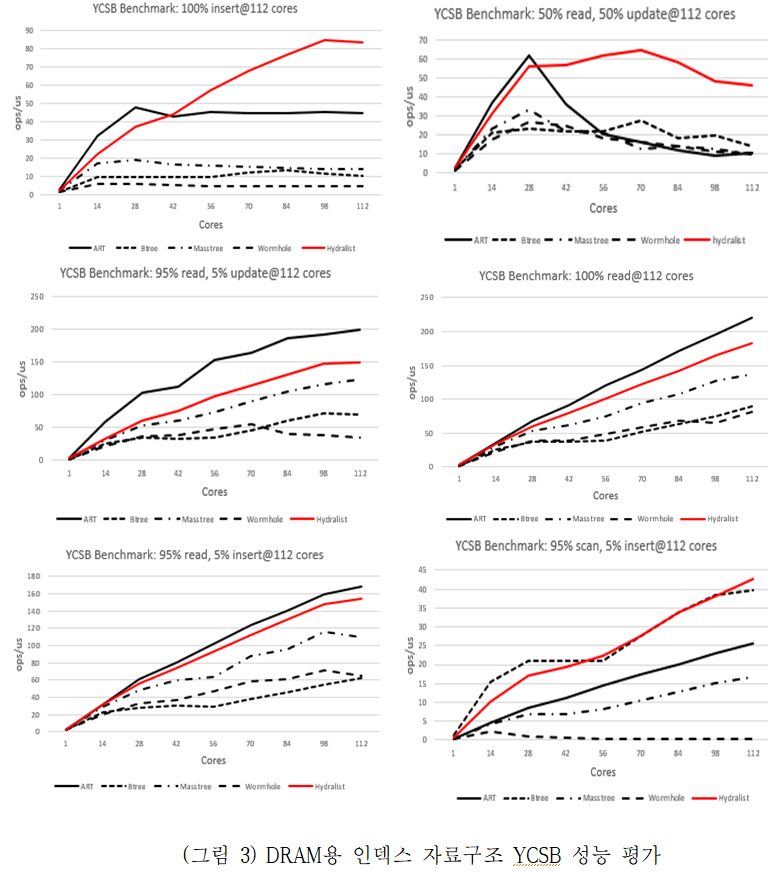
(그림 3)과 같이 쓰기 연산이 많은 경우, Hydralist가 다른 인덱스에 비해 좋은 성능을 보이는 것을 확인하였다. 읽기 연산이 많은 경우, ART와 비슷하거나 더 안 좋은 성능을 보이는데, ART가 B+-tree에 비해서 문자열 비교 횟수가 현저히 적기 때문이다. 스캔 성능의 경우, B+-tree와 비슷하거나 좋은 성능을 보이는 것을 확인할 수 있었다.
연구 결과물
- 논문
- 공개 소프트웨어
- Github: Hydralist
스케일러블 영구메모리용 인덱스 자료구조 연구 (PACTree)
연구 내용
PACTree 연구에서는 한정된 영구메모리의 대역폭을 효율적으로 활용하는 데 초점을 맞춘다. 특히 Hydralist 진행 중, 영구메모리용 인덱스 자료구조가 NUMA 환경에서 cross NUMA 트래픽 발생시 비정상적인 성능 감소를 분석하였고, 분석 결과 CPU 캐시 일관성 (Cache Coherence) 정책으로 사용되는 디렉토리 일관성(Directory Coherence)으로 인해, 디렉토리 정보가 영구메모리에 저장되고 그로 인해 성능이 영구메모리 쓰기 트래픽이 발생하여 성능이 저하되는 것을 확인하였다. 따라서 캐시 일관성 정책을 스눕 일관성 정책(Snoop Coherence)으로 변경하여 사용하였다.
