기존 병렬화 프레임워크의 스케일러빌러티 연구
연구 배경
무어의 법칙(Moore's Law)에 따라 코어 집적도가 지속적으로 증가하고있다. 이에 발맞춰 Intel Xeon Phi, Tilera TILE-Gx, Gavium Octeon 등의 매니코어 프로세서가 시장에 나오고 있으며 매니코어 플랫폼 환경이 일반화되고 있다. 위와 같은 매니코어 프로세서를 효율적으로 사용하기 위해서는 어플리케이션에 존재하는 병렬성의 효과적인 추출과 실행을 가능케 하는 병렬화 프레임워크의 지원이 필수적이다. 또한, 이러한 매니코어 플랫폼에서 병렬화 프레임워크의 성능 확장성(Scalability) 및 전력 효율(Power Efficiency)에 대한 연구 및 분석이 필요하다.
또한 최근 새로운 메모리 집적 기술 발달과 함께 다양한 종류의 메모리 디바이스가 등장함에 따라 이에 따른 소프트웨어 최적화에 대한 요구가 증대되고 있다. 특히, 프로세서 패키지 내에 메모리를 3차원으로 집적하는 3D die-stacked 메모리, non-volatile 메모리 기반의 높은 용량을 제공하는 메모리 등과 같이 서로 다른 특성을 가진 메모리를 기존 DRAM과 함께 활용하여 시스템의 성능을 향상시키고자 하는 시도가 활발하다.
매니코어 병렬화 프레임워크의 확장성 및 전력 효율 개선 방안 연구
내용
본 연구에서는 OpenMP, MPI, OpenCL, TBB, Cilk 등 기존 병렬화 프레임워크의 정량적 평가 및 다양한 도메인의 워크로드 분석을 통해 향후 개발할 매니코어 병렬화 프레임워크의 설계 요구사항을 도출한다.
- Performance Monitoring Unit(PMU)/Running Average Power Limit(RAPL) 인터페이스를 활용한 다양한 병렬화 프레임워크의 성능 및 전력 효율 측정
- 성능/전력/발열 측정 및 병목분석을 위한 툴(Ivy Pofiler) 개발
- 2차년도 이후의 연구를 위한 테스트베드 구축 및 워크로드 포팅
- 매니코어 병렬화 프레임워크의 설계 요구사항 도출
결과
매니코어 병렬화 프레임워크의 확장성 및 전력 효율 비교 분석 연구를 위해 3종의매니코어 테스트베드 및 실험 환경을 구축하였다.
- 테스트베드 1(Fat-12): 12 코어 Intel Xeon E5645 (Westmere-EP)
- 테스트베드 2(Fat-120): 120 코어 Intel Xeon E7-8870 v2 (Ivy Bridge-EX)
- 테스트베드 3(Thin-57): 57 코어 Intel Xeon Phi Coprocessor 3120A (Knights Corner)

그림 1은 OpenMP-NPB 병렬화 프레임워크 및 워크로드의 플랫폼 별 확장성 성능 측정 결과 및 프로그램의 순차 수행 영역 대비 병렬화 가능한 영역의 비중을 나타내는 Amdahl' Limit 분석 그래프이다. EP 프로그램의 경우,3종의 플랫폼에서 코어가 늘어남에 따라 대체적으로 성능 증가 추세를 보였다. 그러나 다른 프로그램의 경우, 낮은 speedup, 계단형/톱니바퀴형 증가, saturation, 특정 코어 개수 이후 성능 감소 추세 등의 비확장적인(non-scalable) 특징을 보인다. Amdahl's Limit 분석을 보면, 대부분이 병렬화 가능한 부분으로 구성되어 있음에도 불구하고 비확장성 성능 특성을 보인다. 이러한 프로그램에 대해서는 메모리 프로파일링 등의 추가적인 분석을 통해 보다 정확히 분석할 수 있다.
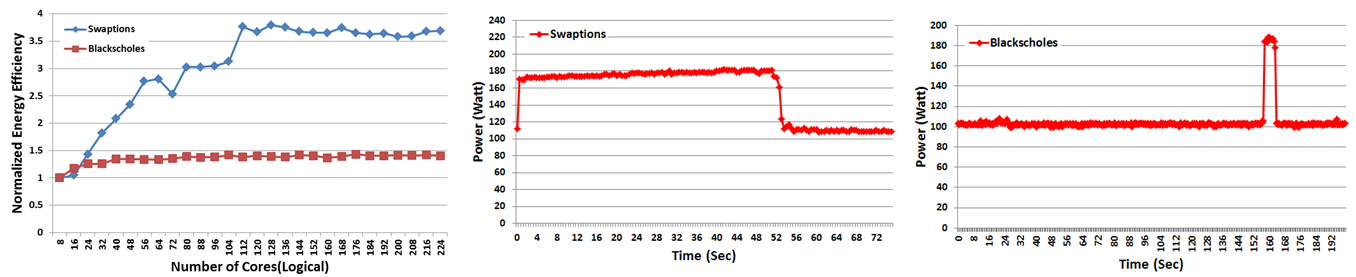
그림 2는 Thin-57 환경에서 pthread-PARSEC 병렬화 프레임워크 및 워크로드가 코어 수에 따른 전력 효율 및 최대 코어 사용 시 시간에 대한 전력 사용 추이를 나타내는 그래프이다. Swaption의 경우, 병렬 수행 구간이 길기 때문에 사용 코어의 개수를 증가시킬수록 에너지 효율이 증가하지만 blackscholes의 경우, 특정 코어 개수 이후 에너지 효율이 더이상 증가하지 않는 것을 관찰할 수 있다. 이는 최대 코어 사용 시 시간에 대한 전력 추이에서도 잘 나타난다. Swaption 프로그램은 실행구간의 대부분의 영역에서 높은 전력을 사용하지만, blackscholes의 경우 전체 수행 영역 중 일부분에서만 높은 전력을 사용한다. 이 역시 병렬 수행 구간의 차이에서 나타나는 결과이다. Swaption 프로그램은 거의 모든 구간이 병렬 처리 구간인 반면, blackscholes 프로그램은 높은 전력을 사용하는 구간만 병렬 수행 구간에 해당하며, 나머지 수행 구간은 모두 순차 수행 구간에 해당한다. 이러한 프로그램의 전력 측정 및 효율 분석을 통해, 확장성 대비 전력 효율을 균형 있게 선택적으로 조정하여 프로그램의 성능 및 전력 효율을 증가시킬 수 있다.
매니코어 환경에서 메모리 지역성을 고려한 Java 병렬 프레임워크 개선
내용
본 연구에서는 매니코어 플랫폼에서 Java를 활용한 Hadoop, Google Infrastructure 등의 병렬 프레임워크의 성능 확장성 연구 및 이기종 메모리 시스템(Heterogeneous Memory System)을 가지고 새로운 매니코어 플랫폼의 메모리 지역성(Memory Locality)을 고려한 성능 확장성 개선을 이끌어내고자 한다.
- 메모리 지역성을 고려한 Java Virtual Machine(JVM) Non-Uniform Memory Access(NUMA) 환경 최적화
- JVM Garbage Collection(GC) 알고리즘 개선
- PMU를 활용한 성능 측정 및 분석 도구(Ivy Profiler) 확장 및 개선
결과
GC 알고리즘 개선 및 NUMA 환경 최적화를 위한 선행 연구를 진행하였으며, 필요한 몇 가지의 핵심 요소 기술을 구현하였다.
-
선행연구: 잠재적 성능 향상치 및 객체 특성 연구
-
잠재적 성능 향상치
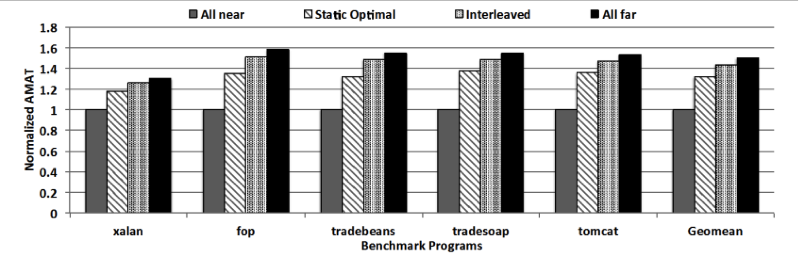
위 그림은 near-far 메모리 환경을 위해 수정된 McSimA+ 시뮬레이터를 이용해 측정한 잠재적 성능 항샹치를 나타내는 그래프이다. All near 구성은 모든 객체가 가까운(빠른) 메모리에 할당될 때이고, All far 구성은 모든 객체가 먼(느린) 메모리에 할당될 때이다. Interleaved는 객체의 접근 횟수나 접근 강도(Access Intensity)와는 관계없이 주소 값에 따라 round-robin 방식으로 할당하는 방식이고, Static optimal은 접근 강도가 높은 12.5%를 빠른 메모리에 나머지를 느린 메모리에 할당하는 방식이다. Static optimal과 interleaved는 같은 크기의 빠른 메모리와 느린 메모리를 사용하지만, 할당하는 방식에 따라 성능에 차이를 보이고 있다. 결과에서 볼 수 있듯이 near-far 메모리 환경에서 객체의 접근 강도를 고려한 효율적인 객체 할당을 통해 성능 향상을 얻을 수 있음을 알 수 있다.
