스케일러블 파일시스템을 위한 코어 파티셔닝
연구 배경
컴퓨팅 노드에 장착된 코어 수가 증가함에 따라 컴퓨팅 확장성 뿐만 아니라 I/O 성능도 향상될 것으로 예상되었지만, 기존의 운영체제에서는 이러한 확장성을 제공하기 힘들다는 많은 연구가 진행되었다. 특히 I/O 장치의 고성능화를 지원하기 위해 파일 시스템의 병목현상을 분석하고 파일 시스템의 확장성을 향상시키기 위한 노력은 계속되고 있다. 본 연구에서는 NVMe와 같은 다중 I/O 큐를 지원하는 고성능 I/O 장치의 이벤트 핸들러와 내부 소프트웨어 스택을 특정 코어 집합에서 실행할 수 있도록 매니코어 파티셔닝을 제안한다. 매니코어 파티셔닝을 구현하기 위해 I/O 시스템 호출 컨텍스트를 응용 프로세스에서 분리하고 I/O 장치의 시스템 호출 문맥 및 이벤트 핸들러의 코어 친화도를 동적으로 결정한다. 매니코어 파티셔닝을 통해 서로 다른 코어에서 실행되는 많은 프로세스 또는 스레드가 I/O 시스템 호출을 통해 동시에 커널에 진입하고 동일한 커널 내 데이터 구조를 경쟁적으로 접근하면서 발생되는 공유 캐시 오염 및 캐시 일관성 오버헤드를 감소시킴에 따라 더 나은 확장성을 제공할 수 있다.
연구 내용
Scalable 파일 I/O 시스템 호출을 위한 코어 파티셔닝
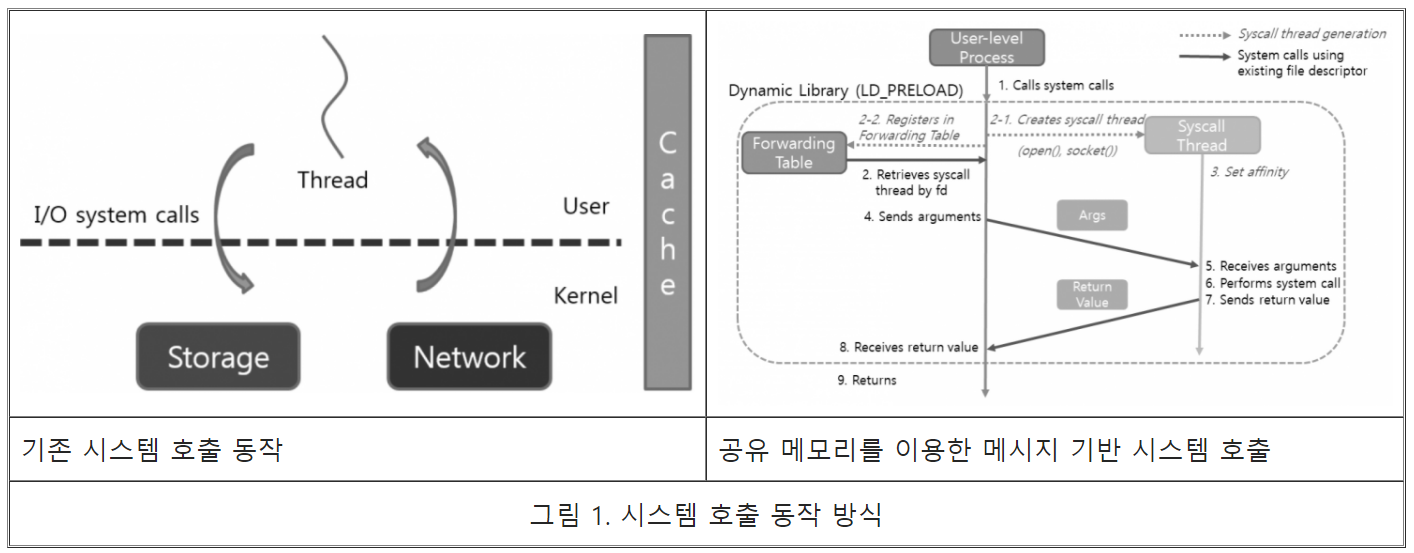
파일 I/O를 위한 메시지 기반 시스템 호출 프레임워크
파일 I/O를 메시지 기반 시스템 호출 프레임워크는 open(), write(), read()와 같은 파일 I/O를 위한 시스템 호출을 지원한다. 응용 프로세스가 파일 I/O를 담당하는 시스템 호출을 호출할 경우 응용 프로세스와 I/O 시스템 호출을 서로 다른 코어에서 실행하기 위해 실제 I/O 시스템 호출을 호출하는 별도의 스레드를 생성한다. 아래 그림과 같이 시스템 호출 스레드는 응용 프로세스가 open()을 호출할 때마다 내부적으로 생성된다. 생성된 시스템 호출 스레드는 동적 코어 친화도에 따라 특정 코어에 할당된다. 응용 프로세스는 I/O 시스템 호출을 직접 호출하는 대신 공유 메모리 영역을 통해 해당 시스템 호출 스레드로 I/O 요청을 전송한다. 응용 프로세스와 시스템 호출 스레드를 바인딩하기 위한 포워딩 테이블에는 각 시스템 호출 스레드에 대한 공유 메모리 채널의 정보를 포함하고 있어 응용 프로세스는 파일 설명자 번호를 기준으로 I/O 요청을 어떤 스레드에 배치해야 하는지 알 수 있다. 요청 결과도 공유 메모리 영역을 통해 반환된다. 또한 각 공유 메모리 영역은 캐시 라인 크기에 맞추어 캐시 효율성을 극대화하면서 캐시 일관성을 위한 트랜잭션 수를 최소화한다. 단일 캐시 라인 크기는 I/O시스템 호출의 매개 변수와 반환 값을 저장하기에 충분하다. 네트워크 I/O 성능 개선을 위한 코어 파티셔닝 프레임워크와 전체적인 구조는 동일하지만 메시지 전달 오버헤드를 감소시키기 위해 공유 메모리를 사용하였다.