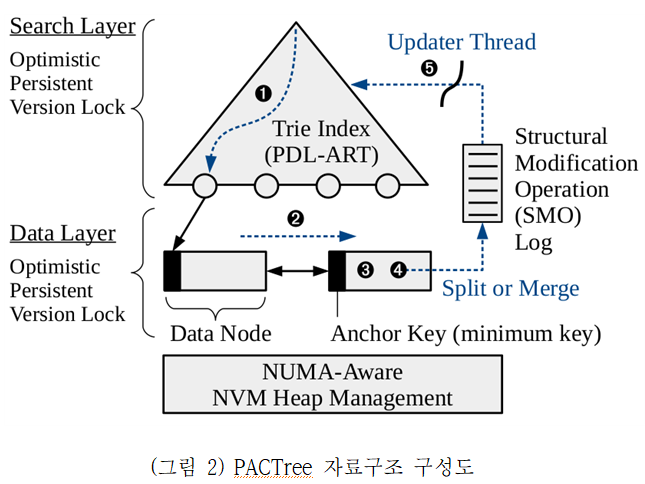
PACTree에서는 (그림 2)와 같이 영구메모리로 향하는 트래픽을 줄이기 위해 탐색 레이어를 Trie 인덱스를 활용하고, 데이터 노드는 B+-tree 스타일의 노드 디자인을 활용하였다. 영구메모리용 인덱스에서는 Remote Read가 미치는 영향은 크지 않으므로, 탐색 레이어는 하나만 사용하였다. 대신 Trie 인덱스를 영구메모리에서 사용할 수 있도록 수정하고, Durable linearizability가 보장될 수 있도록 수정하였다. 영구메모리의 경우, 영구메모리 공간 활용을 위해 영구메모리용 풀을 만들어야 하기 때문에, NUMA 소켓별로 영구메모리 풀을 만들고, 모든 영구메모리 할당은 로컬 NUMA 영구메모리풀에서 발생하도록 하였다. 이 때, 주소 값이 영구메모리 풀 아이디 + 영구메모리 풀에서의 오프셋으로 구성되어 있으므로, 이를 8바이트에 저장하는 영구메모리용 포인터 자료구조를 디자인하였다. 또한 락(lock)으로 인한 영구메모리 쓰기 트래픽을 발생시키지 않도록 버전(version) 기반의 락을 활용하였으며, 즉각적인 복구를 위하여 generation id를 함께 활용하였다. 영구메모리의 메모리 할당의 경우, 영구메모리 누수를 막기 위해, 작은 사이즈의 로그를 활용하였다. PACTree에서의 메모리 할당은 분할(split)/병합(merge)와 같은 구조적 변화 연산(Structural Modification Operation)에서만 발생하기 때문에, 이 때 미리 고정된 주소에 할당되어 있는 작은 사이즈의 로그들 중 하나의 주소를 PMDK 영구메모리 할당자에 넘겨주어, 메모리 할당시 활용할 수 있도록 하였다.
성능 실험
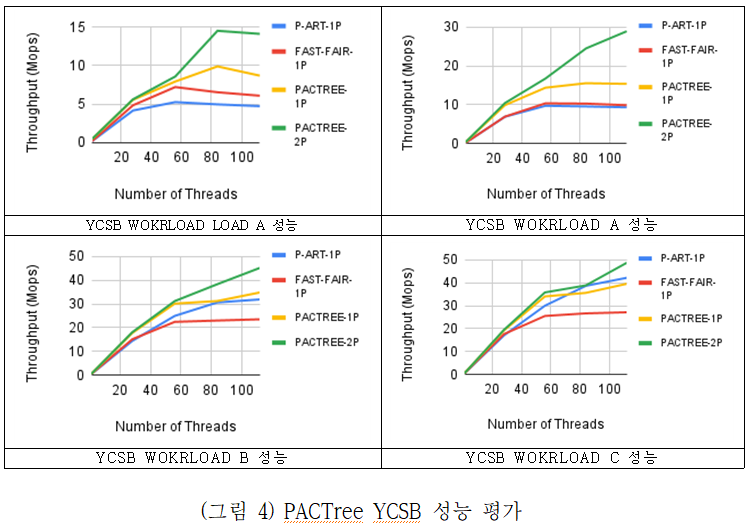
PACTree 성능 평가에서는 2소켓 56 코어의 Intel Xeon Platinum 8280M CPU, 768GB DRAM과 총 3.0 TB (12 * 256GB)의 영구메모리가 탑제된 서버를 사용하였다. 비교군으로는 영구메모리용 Trie 인덱스인 P-ART, 영구메모리용 B+-tree 인덱스인 FAST-FAIR를 비교하였다. 성능 평가 결과, (그림 4)와 같이 전체적으로 다른 영구메모리용 자료구조에 비해 좋은 매니코어 확장성을 보였으며, 특히 쓰기 연산이 많은 경우, PACTree 가 더 좋은 성능을 보이는 것을 확인할 수 있었다.
연구 결과물
- 논문
- 공개 소프트웨어
- Github: PACTree
영구메모리 기반 키벨류스토어 연구개발 (Jet_SierraKV)
상기의 스케일러블 자료구조를 활용하여 초고성능 데이터베이스를 개발할 수 있다. 특히, PACtree는 영구메모리 기반 키벨류스토어 개발에 활용이 가능하다. 대규모 키벨류스토어를 개발은 매니코어 시스템을 분산으로 구축하고, 시스템간 고속의 통신 방법을 제공하면 가능하다. 본 연구에서 RDMA 기반 고속통신 프로토콜을 연구개발 (Flock)을 하였다. PACTree와 Flock를 활용하면, 대규모 키벨류스토어를 개발할 수 있다.
연구 결과물
- 논문
- 공개 소프트웨어
- Github: Flock
- 시연 영상