-
객체 특성: Age
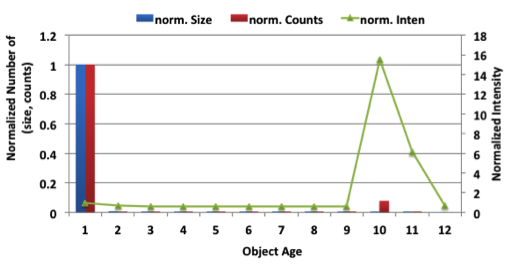
위 그림은 객체의 특성인 나이에 따라 어떤 접근 패턴을 가지고 있는지를 알아보기 위해 나이에 따른 접근 횟수와 접근 강도를 나타낸 그래프이다. 그림에서 알 수 있는 특성은 크게 두 가지이다. 첫째로는 대부분의 액세스는 객체가 생성된 지 얼마 되지 않은 0~2 사이의 나이에서 이루어진다는 것이고, 두 번째로 접근 강도는 Old generation으로 Promotion되는 나이인 8 이후에 살아남은 일부의 객체에서 주로 높게 나타난다는 것이다. Age는 기존의 GC가 이루어질 때 수정되는 변수이므로 별도의 프로파일링 없이 액세스 카운터를 대신할 수 있다.
-
-
요소 기술 1: Multi-Generational Heap Layout
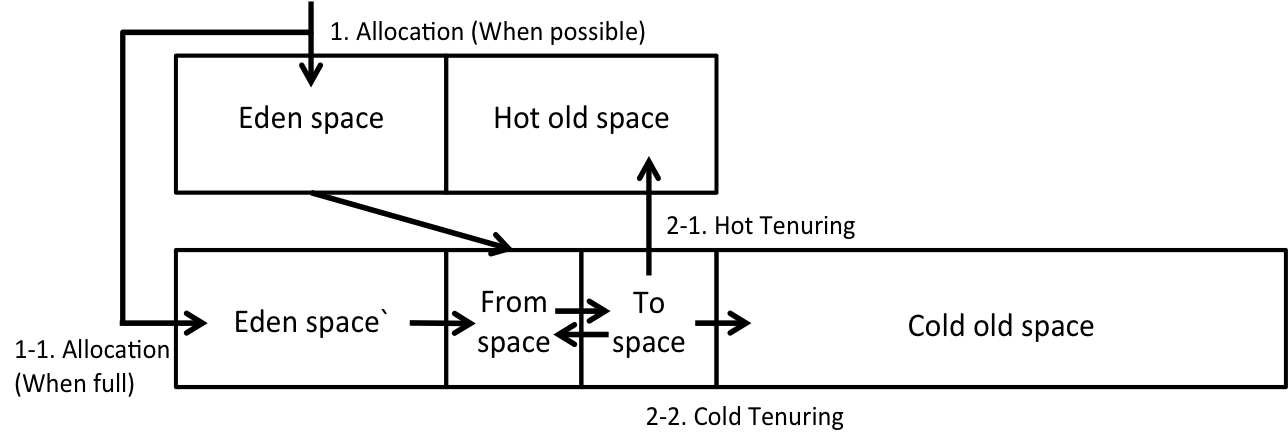
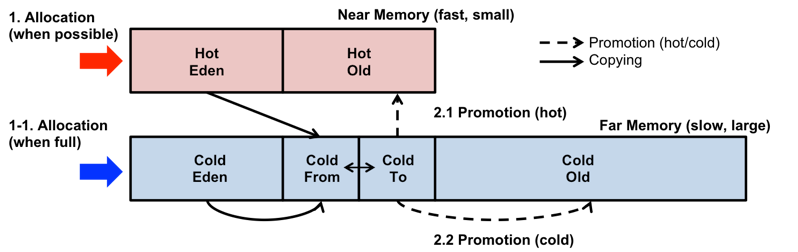
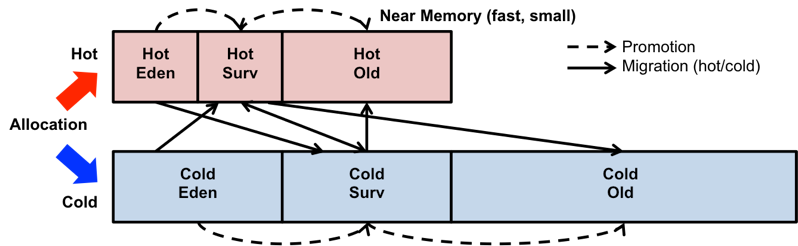
JVM의 힙 메모리 구조에 새로운 영역들을 추가했다. 가까운 메모리에는 객체 할당의 오버헤드를 줄이기 위해 Eden space와 hot object의 빠른 액세스를 위해 Hot old space를 배치하고, 먼 메모리에도 잦은 Young GC로 인한 오버헤드를 방지하기 위해 여분의 Eden space와 기존의 평범한 old object를 위해 Cold old space를 배치한다.
-
요소 기술 2: 객체 단위 프로파일링 도구
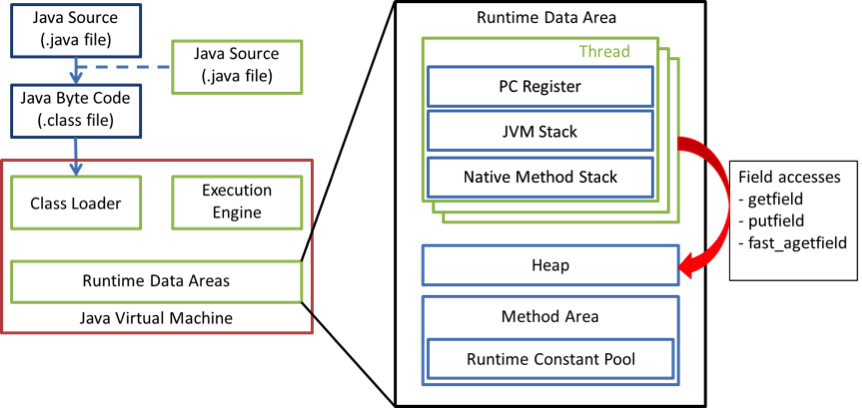
객체 단위 프로파일링을 위해 객체의 헤더에 접근 횟수 카운터를 추가하고, 이를 런타임에서 쓰레드가 수정할 수 있도록 하였다. 이를 위해 JVM이 힙 공간의 객체에 접근하는 bytecode들을 수정할 필요가 있었다. 위 그림은 Java 런타임이 힙 객체에 접근하는 과정을 간략히 도식화한 것이다.
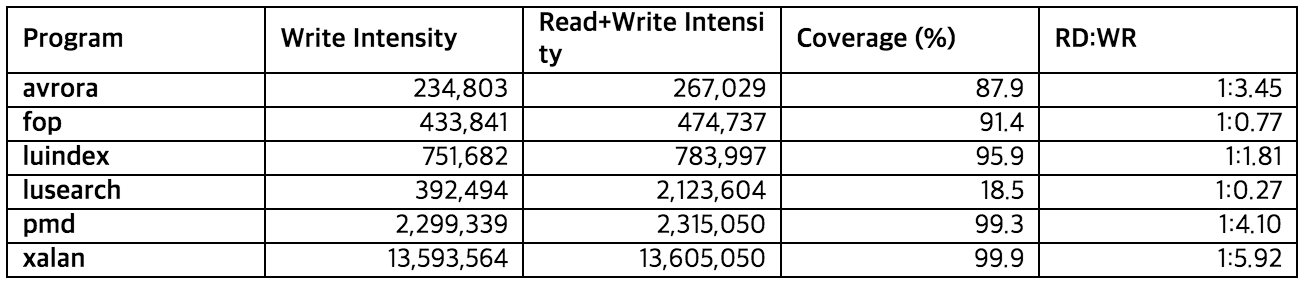
실제 런타임에서 모든 객체 접근을 기록하는 방식은 너무 오버헤드가 크다. 따라서 Write barrier를 이용해 write access만을 샘플링할 수 있도록 하였다. 위 표은 write만을 샘플링 했을 때와, read와 write 모두를 샘플링 했을 때 접근 강도 기준으로 상위 12.5% 객체들이 얼마나 겹치느냐를 나타낸 표이다. 그림에서 볼 수 있듯이 lusearch를 제외한 프로그램에서는 대체로 높은 비율로 상위 객체들이 일치한다. 따라서 write만을 샘플링 하더라도 객체의 접근 패턴을 충분히 반영할 수 있다.