성능 실험
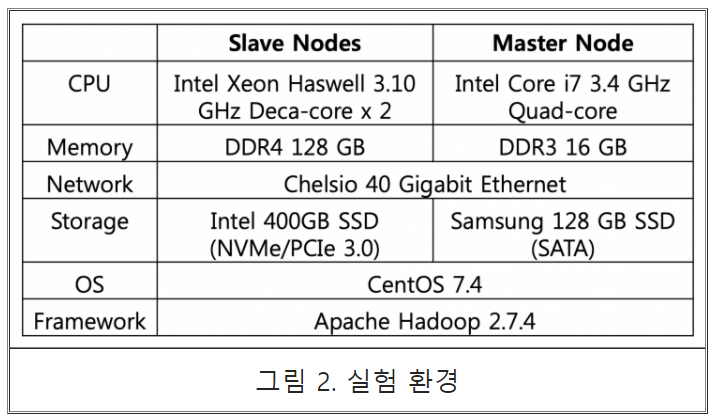
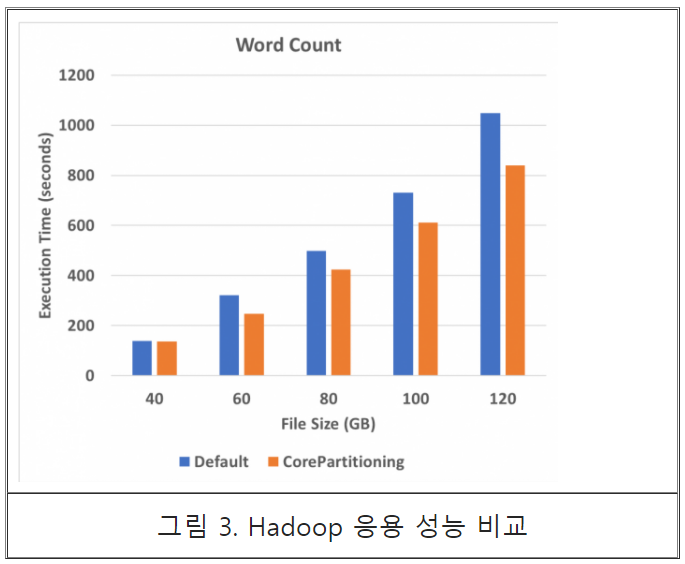
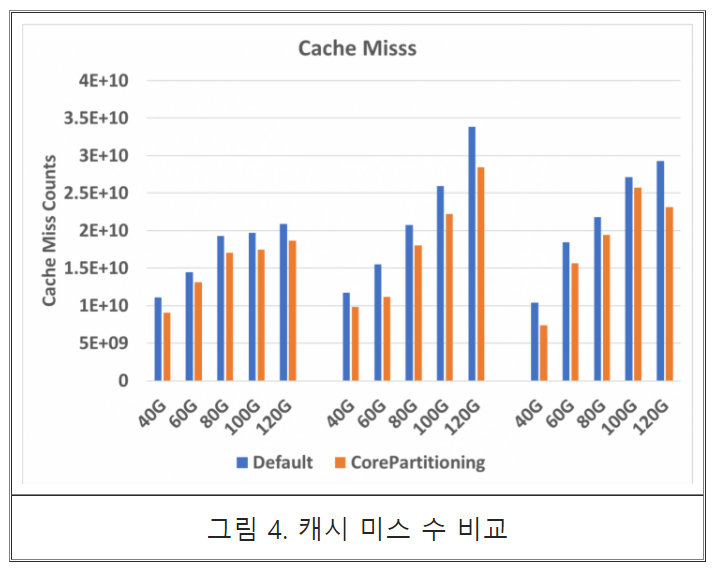
성능실험을 위해 Hadoop 프레임워크가 제공하는 WordCount 응용의 실행 시간을 파일 사이즈를 변경해 가면서 측정 하였다. 그림 2는 실험 환경을 나타낸다. 그림 3에서 볼 수 있듯이 Scalable 파일 I/O 시스템 호출을 위한 코어 파티셔닝은 응용 실행 시간을 최대 20% 감소시킨 것을 관찰할 수 있다. 성능 향상 원인을 분석하기 위해 최하위 레벨 캐시 미스 수를 측정한 결과 그림 3에서 볼 수 있듯이 캐시 오염 감소를 달성할 수 있음을 관찰할 수 있다.
향후 계획
본 연구는 Scalable 파일 I/O 시스템 호출을 위한 코어 파티셔닝을 기반으로 스토리지 I/O 이벤트 처리를 위한 코어 친화도 정책 및 경량 가상화 환경을 위한 코어 친화도 정책에 대해 연구할 계획이다.
연구 결과물
- 논문
- Jooho Kim, Joong-Yeon Cho, and Hyun-Wook Jin, "Application-transparent Scheduling of Socket System Calls on Many-core Systems," In Proc. of ANCS ‘18, pp. 174-176, July 2018.
- 김주호, 조중연, 진현욱, "매니코어 시스템에서 하둡 맵리듀스 환경변수 최적화", 한국정보과학회 2018 한국소프트웨어종합학술대회논문집, 2018년 12월.
- 조중연, 진현욱, "메모리 매핑 기반 MPI 노드 내 통신 프리미티브 성능 비교", 한국정보과학회 2018 한국소프트웨어종합학술대회논문집, 2018년 12월.
- 시연 영상