오토튜너 연구
매니코어 프로세서의 병렬성을 활용하기 위해서는 시스템 프로그램 차원의 지원을 활용하거나 응용 프로그램의 지원을 필요로 한다. 응용 프로그램 내에서 병렬성을 프로그래밍하는 경우에 다양한 최적화 기법을 선택적으로 적용하여 최선의 성능을 보일 수 있다. 딥러닝은 많은 데이터를 입력받아 수많은 파라미터들의 값을 조정하는 학습 과정을 통해 완성되는데 이 학습 과정은 수많은 실수로 이루어진 텐서 연산의 반복으로 병렬화 될 수 있는 부분이 많이 있기 때문에 이를 위해 특화된 프로세서들이 개발되고 있다. GPU가 적극적으로 활용되고 있고 google 의 TPU (Tensor Processing Unit), intel 이 facebook과 함께 개발한 AI chip 등의 개발이 계속되고 있다. 그러나 위와 같은 특수 프로세서들이 제한된 용량의 디바이스 메모리로 시스템 메모리의 데이터를 복사해야 하는 오버헤드가 있는데 반해, 범용 매니코어 프로세서를 사용하는 장점은 대량의 시스템 메모리를 직접 접근할 수 있고 일반 병렬 프로그래밍 모델을 적용할 수 있다는 것이다.
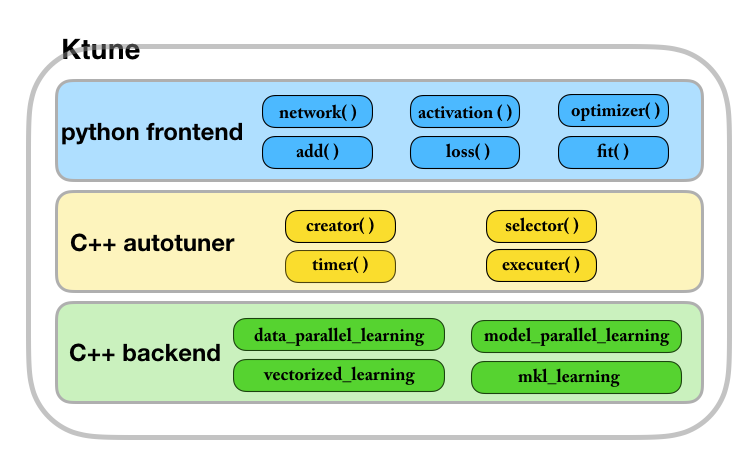
본 연구에서는 딥러닝 학습 알고리즘의 성능 연구에 필요한 소프트웨어 도구로서 Ktune 오토튜너를 제안하고 개발한다. 오토튜너는 그림과 같은 구조로 구성된다. C++ backend 에서 최적화 기법을 적용한 프로그램 모듈들을 라이브러리로 제공하고, frontend 의 python module 을 통하여 딥러닝 모델을 정의하여 fit() 함수를 수행할 때 C++ autotuner 는 creator 를 사용하여 frontend에서 정의된 모델을 구성하고 executer 를 통해 backend에서 제공하는 최적화 모듈들을 수행하여 timer 로 성능을 비교한 후 selector 를 통하여 최적의 코드를 선정하여 학습을 진행한다.
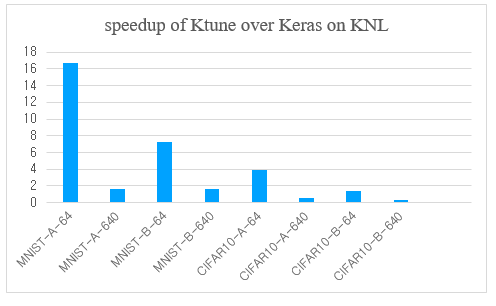
딥러닝의 구현에 가장 널리 쓰이고 있는 소프트웨어 도구인 TensorFlow 를 이용한 딥러닝 모델 구현을 모듈화한 패키지로 Keras 가 제공되는데 단순한 딥러닝 모델에 대한 Ktune 학습 알고리즘의 최적화 결과를 Keras 로 구현된 학습 결과와 비교하였을 때 속도 향상을 비교하였다.
연구 결과물
- 시연 영상