Near-far 메모리 에뮬레이션 시스템에서의 Java 프레임워크 개선 및 성능 측정
내용 1: 2차년도의 상세 설계 내용 구현 및 성능 평가
2차년도에 진행한 JVM의 NUMA 환경 메모리 지역성 개선 연구의 상세 내용을 구현하고, 실제 near-far 메모리 환경에서 평가한다. 하지만 near-far 메모리 매니코어 플랫폼 (Intel Xeon Phi Knights Landing) 의 출시가 지연되어 기존의 cc-NUMA 메모리 시스템을 이용한 near-far 에뮬레이션 환경에서 평가를 대체한다.
내용 2: JVM의 garbage collector (GC) 스케일러빌리티 개선을 위한 알고리즘 설계
실행 시스템의 GC 스케일러빌리티를 측정하고 병목을 분석하여, 스케일러빌리티 개선을 위한 실행 환경 알고리즘을 설계한다.
결과
-
Near-far 메모리 환경 에뮬레이션
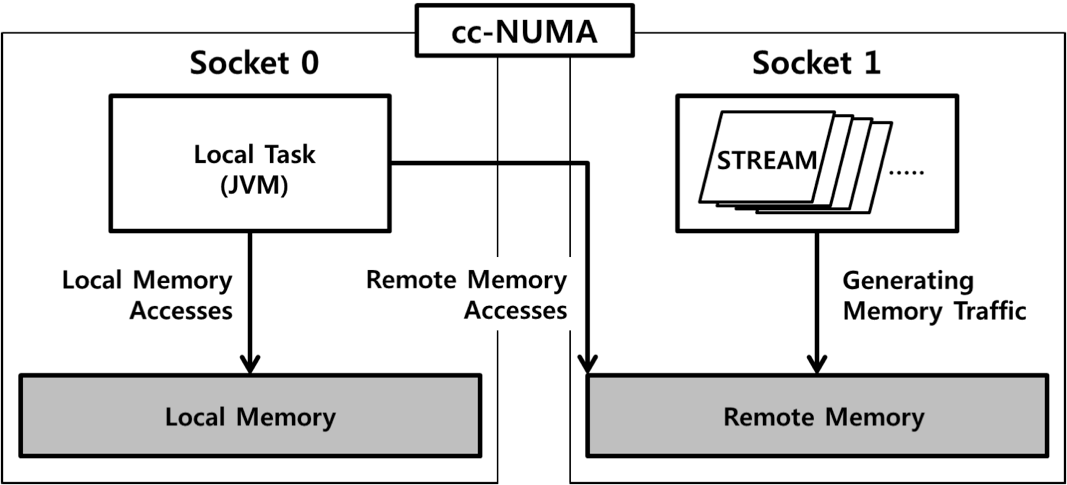
최근의 cc-NUMA 플랫폼들은 local-remote 메모리 간의 대역폭 및 지연 시간의 차이가 미미하여, near-far 메모리 환경을 재현하기에 미흡하다. 따라서 traffic generator를 이용해 remote 메모리에 추가적인 traffic을 발생함으로써 near-far 메모리 사이에 bandwidth와 latency의 차이를 증가시킨 테스트베드를 구현했다.
소켓 0번을 local 환경으로 가정하여 JVM은 소켓 0번의 코어들을 이용하도록 고정하고, Near 메모리는 소켓 0번의 메모리를 사용한다. Far 메모리는 소켓 1번의 메모리를 사용하는데, 충분한 대역폭과 지연시간의 차이를 만들어내기 위해 다수의 STREAM 프로그램 (총 16개) 을 소켓 1번에 고정하여 수행한다. Near 메모리 접근에 비해 remote 메모리를 접근하는 경우 약 5배 느린 수행 시간을 보인다. 이는 현재 알려진 Intel Xeon Phi Knights Landing 의 세부사항과 거의 유사하다.
-
평가
위의 세 가지의 요소 기술을 활용하여 near-far 메모리 환경에서 JVM의 힙 배치를 최적화하는 것으로 어떤 성능향상이 있는지 실험하였다. 실험은 크게 다음 3개의 질문에 답을 찾기 위해 수행되었다.
- 제한된 양의 near memory를 각각의 generation에 어떻게 할당할 것인가?
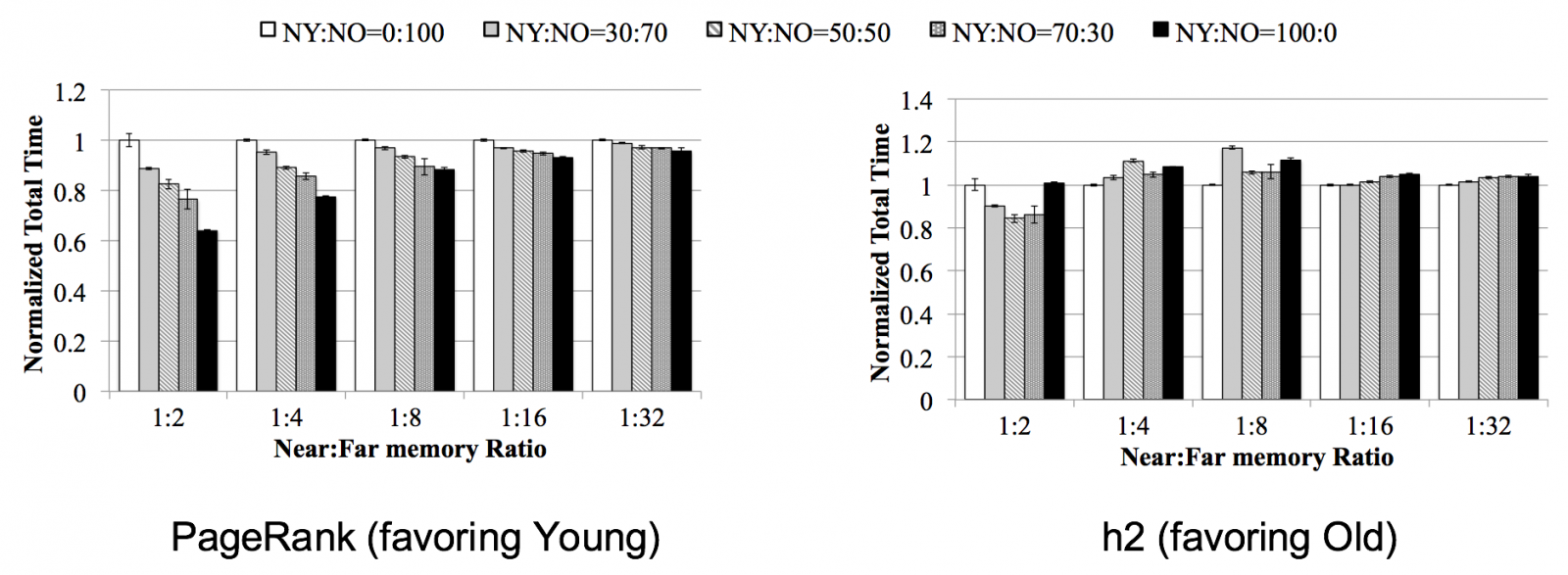
한정된 near memory를 Young generation과 Old generation이 어떤 비율로 나누어서 사용하는 것이 최적인지 알아보았다. YG과 OG의 비율은 1:2로 고정하였고 near, far 메모리들의 용량을 변경해가며 실험을 진행하였다. 대체로 YG와 OG 중 하나의 영역이 near memory를 전부 사용할 때에 최적이었다. Favored generation은 애플리케이션에 따라 다르다.
- 가용한 near memory의 양과 generational space sizing의 상관관계는?
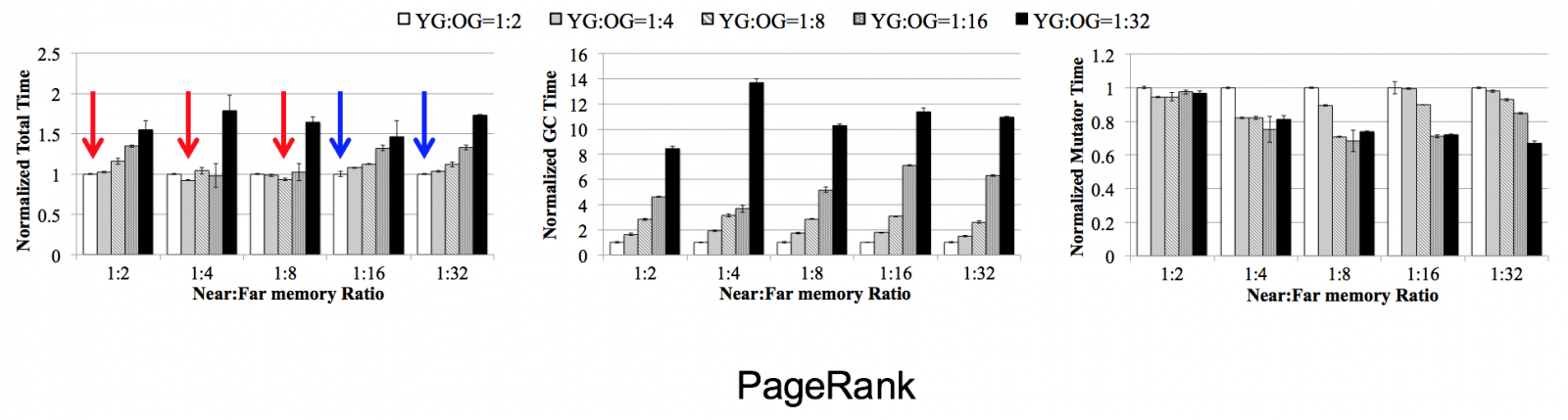
Near memory의 용량을 바꾸어 가면서 최적의 near:far memory 간의 비율을 알아보았다. Near memory가 너무 작거나 너무 크지만 않다면, 대체로 near memory의 용량과 favored generation의 크기가 같을 때 최적이다. (붉은 화살표) Near memory가 너무 크거나 너무 작다면, favored generation과 near memory의 크기를 같도록 하는 방법은 GC 오버헤드로 인하여 최적의 방법이 아니다. (푸른 화살표)
- 하나의 genration이 near-far memory에 걸쳐 있을 때 최적의 구성 방법은?
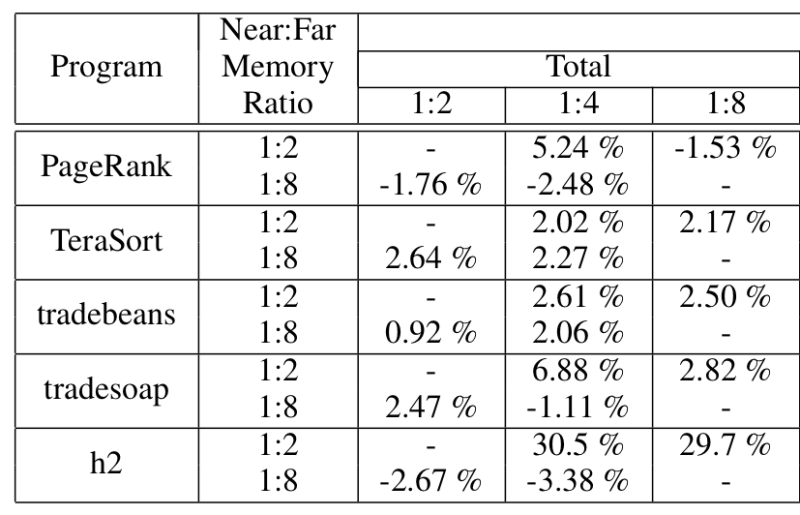
Generation과 near memory가 coupling 되지 않고 두 메모리에 걸쳐 있을 때에 해당 영역을 메모리에 어떤 방식으로 할당하면 좋을지 실험하였다. 첫 번째 방법으로는 near memory를 영역의 가장 처음부터 할당하고 나머지를 far memory로 할당하는 방법 (first-chunk), 두 번째 방법으로는 해당 영역을 두 메모리가 번갈아가며 할당하는 방법이다. (interleaving) 대부분의 경우 first-chunk 방식이 interleaving 방식보다 조금 더 나은 성능을 보이고 있다.
Near-far 메모리 에뮬레이션 시스템에서의 Java 프레임워크 개선 방안 연구
내용 1: 객체 단위 프로파일링 기법의 성능 측정 및 문제점
위 그림은 객체 단위 프로파일링을 통해 높은 접근 강도를 갖는 객체를 garbage collection이 일어나는 시점에 near 메모리에 재배치하는 기법의 JVM 힙 구조도를 나타낸 것이다. 새로 생성되는 모든 객체는 먼저 hot eden space에 할당되며, 상위 space로 promotion 될 때 객체의 헤더에 저장된 메모리 접근 횟수를 참조해 near 및 far 메모리에 위치한 hot 또는 cold old space로 구분하여 할당한다.
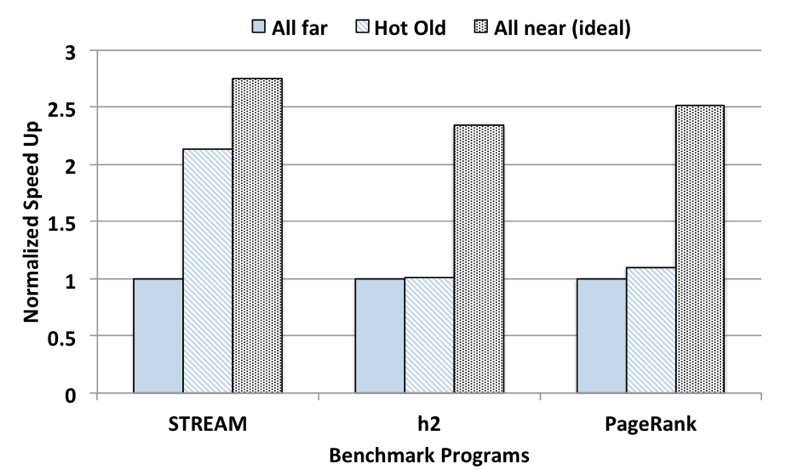
위 그림은 이러한 기법을 프로토타입으로 구현하여 성능을 측정한 결과이다. 실험은 Intel Xeon E5-2640 v2 (Ivy Bridge) 2-socket cc-NUMA 플랫폼과 traffic generator를 활용하여 구현한 emulator 환경에서 수행하였다. 해당 기법 (Hot Old)를 적용할 경우, all far policy에 비해 약 2.13배의 성능 향상이 있었지만, DaCapo-h2, Spark-PageRank의 경우 메모리 사용량이 큰 응용임에도 불구하고 성능 향상이 각각 1%, 9.9% 정도로 미미했다.
-
성능 향상이 미미한 이유
1) 많은 객체들이 young generation (eden 및 survivor space)에서 할당 및 메모리 접근을 일으키고 난 후 얼마 지나지 않아 garbage가 됨
2) 1)로 인해 promotion 되는 객체의 수가 적음
따라서, near 메모리의 활용 빈도가 떨어지며 이로 인해 큰 잠재성능에 비해 해당 기법의 성능 향상이 미미한 것으로 추정된다. 이러한 성능 측정 결과를 토대로 하여 객체의 메모리 접근 프로파일링 대상을 young generation 과 old generation을 포괄하는 힙 전체로 확장하고, 기존 기법에서 사용되었던, GC의 copying 동작에 편승하는 방법은 유지하여, migration으로 인한 부가적인 오버헤드를 경감시키는 방향으로 설계를 수정하였다.
내용 2: 객체 할당 지점 단위 프로파일링 및 런타임 휴리스틱
Near-far 메모리 환경에서의 JVM기반 어플리케이션의 지역성 향상을 통한 성능 최적화를 위해 객체 할당지점 단위 프로파일링 및 실행시간 휴리스틱에 대한 상세 설계사항을 제시한다. 이는 기존 객체 지점 단위 프로파일링 및 실행시간 휴리스틱의 단점을 보완하여 전체 객체에 대한 hot-cold partitioning을 통해 휴리스틱이 적용되는 범위를 늘리고, 기존 실행시간에 진행하던 프로파일링을 오프라인으로 진행하는 설계사항을 포함한다.
위 그림은 객체 할당지점 단위의 프로파일링 기법 및 이를 활용하는 Java 힙 구조도를 나타낸다. 해당 설계는 기존 객체 단위 프로파일링 기법과 다음과 같은 사항에서 구분된다.
-
객체 할당지점 단위 프로파일링: 객체의 hot-cold 여부를 기존 객체 단위 프로파일링에서 객체 할당지점 단위로 변경
1) 객체 할당지점의 contextual information 추출
2) 객체의 메모리 접근 시 객체 할당지점 별 기록
3) 특정 객체 할당지점에서 할당되는 객체들의 총 메모리 접근 횟수가 threshold를 넘는지 판별
4) 객체 할당지점별로 hot-cold flag를 설정
5) 실제 어플리케이션 실행 시 해당 할당지점의 flag를 확인하여 hot 또는 cold eden space로 할당
6) Promotion 혹은 Copying 과정에서 객체의 hot 여부를 판단하여 영역 변경
-
Java 힙 구조변경: 객체의 할당시점부터 hot-cold를 구별하여 할당하기 위한 힙 전체 space를 hot-cold로 구분하고 이를 near-far 메모리에 구분하여 할당
Near-far 메모리 시스템에서의 Spark 프레임워크 성능 분석 및 개선 방안 연구
배경
-
Intel Knights Landing
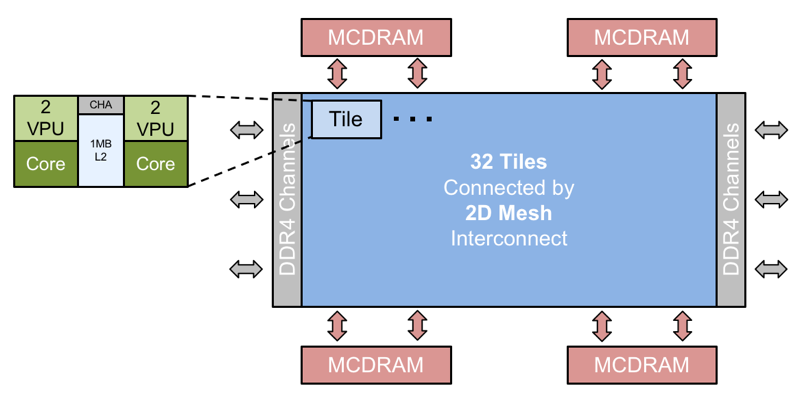
최근 출시된 Intel Xeon Phi Knights Landing은 32개의 타일이 2D 메쉬 구조로 배치되어 있으며, 각각의 타일은 2개의 1.3GHz 코어와 1MB L2 캐시로 이루어져 있다. 또한 Hyper-Threading 기술을 적용하여 최대 256개의 코어를 가질 수 있다. 또한 off-package DDR4 DRAM을 6개의 채널을 이용해 384GB 까지 구성하여 추가 용량을 확보할 수 있다. 대역폭 성능은 MCDRAM이 최대 480GB/sec, DDR4 DRAM이 최대 102GB/sec로 약 4.7배의 큰 차이를 보인다.
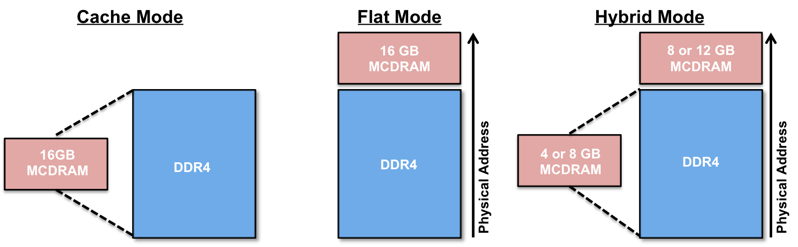
Knights Landing의 메모리 모드는 MCDRAM의 사용 형태에 따라 크게 세 가지로 나눌 수 있다.
- MCDRAM을 last level cache (LLC)로 사용하는 캐시 (Cache) 모드
- MCDRAM를 direct memory allocation을 이용해 사용자가 메모리를 직접 관리할 수 있는 플랫 (Flat) 모드
- 두 가지 방법을 혼용하는 하이브리드 (Hybrid) 모드
-
기존 연구의 한계점 NUMA 시스템에서 JVM의 메모리 관리 최적화에 관한 연구들은 1) 객체 혹은 객체 할당 지점 단위의 프로파일링 및 최적화를 다루거나, 2) 멀티 소켓 NUMA 시스템에서 local-remote 메모리 접근을 최적화하는 것을 제안한다.
1) 이기종 메모리 관련 연구들은 메모리 접근이 많은 객체를 hot 객체로 분류하고, 이 객체들을 성능이 좋은 near 메모리로 배치하여 성능 향상을 얻고자 한다.
2) 멀티 소켓 NUMA 시스템 관련 연구들은 어플리케이션의 메모리 접근 패턴을 분석하고, 스레드들의 메모리 접근이 최대한 local 메모리로 이루어지도록 하여 메모리 접근 시간을 최적화하는 것을 목표로 한다.
하지만, Spark은 다른 JVM 어플리케이션들과는 다르게, epochal behavior를 가지는데, 이는 Spark의 어떤 stage에서 생성되는 객체들은 한번에 생성되고 소멸하며, 또한 한번 생성되고 사용된 객체는 stage가 끝나고 나면 사용되지 않는다는 특성을 말한다. 이러한 특성은 기존에 연구되어왔던 NUMA 관련 객체 레벨 프로파일링 및 최적화 기법들이 Spark 어플리케이션에는 쉽게 적용될 수 없는 문제점을 야기시킨다.
분석
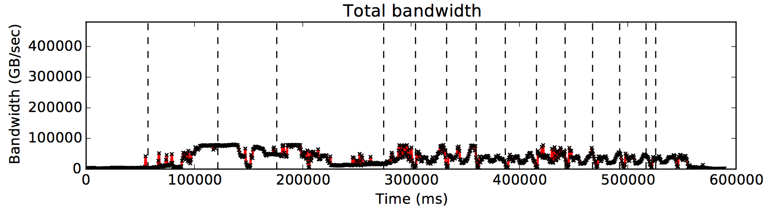
위 그림은 Spark 프레임워크 상에서 PageRank를 flat (far-only) 모드에서 수행하였을 때의 executor 별 수행 시간 및 메모리 대역폭 사용량 변화 추이를 나타낸 그래프이다. 각 executor의 경우, 수직으로 표시된 점선은 Spark의 stage가 시작되는 시간을 의미하며, 가로로 표시된 검정 실선의 경우 task 별 수행시간을 나타낸다.
실험 결과를 살펴보았을 때, 메모리 대역폭의 사용량이 특정 시간에만 집중적으로 증가하며, 이외의 구간에서는 상당 부분 대역폭을 모두 사용하지 않고 있는 것을 관찰할 수 있다. 즉, 이는 stage 내의 특정 phase에서 메모리를 할당하고 많은 양의 메모리 접근을 발생하여 대역폭 사용량이 saturation 됨을 의미한다. 관찰된 최대 메모리 대역폭 사용량은 80GB/sec로서 PageRank 어플리케이션에서는 80GB/sec 이상의 대역폭을 달성하지 못하고 saturation 된 구간에서는 수행 시간이 지연되는 것으로 보인다.
Spark 프레임워크에서 메모리가 할당되고 사용되는 단위는 크게는 stage별, 작게는 stage에 포함된 각 RDD를 수행하는 function 단위로 나눌 수 있다. 위 그림에서는 높은 대역폭을 사용하는 구간이 다수의 stage에 걸쳐 나타나는 것으로 볼 때, RDD의 수행을 기점으로 하여 메모리 할당 및 접근이 일어나는 것으로 보이며, 특정 RDD의 경우, 대역폭 사용량이 최대로 가용한 대역폭 성능을 모두 사용하는 것으로 관찰된다.
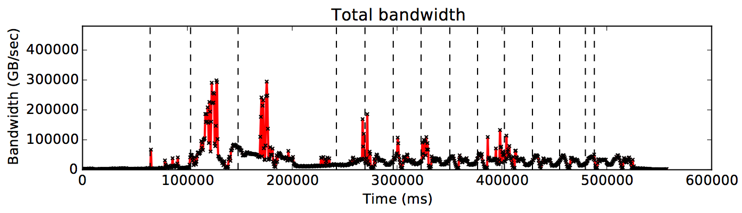
위 그림은 PageRank를 cache 모드 하에서 수행하였을 때의 결과로써, 메모리 대역폭이 특정 구간에서 saturation되는 flat 모드와는 달리, 비교적 짧은 구간에서 near 메모리의 대역폭을 집중적으로 높게 사용하고 있는 것을 관찰할 수 있다. 이러한 대역폭 성능 특성의 차이는 cache 모드에서는 기존 flat 모드에서는 대역폭 사용량이 saturation되는 구간에서 near 메모리의 높은 대역폭 성능을 활용하고 있는 것을 관찰할 수 있다.
이상과 같은 분석 내용을 통해 Spark 프레임워크의 near-far 메모리 환경에서의 성능 향상을 위한 다음과 같은 몇 가지 결론을 도출할 수 있다.
- Spark 프레임워크 기반 어플리케이션의 경우, near-far 메모리 플랫폼 환경에서 높은 대역폭 성능 특성을 가지는 near 메모리 활용에 따른 잠재 성능 향상치가 존재한다. 이는 flat 메모리 모드 및 cache 모드의 성능 비교를 통해 간접적으로 확인할 수 있다.
- Spark 프레임워크 기반의 어플리케이션의 경우, 메모리 대역폭을 사용하는 특정 구간들이 존재하며, 이러한 구간은 같은 code와 input을 기반으로 수행하는 function (RDD) 단위로 나뉘어짐을 대역폭 성능 특성 분석을 통해 확인할 수 있다.
- 메모리 대역폭 사용량이 높은 특정 function의 경우, 기존 메모리 (LPDDR4)에서는 대역폭 성능 saturation으로 인해 수행 시간이 지연되는 경향을 보이며, 이를 높은 메모리 대역폭 성능을 갖는 near 메모리를 활용함으로써 수행 시간 지연을 경감시킬 수 있음을 flat 메모리 모드 및 cache 모드의 stage 별 수행 시간 비교를 통해 확인할 수 있다.
- Cache 모드를 사용할 경우, 낮은 메모리 대역폭 요구량을 갖는 구간에서는 near 메모리 사용으로 인한 지연 시간 및 cache miss penalty로 인해 성능이 저하될 가능성이 있음을 stage 별 수행 시간 분석을 통해 확인할 수 있다.
개선 방안: 대역폭 기반 RDD 분류 및 할당
- Java 힙 분할 및 near-far NUMA 환경 할당 near 및 far 메모리를 구분하여 객체를 할당하기 위해서는 Java 힙을 near 및 far 메모리 공간으로 분할하여 할당해야 한다. 이를 위해서는, Java 힙을 구성하고 있는 Young generation (eden, from-, to-space) 및 Old generation (object space)를 각각 두 개로 나누어야 한다. 각 space는 JVM 초기화 시 기본 크기 및 각 space간 비율을 사용자에게 인자로 받아 mmap()을 통해 메모리에 할당하는 과정을 거치는데, 이 시점에서 near 혹은 far 메모리 공간에 맞게 각 space를 분할하고 고정하는 추가 과정을 필요로 한다. 또한, JVM 의 JIT 컴파일러인 C1과 C2 컴파일러의 allocator 를 hot/cold allocator 확장하였다.
현재 Intel Xeon Phi 7210 (KNL)의 flat 모드에서는 near 혹은 far 메모리에 대한 NUMA 환경 할당을 위해서 기존 cc-NUMA 환경에서 제공하던 libnuma API를 지원하고 있다. 이를 이용하여, JVM의 초기화 시 각 space를 hot/cold space로 구분하여 size를 결정하고, 각 space의 mmap 할당 후 libnuma API 중 mbind()를 이용하여 각 space를 near 및 far에 고정한다.
-
Spark - JVM communication interface Spark 어플리케이션 수행 중에 동적으로 JVM의 분할된 hot/cold 영역으로 메모리 할당을 바꾸려면 Spark 프레임워크 레벨에서 JVM 레벨의 heap allocator로 신호를 보내줄 수 있어야 한다. Java에서는 이러한 역할을 할 수 있는 인터페이스 MXBeans를 지원하는데, Spark 실행 시간 중에 대역폭 성능 별로 선별된 hot stage 에서만 hot allocation을 할 수 있도록 MXBeans를 확장하였다.
- RDD별 대역폭 사용량 및 잠재 성능 향상치 측정 flat 메모리 모드를 기반으로 explicit 한 잠재 성능을 확인하기 위해서는 cache 모드와의 성능 비교가 필수적이다. 이를 위해서는 어플리케이션 수행 시간 및 대역폭 변화 추이를 RDD 단위로 분할하여 어떤 RDD가 대역폭 사용 요구량이 큰 지를 분류하고, 일정 대역폭 사용 요구량을 넘는 RDD들은 near 메모리에 할당하여 수행하여, explicit한 메모리 관리를 통해 얻을 수 있는 최대 성능 향상치를 측정해야 한다. 이를 cache 모드하에서의 어플리케이션 성능과 비교함으로써 기존 cache 모드의 여러가지 penalty로 인한 영향 및 explicit 한 메모리 관리의 필요성 탐색이 선행되어야 한다.
- RDD 단위 대역폭 예측 및 스케줄링 기법 (not yet, future work) 현재 Spark 프레임워크의 경우, RDD를 기본 단위로 하여 DAG execution plan을 결정하는 DAG scheduling 단계와 실제로 stage 및 task set을 구성하여 RDD transformation을 수행하는 task scheduling 단계로 나뉘어 스케줄링 및 실제 연산이 수행되며, 이는 기존 OS 단위 스케줄링 및 일반적인 병렬 프로그램의 스케줄링 방식과 차별점을 가진다. 따라서 이러한 Spark 프레임워크의 스케줄링 특성 및 실행 방식을 반영하여 대역폭 예측 기법을 적용하는 과정이 필요하다. 또한, 기존 메모리 환경과 달리, near-far 메모리 간 확연한 대역폭 성능 차이 및 용량 차이를 가지므로 스케줄링 시 이러한 플랫폼 상의 특성을 반영하는 과정 역시 필수적이다.
성능 측정 결과
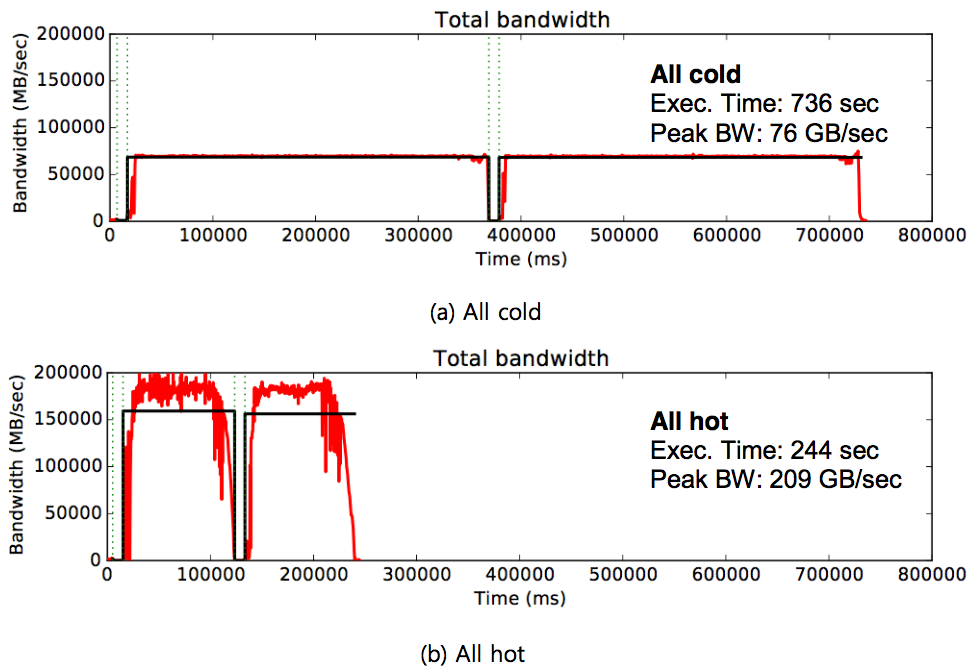
위 그림은 hot/cold 할당 기법 및 MXBeans를 활용한 Spark-JVM communication interface를 적용하였을때의 잠재 성능 향상치를 확인하기 위해, STREAM 벤치마크로 테스트한 결과이다. 모두 far 메모리를 사용하는 all cold 와 모두 near 메모리를 사용하는 all hot 을 비교해 보았을 때, near 메모리의 대역폭을 충분히 사용하는 all hot 구성이 약 3배 정도 빠른 수행 시간을 보이고 있다. 이로써 구현한 JVM 이 의도한 대로 동작하고 있음을 알 수 있다.
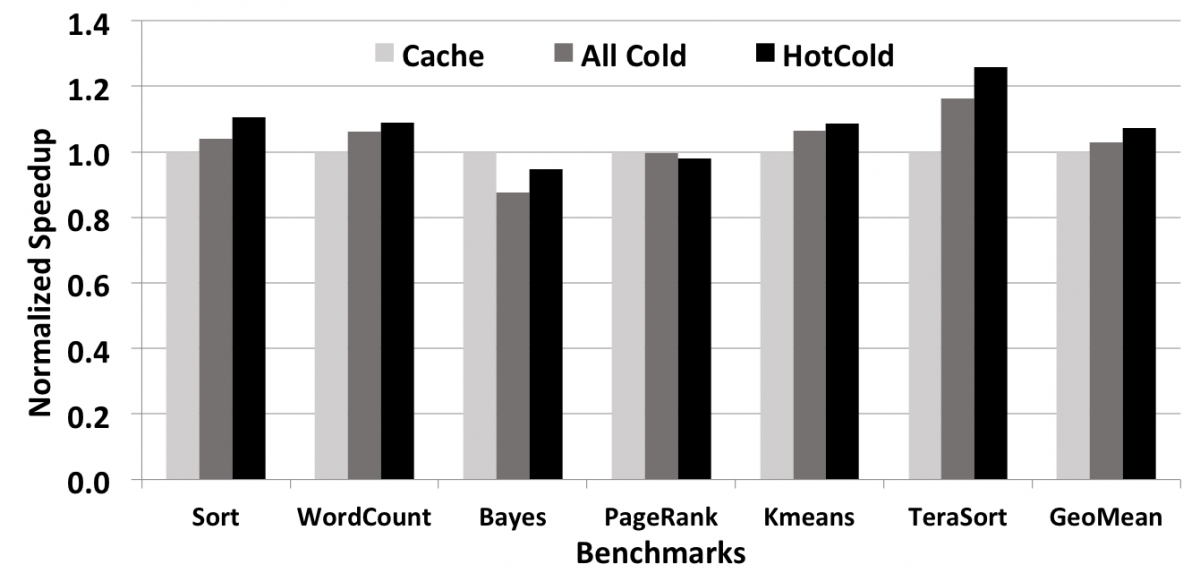
또한 위 그림은 실제 Spark 프레임워크에서의 동작 및 성능 향상을 확인하기 위해서, Intel HiBench의 일부 프로그램 (sort, word count, bases, page rank, kmeans, terasort)을 활용하여 성능을 측정한 결과이다. Spark 프로그램 내에서 phase를 구분하기 위해서 stage 단위로 대역폭을 측정하였으며, hot-cold stage의 비율은 1:1로 조정하였다.
총 6개의 벤치마크 중 4개의 벤치마크에서 hotcold 기법이 cache 모드를 사용했을 때에 비해 나아진 성능을 보였다. terasort 벤치마크에서 최대 20.6%의 수행 시간이 감소하였고, 평균 6.8%의 수행 시간이 감소하였다.
매니코어 환경에서의 딥러닝 응용 성능 병목 분석
배경
최근 딥 러닝 기반 인공지능 기술 성장에 따라, 딥 러닝 기반 응용의 편리한 작성과 안정적 성능 제공을 목적으로 한 TensorFlow, Caffe, Theano, PyTorch 등의 다수의 딥 러닝 프레임워크가 일반적인 환경으로 사용되고 있다. 이러한 딥 러닝 프레임워크 상에서의 응용 성능 개선을 위해서는 딥 러닝 모델 단위의 성능 개선뿐 아니라, 프레임워크 단위의 성능 병목 지점 추출 및 성능 개선이 요구되고 있다.
본 연구에서는 이와 관련하여 매니코어 환경에서의 딥 러닝 프레임워크 및 응용에 대한 성능 최적화 기회 탐색을 위한 성능 병목 분석을 목표로 한다. 이를 위해 본 연구에서는 다양한 딥 러닝 프레임워크 및 매니코어 플랫폼을 기반으로 한 테스트베드 환경을 구축하고, 다양한 성능 요소에 대한 병목 분석을 진행한다. 이러한 성능 병목 분석은 기존 매니코어 환경에서의 성능 개선 요소 추출과 함께 향후 딥 러닝 향 하드웨어 및 새로운 메모리/스토리지 기술 (예: NVDIMM, zSSD, 3D XPoint)등을 목표로 한 최적화에 활용함을 목표로 한다.
실험 환경
- CPU 기반 매니코어 플랫폼 Intel Xeon E5-2699 (Broadwell 아키텍쳐, 2-CPU, 44-core, 코어 당 2 HyperThreading, 55MB L3 cache, 378 GB memory) (이하 Broad-88), Intel Xeon Phi 7210 프로세서 (Knights Landing 아키텍쳐, 64 core, 코어 당 4 HyperThreading, 1 MB L2 cache, 16 GB L3 cache (HBM 기반 MCDRAM, cache mode)) (이하 KNL-256) 를 대상으로 하였다. 기존 GPU의 성능 비교를 위해 Nvidia TITAN Xp (Pascal 아키텍쳐, 12GB GDDR) GPU (이하 GPU-ref) 를 활용하였다.
- 딥러닝 프레임워크 BVLC Caffe 를 기반으로 Intel에서 제공하는 최적화 기법들을 적용한 Intel optimized Caffe 버전을 사용하였다. 해당 버전에서는 BLAS 연산을 위한Intel Math Kernel Library, CPU 병렬화를 위한 OpenMP, Intel 플랫폼 최적화가 적용된 icc 컴파일러 등이 적용되어 있다.
- 딥러닝 모델 및 데이터셋 모델의 크기를 기준으로 다수의 모델을 선정하였다. 현재 선정된 모델 및 데이터 셋 (크기 순 정렬)은 1) LeNet-MNIST, 2) Cuda-convnet – CIFAR10, 3) AlexNet – ImageNet, 4) VGG16-ImageNet 등의 Convolutional Neural Network (CNN) 모델을 실험에 사용하였다.
분석 내용
-
코어 개수 별 성능 확장성
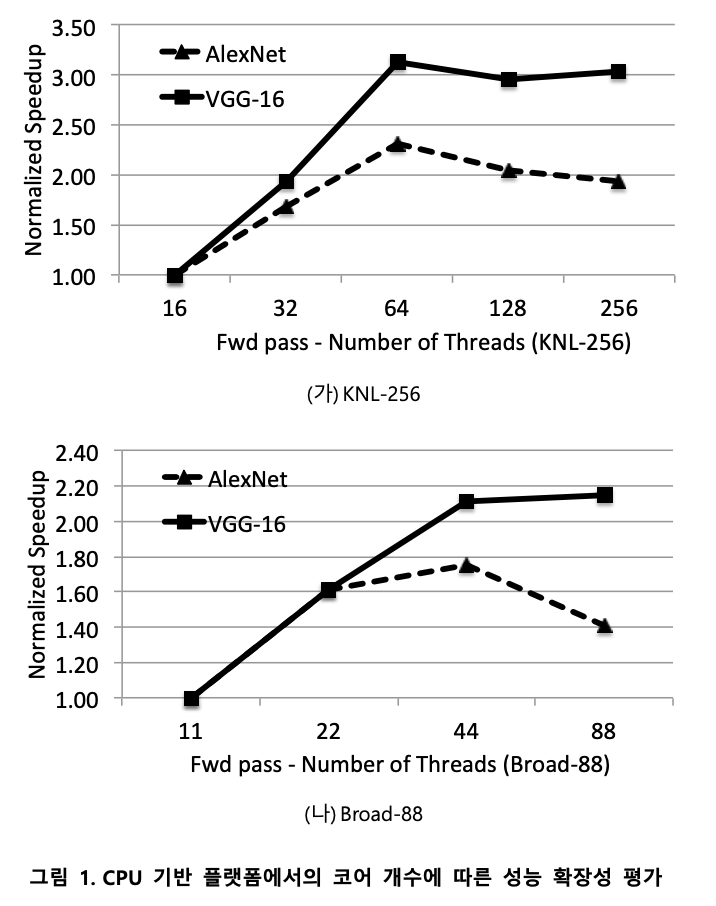
매니코어 플랫폼 환경의 컴퓨팅 자원 활용 정도를 확인하기 위해 확장성 성능 평가를 진행하였다. 그림 1은 CPU 기반 플랫폼(Broad-88, KNL-256)에서 코어 개수에 따른 성능 확장성 평가에 대한 결과이다. 총 2개 플랫폼 및 딥 러닝 모델에 대해 평가한 결과, 모든 환경에서 physical 코어 개수까지는 성능 확장성을 보이지만, HyperThreading이 적용되는 경우, 성능 향상 폭이 더디거나, 오히려 감소하는 것을 확인할 수 있었다.
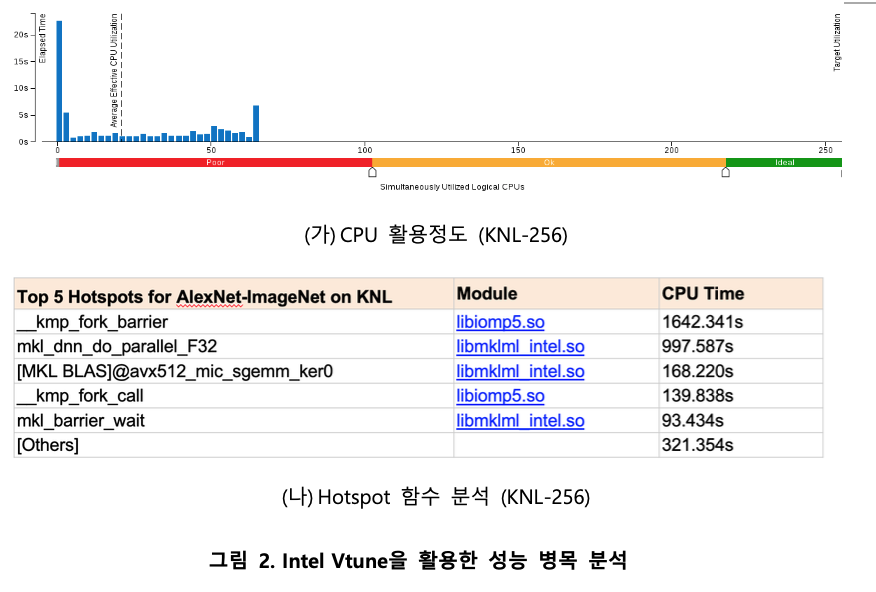
이러한 낮은 성능 확장성은 1) 컴퓨팅 자원의 비효율적인 활용으로 인한 1) 높은 spinning 오버헤드 및 2) BLAS 오버헤드에서 기인하는 것으로 분석된다. 그림 2는 AlexNet-ImageNet 및 KNL-64에서의 CPU utilization 및 HotSpot 분석 결과를 나타낸다. 분석에서 총 256 코어를 이용했을 때 CPU utilization은 평균 20에 그치고 있으며, Hotspot 분석에서는 barrier에서의 heavy spinning으로 인한 CPU time이 대부분을 차지하고 있다. 또한 spinning을 제외한 부분에서는 BLAS GEMM 연산이 주를 이루지만, 상당히 높은 시간을 소요하고 있음을 확인할 수 있다.
-
배치 크기 별 성능 확장성
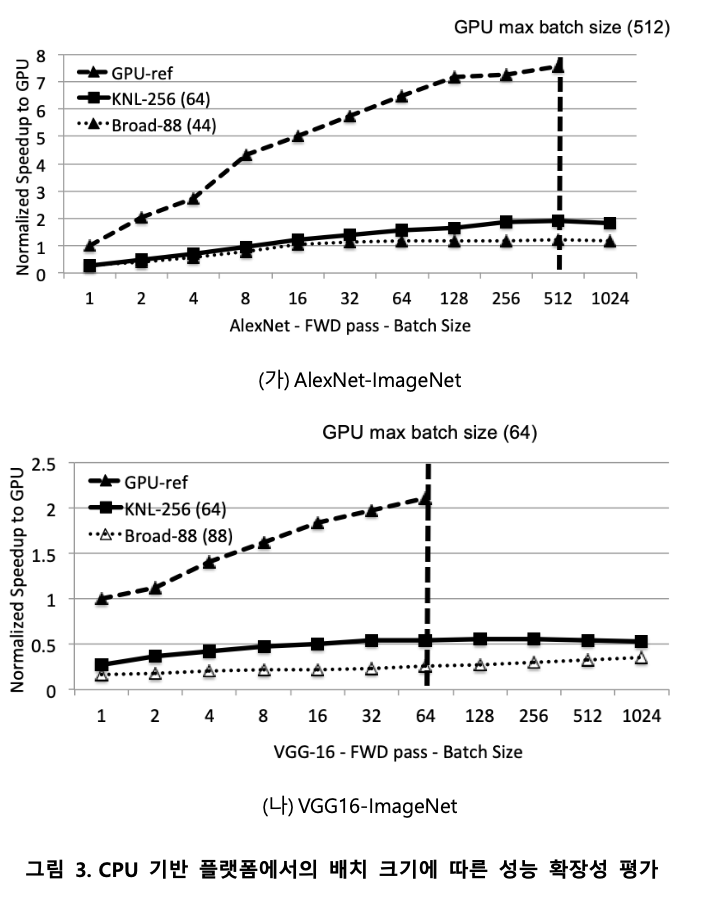
딥 러닝 추론 과정에서의 배치 크기는 메모리 상에 한꺼번에 이미지들을 로드하여 병렬성을 활용하는 단위를 의미한다. 그림 3은 CPU 기반 플랫폼에서의 배치 크기에 따른 성능 확장성 평가 결과이다. 해당 실험에서는 배치 크기를 증가에 따른 성능확장성을 측정하여 1) 다수의 이미지 처리시의 병렬성 활용 정도, 2) GPU 대비 성능 확장성, 3) GPU 대비 가용한 메모리 크기를 확인하였다.
다수의 이미지를 한꺼번에 처리하는 경우, 매니코어 환경은 배치 크기 증가 시 일정 부분 성능 확장성을 보이지만, GPU와 비교했을 때 그 정도가 낮다. GPU에 비해 매니코어 플랫폼이 낮은 병렬성 정도를 보임을 의미하며, 이는 1) GPU에 비해 낮은 잠재 컴퓨팅 자원, 2) 낮은 단계의 소프트웨어 최적화 정도를 가짐을 내포하고 있다. GPU에 비해 낮은 잠재 컴퓨팅 자원으로 인한 영향은 KNL-256 및 Broad-88의 결과에서 간접적으로 확인할 수 있다. KNL-256의 경우 Broad-88에 비해 낮은 CPU 주파수 및 단순한 구조를 가지는 코어로 구성되어 있음에도 높은 성능을 보이며, 이는 다수의 코어로 구성되어 processing element (PE)의 갯수가 Broad-88에 비해 많아 많은 이미지를 한꺼번에 병렬적으로 처리할 수 있기 때문이다.
한편, GPU의 경우, 가용한 메모리 크기가 CPU 환경에 비해 현저히 작으며 (Titan Xp GDDR: 12 GB vs. KNL-256: 192 GB), 이로 인해 증가시킬 수 있는 배치 크기가 제한적임을 확인할 수 있다. GPU에 비해 낮은 성능 확장성에도 불구하고, CPU의 이러한 부분은 실제로 딥 러닝 추론 등에 CPU 기반 플랫폼을 활용하는 동기가 되고 있다. 또한, GPU에 비해 큰 가용 메모리를 활용한 성능 최적화 기법의 기회를 가진다.
-
계층 단위 실행 시간
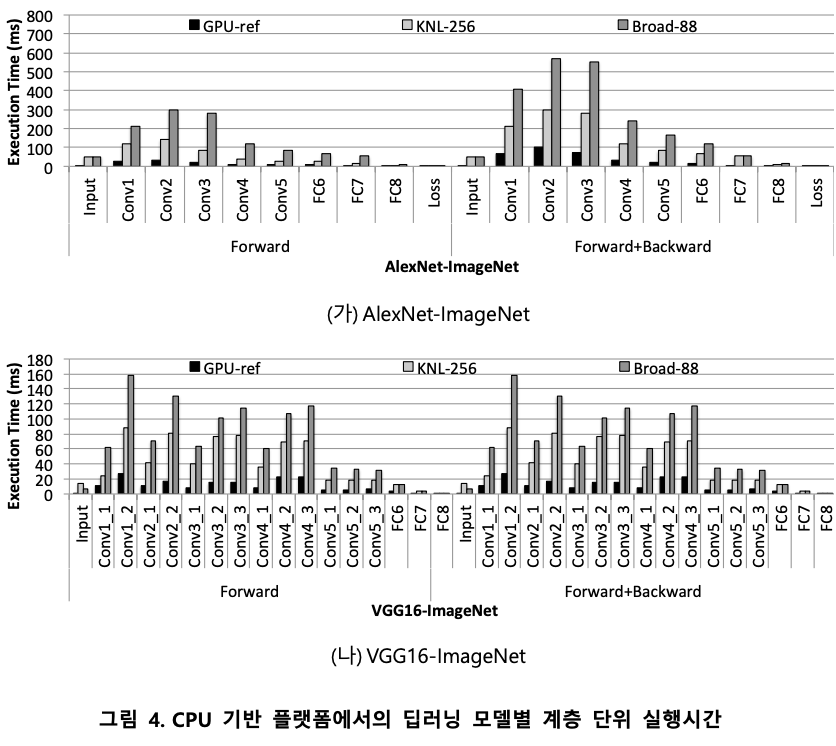
딥 러닝 모델의 경우, 서로 다른 특성을 가진 다수의 계층으로 구성되어 있다. 본 실험에서는 매니코어 및 GPU 환경에서의 계층 별 성능을 추론 및 학습 과정에 대해 측정하였다. 그림 4는 CPU 기반 플랫폼에서의 딥러닝 모델별 계층 단위 실행시간 측정 결과이다. 측정 결과, BLAS 연산이 주가 되는 convolution layer 및 fully-connected layer에서 소요하는 시간이 대부분을 차지하였으며, GPU 대비 성능 차이도 가장 심한 것을 확인할 수 있었다. 향후 최적화 진행 시, 이러한 convolution layer 및 fully connected layer 를 대상으로 한 최적화 기법 고안 및 적용을 주요 목표로 해야함을 제시하고 있다.
결과물
- 논문
- 소프트웨어
- 성능 병목 분석 도구 - Ivy Profiler
- Github: WASP
- 특허
- DVFS를 지원하는 멀티코어 플랫폼에서 병렬 프로그램의 성능 특성 및 최적화 목표를 고려한 전력 할당 최적화 기술 (등록 완료)
- 시연 동영상